







不同行业采用人工智能的速度取决于数据科学家生产力的最大化。nvidia每月发布优化后的ngc容器,为深度学习框架和库提供更高的性能,帮助科学家充分发挥其潜力。英伟达持续投资于完整的数据科学栈,包括gpu架构、系统和软件栈。这种整体方法为深度学习模型训练提供了最佳性能,nvidia在mlperf的六个基准测试中获胜,这是首个全行业的ai基准测试。nvidia在最近几年推出了几代新的gpu架构,最终在volta和图灵gpu上实现了张量核心架构,其中包括对混合精度计算的原生支持。nvidia在mxnet和pytorch框架上完成了这些记录,展示了nvidia平台的多功能性。
优化的框架MXNet
这个最新版本大幅提升了训练深度学习模型的性能,在这种模型中,GPU的训练性能在各种批处理大小中进行优化是至关重要的。研究表明,在最终训练精度开始下降之前,所有处理器的总训练批大小是有限的。因此,当扩展到大量GPU时,添加更多GPU会在达到总批处理大小限制后降低每个GPU处理的批处理大小。因此,我们对18.11 NGC容器中的MXNet框架进行了改进,以优化各种训练批处理大小的性能,特别是小批处理,而不仅仅是大批处理:
随着批处理大小的减小,与CPU同步每个训练迭代的开销会增加。以前,MXNet框架在每次操作后都同步GPU和CPU。当对每个GPU进行小批处理的训练时,这种重复同步的开销会对性能产生负面影响。我们改进了MXNet,以便在与CPU同步之前积极地将多个连续的GPU操作组合在一起,从而减少这种开销。我们引入了新的融合运算符,如batchnorm_relu和batchnorm_add_relu,它们消除了对GPU内存的不必要往返。这可以通过在执行批处理规范化的同一内核中免费执行简单的操作(如elementwise Add或ReLU)来提高性能,而不需要额外的内存传输。对于大多数用于图像任务的现代卷积网络架构来说,这些特性尤其有用。以前,SGD优化器更新步骤调用单独的内核来更新每个层的参数。新的18.11容器将多层的SGD更新聚合到单个GPU内核中,以减少开销。当使用Horovod运行MXNet进行多GPU和多节点训练时,MXNet运行时将自动应用此优化。通过对MXNet的这些改进,英伟达实现了世界上最快的解决方案时间,ResNet50 v1.5在MLPerf上运行6.3分钟。这些优化使得在使用18.11 MXNet容器在单个Tesla V100 GPU上使用张量核心混合精度在批量大小为32的批量训练ResNet-50时,吞吐量为1060张图像/秒,而使用18.09 MXNet容器时为660张图像/秒。
我们与Amazon和MXNet开发社区紧密合作,集成了流行的Horovod通信库,以提高在大量GPU上运行时的性能。Horovod库使用NVIDIA Collective Communications library (NCCL),它集成了allreduce方法来处理分布式参数。这消除了本机MXNet分布式kvstore方法的性能瓶颈。
我们目前正在将我们的改进合并到上游的MXNet和Horovod存储库中,以便他们的用户社区能够从这些改进中受益。
TensorFlow18.11 TensorFlow NGC容器包含TensorFlow 1.12的最新版本。这为实验性XLA编译器支持的GPU性能提供了重大改进。谷歌在其最近的博客中概述了XLA,包括如何启用它的说明。XLA通过将多个操作融合到一个GPU内核中,消除了对多个内存传输的需求,从而显著提高了性能,从而实现了显著的速度提升。XLA编译器目前还处于试验阶段,谷歌博客文章中列出了一些注意事项。然而,在谷歌的GPU内部模型上,性能的提高有望达到3倍。
此外,18.11 NGC Tensorflow容器集成了最新的TensorRT 5.0.2,使数据科学家能够轻松部署经过训练的模型,并优化推理性能。TensorRT解决了推理性能的特定挑战。它以小批处理大小和低延迟高效地执行,直到批处理大小为1。TensorRT 5.0.2支持低精度数据类型,如16位浮点数或8位整数。
