
在当今数字化时代,pdf文件的应用极为普遍,其中所包含的图片与表格信息提取需求也不断上升。那么,如何高效地识别pdf中的图片和表格内容呢?
目前市场上有许多专用于处理PDF文档的工具,具备出色的图片与表格识别能力。例如Adobe Acrobat DC,不仅能够精准识别文本内容,还能对嵌入的图片和表格进行有效解析。借助该软件,用户可以方便地提取表格数据,并对图像内容进行基础分析。同时,福昕PDF阅读器在识别PDF中的图表方面同样表现优异,支持将复杂表格快速转换为可编辑的Excel格式,便于后续操作;对于图片部分,也能提供清晰展示及初步的内容识别功能。

互联网上提供了大量在线服务,可用于处理PDF中的图像与表格内容。以Smallpdf为代表的在线平台,集成了多种PDF处理功能,在识别表格方面表现出色。用户只需上传文件,系统便可自动识别其中的表格结构,并允许导出为Excel等常用格式,极大提升了数据整理效率。针对图片内容,这些工具通常结合OCR技术,尝试提取图像中包含的文字信息。虽然识别精度会受到图像质量、排版复杂度等因素影响,但其操作简便、无需安装的特点,使其成为轻量级场景下的理想选择。
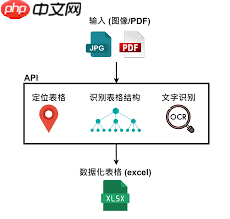
OCR(光学字符识别)技术是实现PDF中图片与表格内容提取的核心手段。大多数专业的PDF处理工具和在线服务都依赖于OCR引擎来完成文字与结构的还原。通过分析扫描件或嵌入图像中的文字区域,OCR可将其转化为可编辑、可搜索的文本格式。对于表格而言,先进的OCR系统不仅能识别单元格内的文字,还能重构行列布局,从而实现高保真的数据提取,显著提高文档处理的自动化水平。
在进行PDF图片与表格识别时,需关注以下几点:
总而言之,无论是利用功能强大的专业软件、便捷高效的在线工具,还是依托先进的OCR技术,合理选择并综合运用多种方式,均能实现对PDF中图片与表格内容的高效识别。掌握这些方法,将极大提升日常办公、数据分析以及学术研究的工作效率。
以上就是如何识别PDF图片中的表格的详细内容,更多请关注php中文网其它相关文章!

解决渣网、解决锁区、快速下载数据、时刻追新游,现在下载,即刻拥有流畅网络。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 334
334



















