







deepseek 今日正式推出其最新实验性大模型 deepseek-v3.2-exp,作为迈向下一代架构的重要阶段性成果。此次发布的核心突破在于引入了由团队自主研发的 deepseek sparse attention(dsa)稀疏注意力机制,该技术致力于显著提升长文本场景下模型训练与推理的效率。
新模型 DeepSeek-V3.2-Exp 是在先前发布的 DeepSeek-V3.1-Terminus 基础上进行迭代升级而来。其所搭载的 DeepSeek Sparse Attention(DSA)首次实现了细粒度级别的稀疏注意力计算,标志着在高效注意力结构设计上的关键进展。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
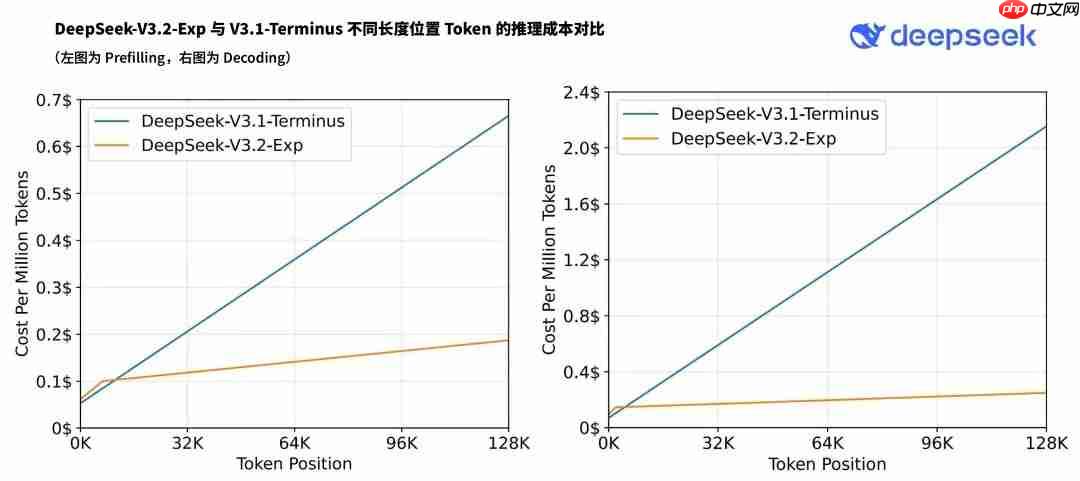
稀疏注意力机制被广泛视为优化大模型处理超长上下文窗口性能的关键路径之一。据 DeepSeek 官方介绍,DSA 在几乎不牺牲输出质量的前提下,大幅提升了长序列任务的训练和推理速度,有效降低了资源消耗。
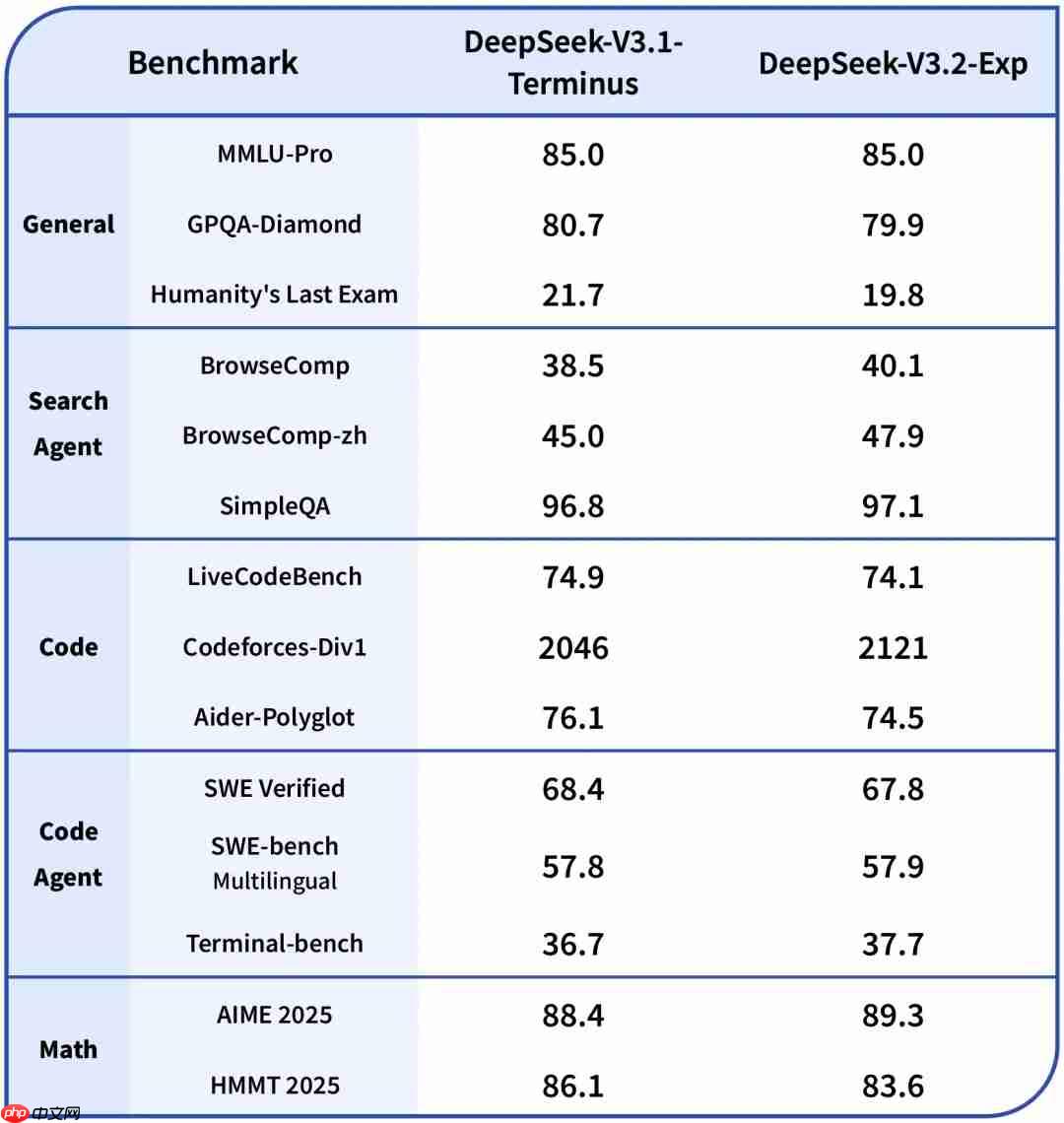
为确保对比评估的公正性和准确性,DeepSeek-V3.2-Exp 的训练设置完全沿用了 V3.1-Terminus 的配置标准。根据官方公布的基准测试结果,V3.2-Exp 在多个评测集上的综合表现与前代模型基本相当,充分证明了 DSA 技术在保持模型能力方面的稳定性与可靠性。

得益于 DeepSeek-V3.2-Exp 在服务端计算成本的显著降低,DeepSeek 同步宣布对 API 服务价格进行全面下调。官方指出,在新的定价策略下,开发者使用 DeepSeek API 的调用成本将减少超过 50%,旨在进一步降低人工智能技术的应用门槛,助力更多个人与企业快速接入大模型能力。

目前,DeepSeek 官方 App、网页版平台以及小程序均已全面切换至 DeepSeek-V3.2-Exp 模型版本,用户可即时体验更高效、更经济的智能服务。





























