
enginecrawler 主要在 linux 系统上运行,用于抓取国内外主流搜索引擎返回的 url 内容。与 windows 上的搜索引擎爬虫工具相比,linux 上的选择较少。由于我的电脑是 kali linux,无法运行 windows 软件,我便自行开发了这个小工具。开发这个工具的初衷是,在为厂商进行测试时,发现了一个 web 应用程序的通用型漏洞,需要根据 url 的特征值采集大量 url 并进行批量测试。手动复制粘贴 url 非常繁琐,这时这个工具就大显身手了。
该工具利用多进程并发来提升网页抓取的效率,并且可以自定义模块添加到工具中。目前支持的搜索引擎包括:百度、谷歌、雅虎、Ecosia、Teoma、360、Hotbot。支持直接使用百度或谷歌的高级搜索语法进行搜索。谷歌搜索引擎无需访问国外网站,抓取的数据来自我搭建的谷歌镜像站。
pip install -r requirements.txt
选项:
-h, --help 显示此帮助信息并退出
-r RULE, --rule RULE 引擎高级搜索规则
-p PAGE, --page PAGE 搜索引擎返回的页面数
-e ENGINES, --engines ENGINES
指定以逗号分隔的搜索引擎列表
-o OUTPUT, --output OUTPUT
将结果保存到文本文件中
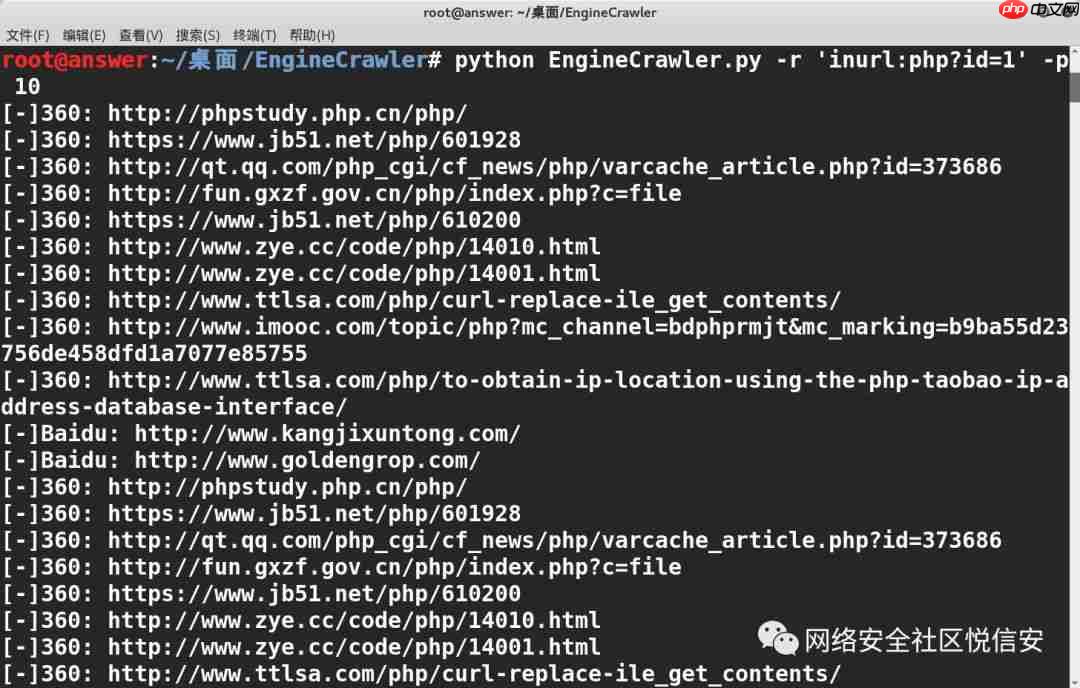
示例:python EngineCrawler.py -e baidu,yahoo -r 'inurl:php?id=1' -p 10 -o urls.txt
 如果代码有任何不足之处,欢迎提出宝贵意见~
如果代码有任何不足之处,欢迎提出宝贵意见~
GitHub 项目地址:https://www.php.cn/link/eca85870ec8b6d70a888d143988d8a4b
以上就是搜索引擎爬虫工具的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 757
757





















