








在日常使用中,若需从图片中提取文字信息,采用OCR(光学字符识别)技术是效率较高的方式。本文将指导如何利用Adobe Acrobat Pro软件,精准识别图片中的韩文内容,便于用户迅速获取所需文本。
首先,确保所使用的图片具有较高分辨率,有助于提升识别的准确性;同时建议将图片保存为通用格式,例如JPG、JPEG、PNG或BMP,以便于后续处理和导入。
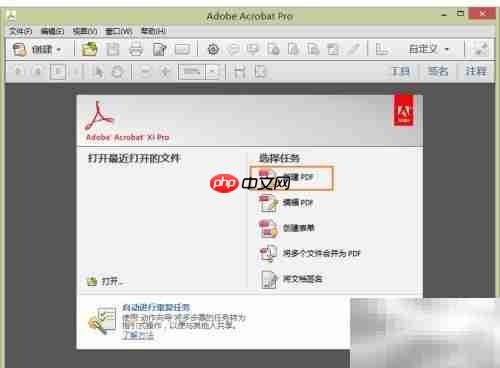
接着打开Adobe Acrobat Pro,选择“创建PDF”功能。如果尚未安装该软件,可通过官方渠道下载安装包并完成安装。
随后,在弹出的窗口中选中需要识别的图片文件,系统会自动将其转换为PDF格式。
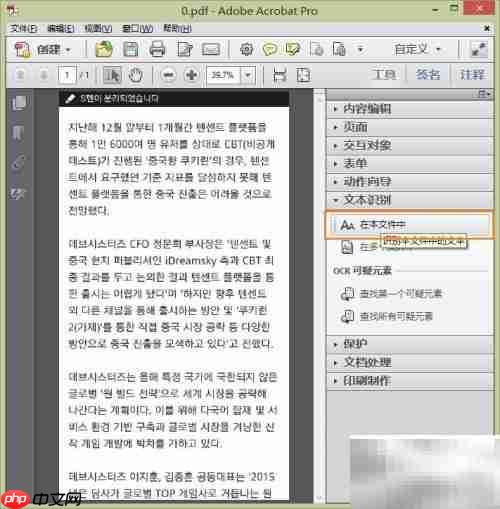
然后依次点击菜单中的“工具”→“文本识别”→“在本文件中”。
纯js带缩略图的图片图集幻灯片特效
下载
这是一款使用纯js来制作的带缩略图的图片图集幻灯片特效。该图片幻灯片特效功能强大,可以直接使用鼠标进行前后导航,也可以通过缩略图来切换图片,还可以进入缩略图预览模式,查看所有的图片。 使用方法 在页面中引入base.css和gallery.css样式文件,以及BX.1.0.1.U.js、gallery.js和piclist.js文件。
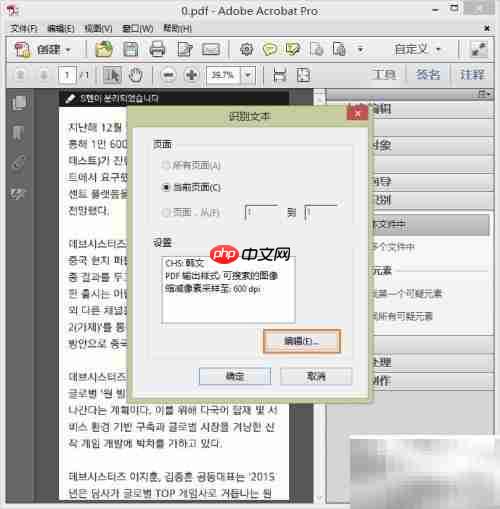
点击出现对话框中的“编辑”按钮,进入设置界面。

将OCR语言选项调整为“韩文”,其他参数可根据实际图像内容进行配置,设置完成后点击“确定”开始识别。
识别过程结束后,即可对文档中的文字进行复制操作。
最后,将提取出的文字粘贴至记事本或其他文本编辑器中,便可直接使用。




























