







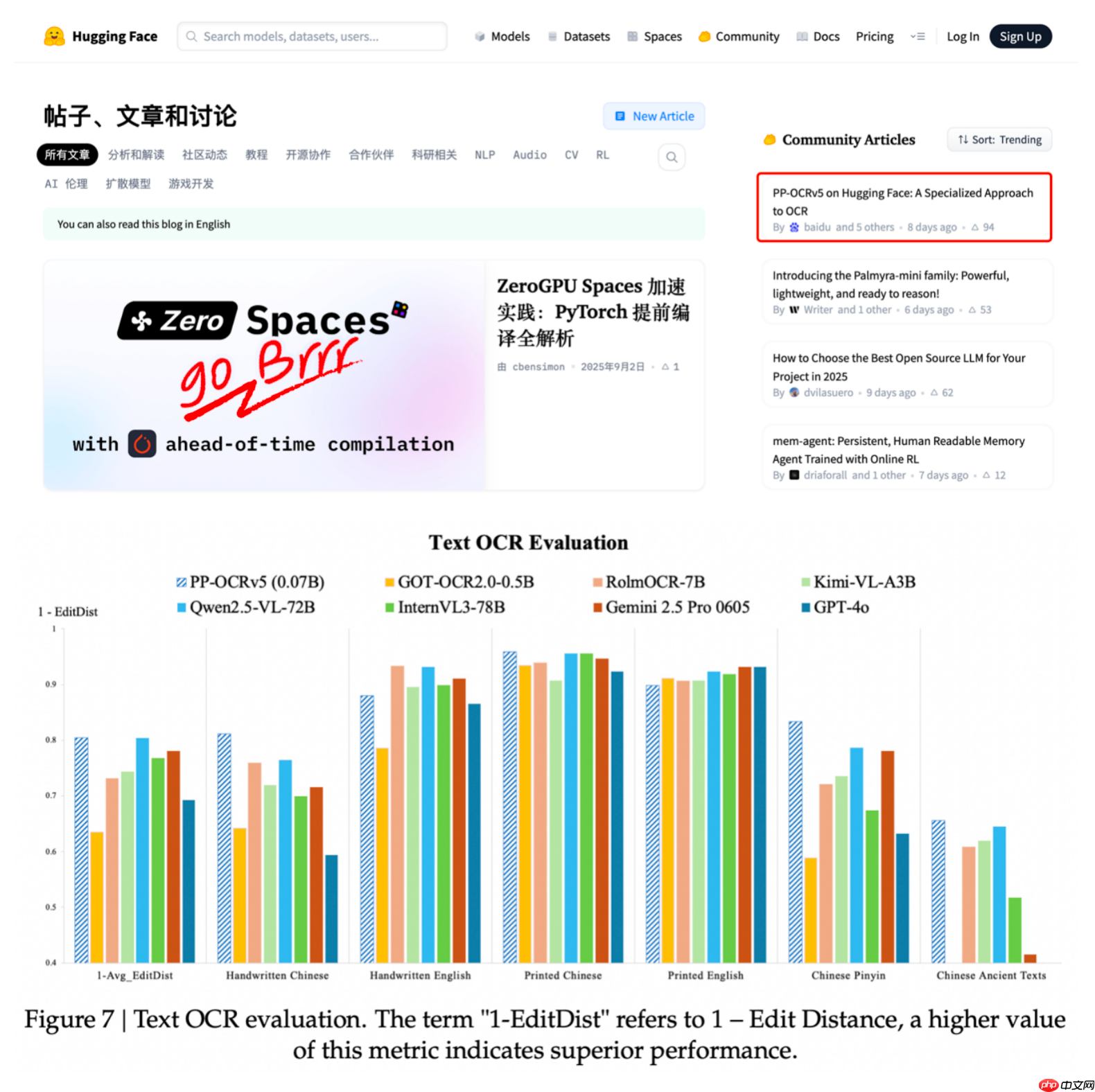
近日,百度通过其海外官方账号发布了全新的轻量级文字识别模型 pp-ocrv5。该模型参数量仅为0.07b,在仅千分之一的参数规模下,实现了与拥有700亿参数的大模型相当的ocr识别精度。在多个ocr应用场景的测试中,pp-ocrv5的表现优于gpt-4o、qwen2.5-vl-72b等大型通用视觉模型。目前,飞桨团队发布的相关技术博客已连续七天位居hugging face博客热度榜首位,引发开发者社区的高度关注。