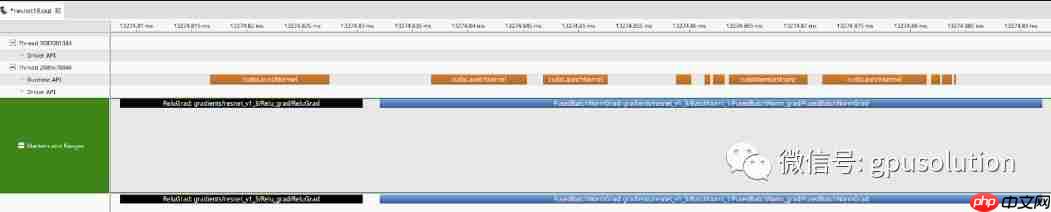
在相关的注释中,NVIDIA为分析器提供了对CUDA应用程序性能的强大洞察。然而,尽管这些概要文件提供了大量关于应用程序底层性能的数据,但通常很难为TensorFlow用户解释这些数据。这是因为概要文件没有将其输出与TensorFlow用户构建的原始图形关联起来。我们增强了TensorFlow的图形执行器(使用NVIDIA profiler NVTX扩展),将标记发送到使用CUDA profiler(如nvprof)收集的配置文件中,从而简化了性能分析。
这些标记显示每个图操作符所花费的时间范围,高级用户可以使用它们轻松地识别计算内核及其相关的TensorFlow层。以前,配置文件只显示内核启动和主机/设备内存操作(运行时API行)。现在,TensorFlow将标记添加到配置文件中,这些标记具有与TensorFlow图相关的有意义的名称,如图1所示。这允许用户将GPU执行概要事件映射到模型图中的特定节点。
 PyTorchNVIDIA与PyTorch开发社区紧密合作,不断提高在Volta张量核心GPU上训练深度学习模型的性能。Apex是一套轻量级的PyTorch扩展,由英伟达维护以加速训练。目前正在对这些扩展进行评估,以便直接合并到主PyTorch存储库中。然而,PyTorch NGC容器是由Apex实用程序预先构建的,因此数据科学家和研究人员可以轻松地开始使用它们。在这个博客中了解关于Apex功能的更多信息。除了Apex最初包含的自动混合精度实用程序和分布式培训包装器之外,我们最近还添加了一些面向性能的实用程序。
PyTorchNVIDIA与PyTorch开发社区紧密合作,不断提高在Volta张量核心GPU上训练深度学习模型的性能。Apex是一套轻量级的PyTorch扩展,由英伟达维护以加速训练。目前正在对这些扩展进行评估,以便直接合并到主PyTorch存储库中。然而,PyTorch NGC容器是由Apex实用程序预先构建的,因此数据科学家和研究人员可以轻松地开始使用它们。在这个博客中了解关于Apex功能的更多信息。除了Apex最初包含的自动混合精度实用程序和分布式培训包装器之外,我们最近还添加了一些面向性能的实用程序。
首先,我们添加了Adam优化器的新融合实现。现有的默认PyTorch实现需要多次进出GPU设备内存的冗余通道。这些冗余传递会产生巨大的开销,特别是在以数据并行方式跨多个GPU扩展培训时。Apex中的融合Adam优化器消除了这些冗余通道,提高了性能。例如,使用融合的Apex实现的变压器网络的NVIDIA优化版本比PyTorch中的现有实现提供了端到端培训加速5%到7%。对于谷歌神经机器翻译(GNMT)的优化版本,观察到的端到端加速从6%到45%不等(对于小批量)。
接下来,我们添加了层规范化的优化实现。对于同一个变压器网络,Apex的层归一化在训练性能上提供了4%的端到端加速。
最后对分布式数据并行包装器进行了扩充,用于多GPU和多节点训练。这包括显著的底层性能调优,以及新的面向用户的选项,以提高性能和准确性。一个例子是“delay_allreduce”选项。这个选项缓冲所有要在GPU中累积的所有层的梯度,然后在完成向后传递后将它们链接在一起。
虽然这个选项忽略了将已经计算的梯度与其他模型层的梯度计算重叠的机会,但是在使用持久内核实现的情况下,它可以提高性能,包括批处理规范化和某些cuDNN RNNs。“delay_allreduce”选项以及其他面向用户的选项的详细信息可以在Apex文档中找到。

性能库cuDNN最新版本的cuDNN 7.4.1包含了NHWC数据布局、持久RNN数据梯度计算、跨区卷积激活梯度计算以及cudnnget()集合API中改进的启发式的显著性能改进。
提高Volta张量核性能的一个关键是减少训练模型时所需的张量置换的数量,如前一篇博文所述。张量核卷积的自然张量数据布局是NHWC布局。在cuDNN的最后几个版本中,我们还为一系列内存绑定操作(如添加张量、op张量、激活、平均池和批处理规范化)添加了操作NHWC数据布局的高度优化的内核。这些都可以在最新的cuDNN 7.4.1版本中获得。
