







Prim算法适合稠密图,从起始点扩展,用优先队列优化实现O((V+E)logV);Kruskal算法适合稀疏图,按边权排序并用并查集避免环,实现O(E log E)。

在C++中实现最小生成树(Minimum Spanning Tree, MST)主要有两种经典算法:Prim算法和Kruskal算法。它们适用于不同场景,下面分别介绍其实现方法和适用情况。
Prim算法实现最小生成树
Prim算法适合稠密图(边数较多),基于贪心策略,从一个起始点开始逐步扩展生成树。
核心思想: 维护一个已加入生成树的顶点集合,每次选择连接该集合与外部顶点的最小权边。
实现方式: 使用优先队列(堆)优化可提升效率。
立即学习“C++免费学习笔记(深入)”;
- 初始化距离数组dist[]为无穷大,dist[0] = 0
- 使用bool数组标记顶点是否已加入MST
- 用优先队列存储{距离, 顶点},每次取出最小距离顶点
- 更新其邻接点的距离值
时间复杂度:O((V + E) log V),适合邻接表存储的图。
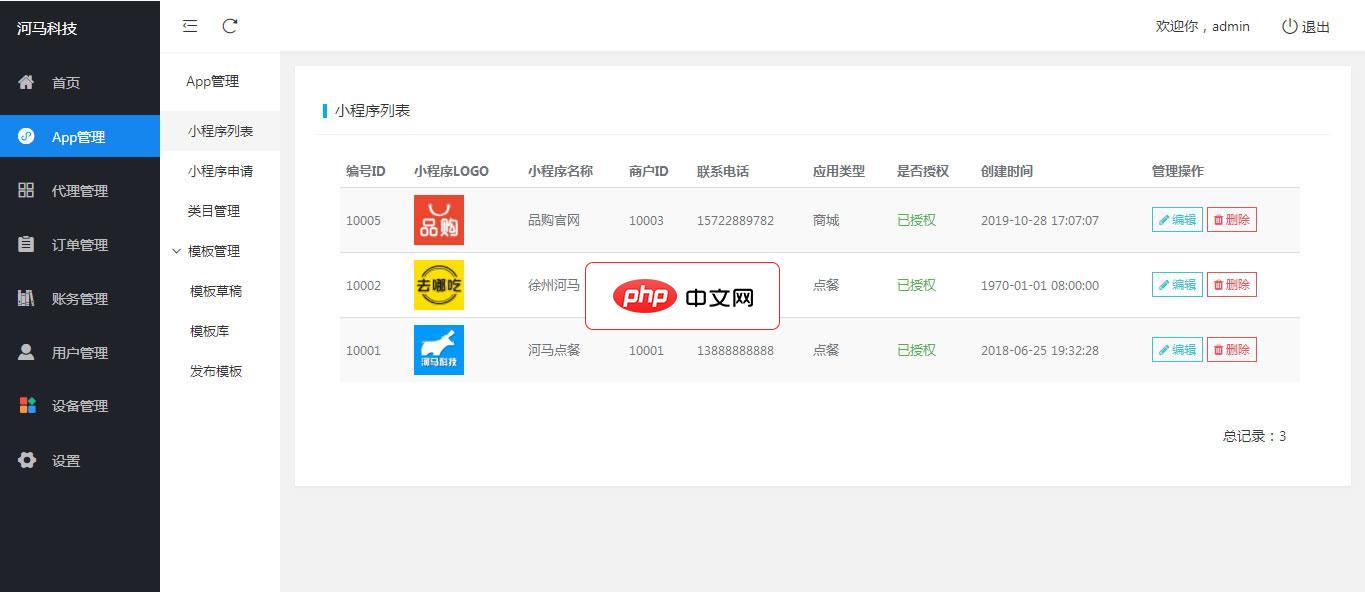
微信小程序公众号SaaS管理系统
下载
微信小程序公众号SaaS管理系统是一款完全开源的微信第三方管理系统,为中小企业提供最佳的小程序集中管理解决方案。可实现小程序的快速免审核注册(免300元审核费),可批量发布小程序模板,同步升级版本等功能。基础版本提供商城和扫码点餐两种小程序模板。商户端可以实现小程序页面模块化设计和自动生成小程序源代码并直接发布。
Kruskal算法实现最小生成树
Kruskal算法适合稀疏图(边较少),按边权从小到大排序,逐个加入不形成环的边。
核心思想: 将所有边排序,利用并查集判断是否会产生环。
- 将图中所有边按权重升序排列
- 初始化并查集,每个顶点自成一个集合
- 遍历每条边,若两端点不在同一集合,则加入MST,并合并集合
- 直到选中V-1条边为止
时间复杂度:O(E log E),主要消耗在排序上。
代码实现要点
实际编码时需注意以下几点:
- 图可用vector
air
>的数组(邻接表)或边列表存储 - Prim中优先队列用greater实现小根堆:priority_queue
, vector<...>, greater<...>> - Kruskal中并查集需实现find和union操作,建议路径压缩+按秩合并
- 边结构体可定义为struct Edge { int u, v, w; };
根据输入规模选择合适的数据结构能显著提升性能。
基本上就这些。Prim更适合点少边多的情况,Kruskal逻辑更清晰易实现。选哪种取决于具体问题特征。



