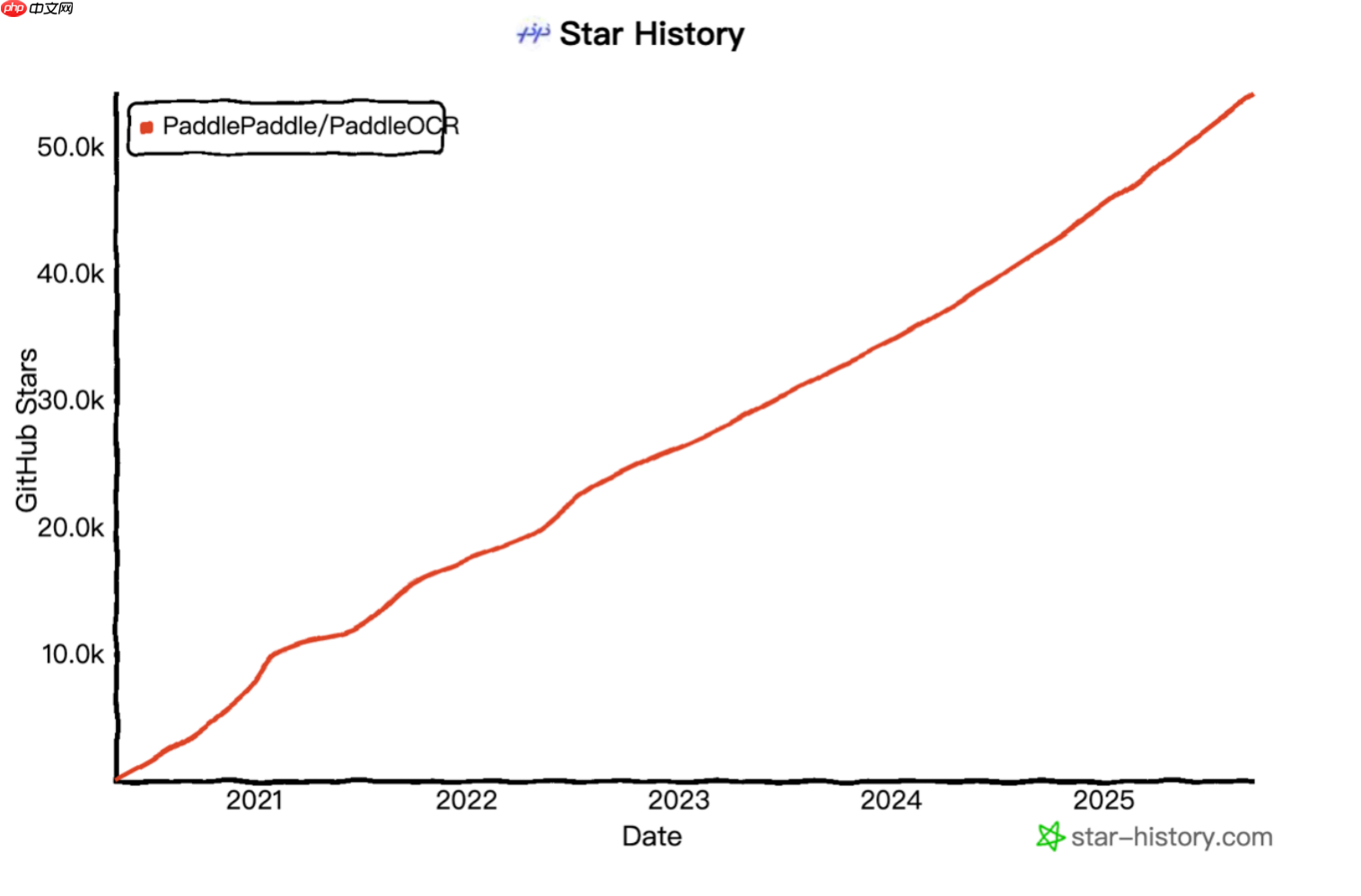
据悉,2025年5月,飞桨团队正式推出PaddleOCR 3.0版本,构建了三大核心能力:文字识别方案PP-OCRv5、通用文档解析方案PP-StructureV3,以及原生集成文心大模型4.5的智能文档理解方案PP-ChatOCRv4。自2020年开源以来,PaddleOCR全球累计下载量已突破900万次,被超过5,900个开源项目直接或间接引用,成为GitHub上唯一一个Star数突破50,000的中国OCR开源项目。

源码地址:点击下载




