这些新实现支持更有效的内存访问,并且在许多典型用例中可以接近内存带宽峰值。此外,新的扩展批处理规范化API还支持可选的融合元素添加激活,节省了与全局内存的多次往返,显著提高了性能。这些融合操作将加速网络的批量规范化和跳过连接的训练。这包括大多数现代图像网络,用于分类、检测、分割等任务。
例如,在DGX-1V、8 Tesla V100 GPU上训练SSD网络(带有ResNet-34骨干)时,使用cuDNN新的NHWC和融合批处理规范化支持,与使用NCHW数据布局运行且没有融合批处理规范化相比,性能提高了20%以上。
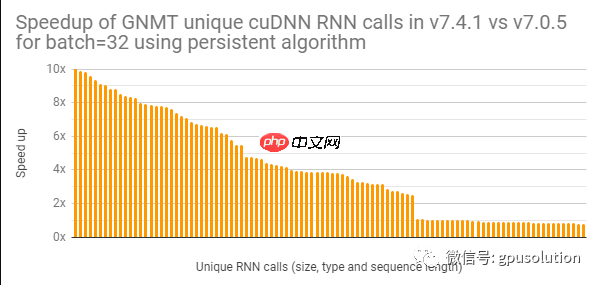
正如本博客前面所讨论的,大规模训练深度神经网络需要处理比每个GPU所能容纳的最大批处理规模更小的批处理。这为优化提供了新的机会,特别是使用RNNs(复发神经网络)的模型。当批处理大小较小时,cuDNN库可以使用在某些情况下使用持久算法的RNN实现。
虽然cuDNN已经为几个版本提供了持久的RNN支持,但是我们最近针对张量核对它们进行了大量的优化。图2中的图显示了我们对用于批处理大小为32的Tesla V100上运行的GNMT语言转换模型的持久RNNs所做的性能改进的一个示例。如图所示,许多RNN调用的性能都有了显著的提高。
 最新的cuDNN 7.4.1大大提高了计算活化梯度的性能。以前,单元跨越用例由高度专门化和快速的内核处理,而非单元跨越用例则退回到更一般化但速度较慢的内核实现。最新的cuDNN解决了这一差距,并在非单元跨步情况下大大提高了性能。通过这种增强,Deep Speech 2和Inception v3等网络中的相关激活梯度计算操作提高了25倍。
最新的cuDNN 7.4.1大大提高了计算活化梯度的性能。以前,单元跨越用例由高度专门化和快速的内核处理,而非单元跨越用例则退回到更一般化但速度较慢的内核实现。最新的cuDNN解决了这一差距,并在非单元跨步情况下大大提高了性能。通过这种增强,Deep Speech 2和Inception v3等网络中的相关激活梯度计算操作提高了25倍。
DALI训练和推理模型的视觉任务(如分类、目标检测、分割等等)需要一个重要的和相关的数据输入和增加管道,在规模与优化的代码运行时,这个管道可以迅速成为整体性能的瓶颈当多个GPU必须等待CPU准备数据。即使在使用多个CPU内核进行此处理时,CPU也难以足够快地为GPU提供数据。这会导致GPU在等待CPU完成任务时出现空闲时间。将这些数据管道从CPU移动到GPU是非常有利的。DALI是一个开放源码的、与框架无关的、用于GPU加速数据输入和扩充管道的库,它的开发就是为了解决这个问题,将工作从CPU迁移到GPU。
让我们以流行的单镜头探测器(SSD)模型为例。数据输入管道有多个阶段,如图3所示。
 所有这些管道阶段在计算机视觉任务中看起来都相当标准,除了SSD随机(基于联合的IoU交叉)裁剪,这是SSD特有的。DALI中新增的操作符通过提供对COCO数据集(COCOReader)、基于iou的裁剪(SSDRandomCrop)和边界框翻转(BbFlip)的访问,为整个工作流提供了基于GPU的快速管道。
所有这些管道阶段在计算机视觉任务中看起来都相当标准,除了SSD随机(基于联合的IoU交叉)裁剪,这是SSD特有的。DALI中新增的操作符通过提供对COCO数据集(COCOReader)、基于iou的裁剪(SSDRandomCrop)和边界框翻转(BbFlip)的访问,为整个工作流提供了基于GPU的快速管道。
结论研究人员可以利用本博客中讨论的最新性能改进,以最小的努力加速他们的深度学习培训。通过访问NVIDIA GPU Cloud (NGC)来下载完全优化的深度学习容器,从而快速启动您的AI研究,使您能够访问世界上性能最高的深度学习解决方案。此外,随着cuDNN和DALI功能的增强,还可以使用各个库。
本文翻译自NVIDIA BLog,点击阅读原文以访问文中所介绍的各个框架和库




























