
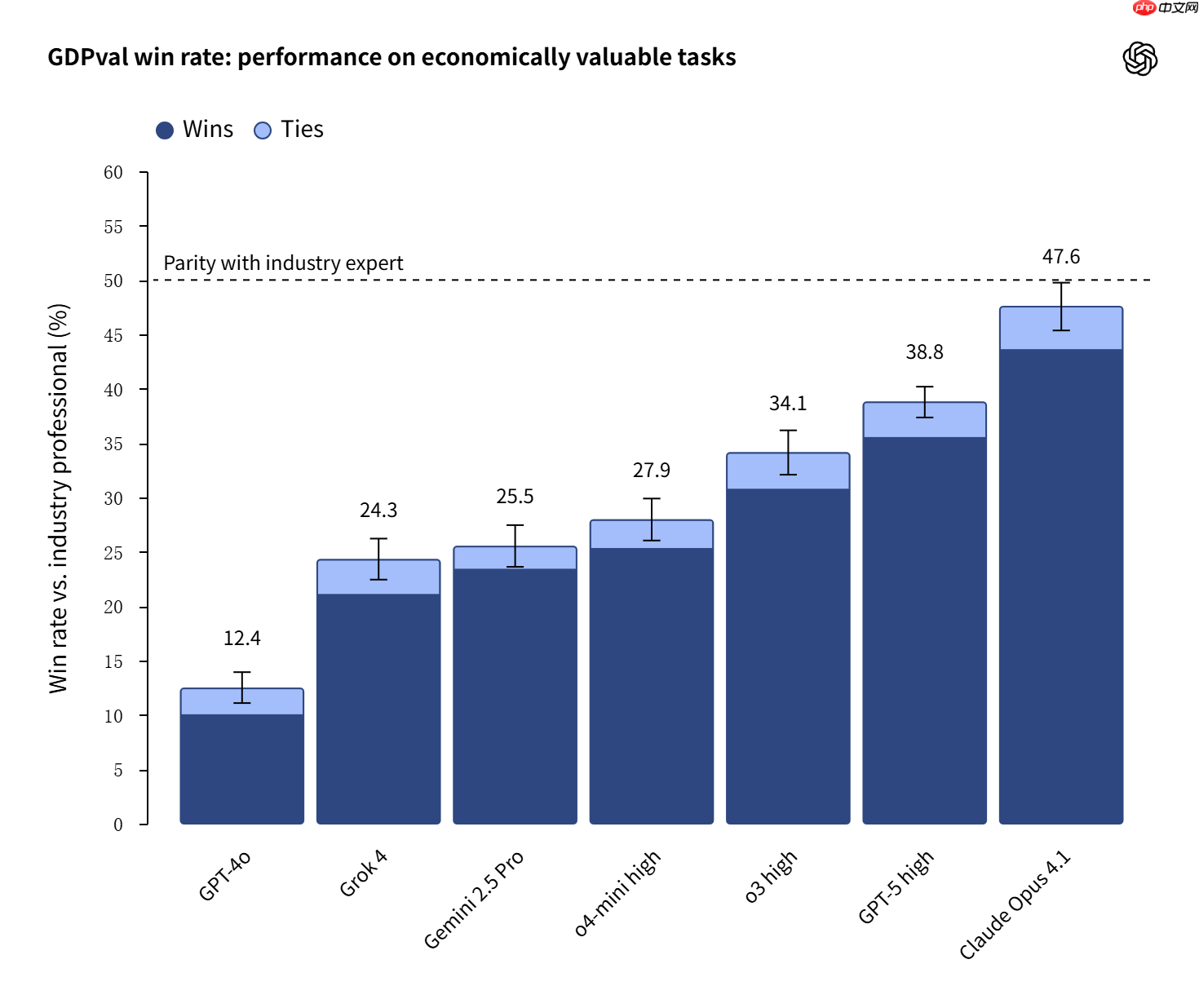
OpenAI近日推出了一项全新的基准测试GDPval,旨在衡量其AI模型在实际经济价值创造任务中与各行业专业人士的表现对比。这一测试是OpenAI探索通用人工智能(AGI)发展路径中的关键一步,重点评估AI系统在真实职业场景中替代或辅助人类工作的潜力。
根据测试结果,OpenAI最新的GPT-5模型以及Anthropic公司推出的Claude Opus 4.1,在多项任务中已接近甚至达到行业专家水平。尽管如此,OpenAI强调,当前版本的测试仍处于初步阶段,并不能全面反映现实工作中复杂的互动与决策过程。
GDPval聚焦于美国GDP贡献最大的九个行业,涵盖医疗、金融、制造业和公共管理等领域,共涉及44种职业,如软件工程师、护士、记者等。测试的核心方法是让资深从业者对AI生成的内容与同行完成的工作进行盲评,判断哪一方质量更优。
以一项典型任务为例:投资银行专家被要求针对“最后一公里配送”领域撰写竞争格局分析报告,随后该报告将与AI生成的版本进行对比评分。最终,OpenAI计算出AI模型在所有职业任务中“胜出或持平”人类专家的比例。
数据显示,高算力版本的GPT-5(GPT-5-high)在40.6%的任务中表现不逊于人类专家;而Claude Opus 4.1则在49%的任务中达到同等或更高水准,暂时领先于GPT-5。对此,OpenAI分析认为,Claude得分较高部分归因于其输出内容更具视觉吸引力,例如图表设计更清晰美观,而非整体推理能力更强。
值得注意的是,目前GDPval-v0仅评估了“撰写专业报告”这一单一工作形式,而现实中大多数岗位包含沟通、协作、应急处理等多维度任务。因此,该测试尚未覆盖完整的职业职能。OpenAI表示,未来计划扩展测试范围,纳入更多交互式任务和实际工作流程,以提升评估的全面性与准确性。
尽管存在局限,OpenAI仍视GDPval为衡量AI进步的重要指标。公司首席经济学家Aaron Chatterji指出,测试结果表明AI已经开始在某些专业领域承担实质性工作,帮助人类提升效率。“当模型能在特定任务上表现出色时,人们就可以把重复性工作交给AI,转而专注于更具创造性或战略性的职责。”他说。
OpenAI评估团队负责人Tejal Patwardhan也表达了乐观态度。她提到,约15个月前发布的GPT-4o在同类测试中仅获得13.7%的胜率或持平率,而GPT-5的表现已接近其三倍。“这种增长速度令人振奋,我们有理由相信这一趋势将持续下去。”
以上就是OpenAI 最新测试:GPT-5 与 Claude 在部分工作中可媲美人类专家的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 175
175



















