
近日,中国科学院自动化研究所李国齐与徐波领衔的科研团队正式推出全球首个大规模类脑脉冲大模型——spikingbrain1.0。该模型在处理超长文本方面表现卓越,能够以超过现有主流 transformer 模型百余倍的速度完成400万 token 的文本处理任务,同时仅需其2%的训练数据量。
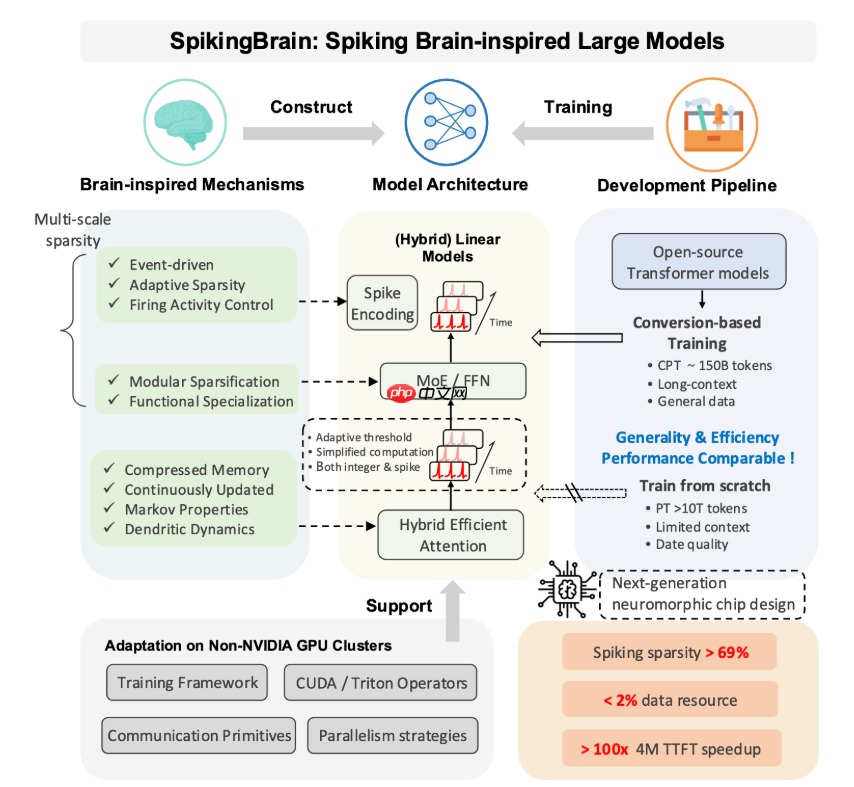
目前广泛应用的大语言模型,如GPT系列,大多依赖于Transformer架构。尽管其自注意力机制具备强大的语义捕捉能力,但随之而来的高计算复杂度成为显著瓶颈。当输入文本长度增加时,计算开销呈平方级增长,导致处理长文档时效率低下、能耗剧增,严重制约了AI在法律文件、学术论文或长篇文学作品等场景中的应用潜力。
为突破这一限制,研究团队转向自然界最高效的智能系统——人脑。大脑拥有约千亿神经元,却仅消耗约20瓦的功率。受此启发,团队提出“基于内生复杂性”的设计思想,致力于提升单个计算单元的智能化水平与运行效率。
SpikingBrain 模型模拟了生物神经元的脉冲放电行为,推出了两个版本:SpikingBrain-7B(70亿参数)和 SpikingBrain-76B(760亿参数)。首先,模型摒弃了传统Transformer中计算代价高昂的二次复杂度自注意力机制,转而采用创新的“混合线性注意力架构”,将整体计算复杂度压缩至线性级别 O(n),极大提升了对长序列的处理速度。
其次,模型引入“自适应阈值脉冲神经元”机制,神经元是否触发脉冲取决于输入信号的累积强度,并通过动态调节激活阈值,确保网络始终处于高效工作状态。这种事件驱动的计算方式大幅减少了无效运算,实现了高达69.15%的计算稀疏度,显著降低能耗。
更进一步,研究团队研发了一套先进的模型转换技术,可将已有的预训练Transformer模型无缝迁移至SpikingBrain架构,有效规避从零训练的巨大成本。所有相关代码、技术文档均已开源,发布于GitHub及魔搭社区,面向全球开发者与研究人员开放共享。
SpikingBrain1.0的诞生,标志着类脑计算在大模型领域的重大进展,不仅在性能与能效上实现双重突破,也为通向通用人工智能开辟了全新的技术路径。
GitHub:
https://www.php.cn/link/987abbb401850a3f9d10dc85a625c0c9
划重点:? SpikingBrain 模型处理长文本速度达主流模型百倍以上,训练所需数据量仅为2%。? 采用混合线性注意力架构,将计算复杂度由O(n²)降至O(n),大幅提升效率。? 自适应阈值脉冲神经元实现事件驱动计算,能耗更低,计算稀疏度达69.15%。
以上就是中科院推出类脑大模型 SpikingBrain:以2% 数据实现百倍速度突破的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 175
175
























