
中国信通院于日前正式发布新版本“方升”基准测试体系3.0。
“方升”大模型基准测试体系3.0在原有基础上实现系统性跃升,新增模型基础属性测试,对参数规模、推理效率等底层特征进行体系化测试;同时前瞻性布局未来高级智能测试,围绕全模态理解、长期记忆、自主学习等10项高级能力构建评估能力,并进一步深化工业制造、基础科学、金融等重点行业的场景化评测。
为支撑“方升”3.0的实施,中国信通院将从以下几方面系统强化评测基础设施:
2024年起,中国信通院以两个月为周期开展大模型基准测试活动,目前已累计完成9轮评测。在最新一轮测试中,共对141个大模型和7个智能体进行了系统评估,覆盖大语言模型的基础、推理、代码能力,多模态模型的理解、生成能力以及智能体的通用能力。同时评测均采用多维度复合评估体系,涵盖69个细分测试维度,确保评估结果的全面性与科学性。
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
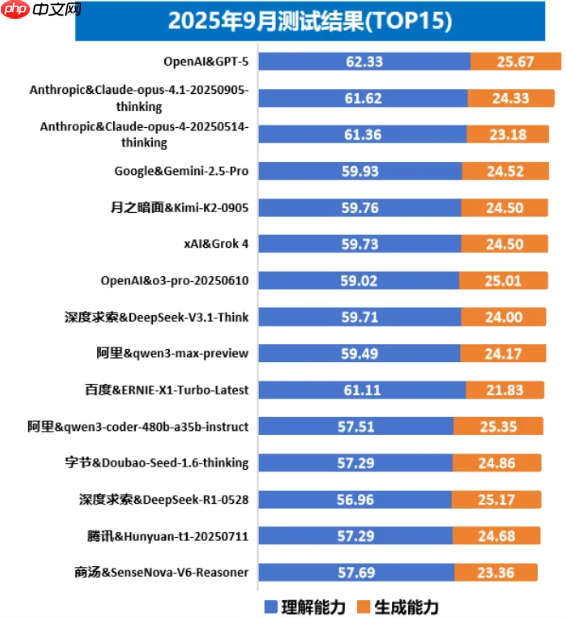
基础能力持续提升,在学科、数学、指令遵循等方面表现出色,但在幻觉、工具使用等方面仍有提升空间。OpenAI的GPT 5(8月7日发布)综合能力领先排名第一,效果优于国内阿里巴巴的Qwen3-Max-Preview、月之暗面的Kimi K2,国内外大语言模型在基础能力上差距较小。推理能力进展显著,在高阶数学、复杂学科任务场景提升明显,但在复杂中文推理场景有待加强。OpenAI的GPT 5在复杂数学、推理能力领先,排名推理榜单首位,xAI的Grok-4紧随其后;国内表现较好的推理模型是深度求索的DeepSeek-V3.1、阿里巴巴的Qwen3-235B-A22B-Thinking-2507以及百度的ERNIE-X1-Turbo-Latest,但相较国际领先水平仍存在一定差距,这标志着全球大语言模型在推理能力的竞争已进入白热化阶段(如图3所示,此处仅展示排名前15的大模型)。

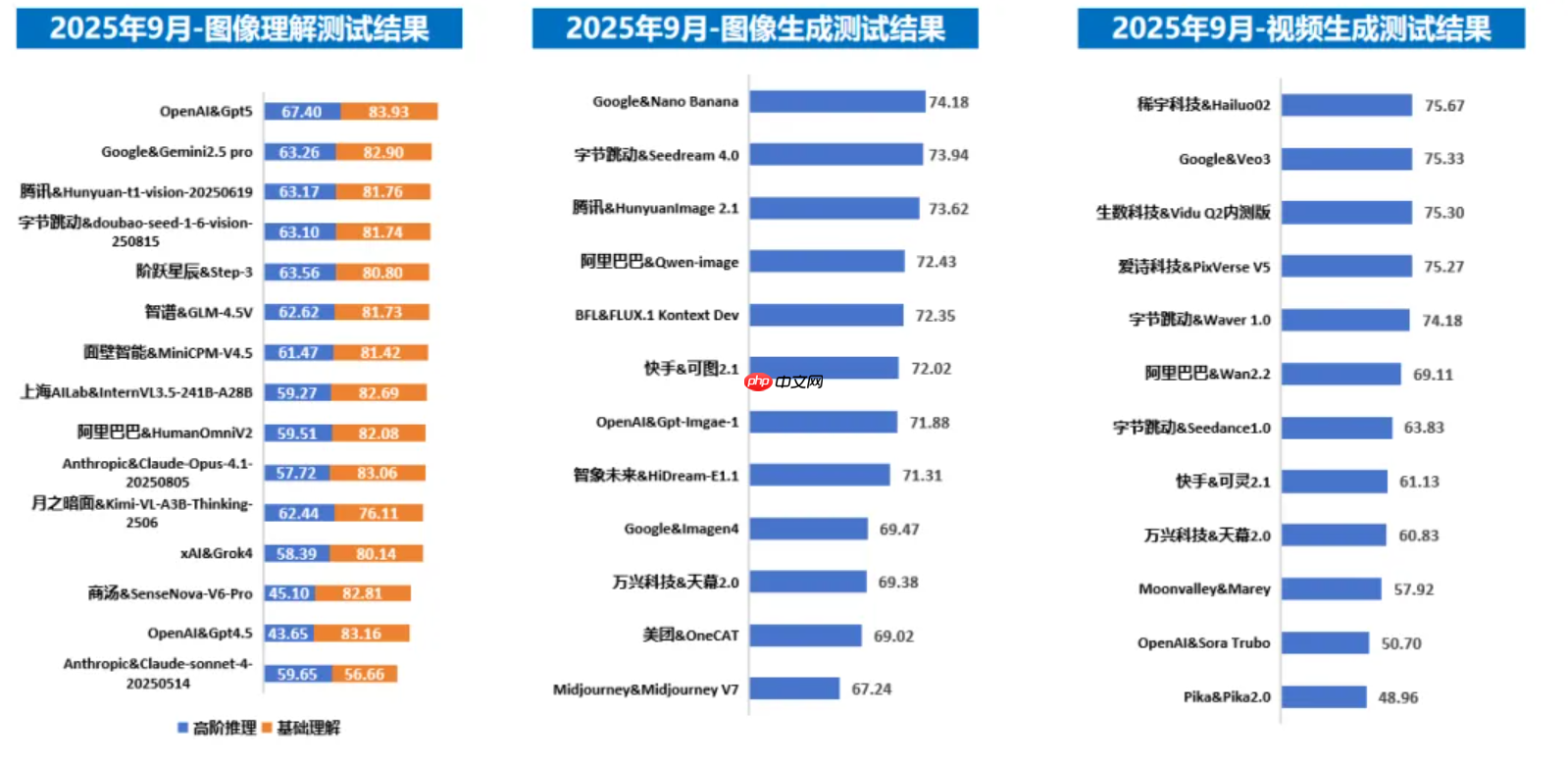
图像理解方面能力持续突破,在场景解析和颜色识别等基础任务表现突出,但在需要多步推导的复杂逻辑推理任务上性能有待加强。OpenAI的GPT-5整体表现仍居领先地位。国内模型中,腾讯混元与字节跳动豆包在细粒度对象识别与情绪感知任务中表现优异,而在复杂空间关系与因果推理的高阶认知任务中仍有提升空间。图像生成方面技术实现显著进步,生成结果在视觉真实感、细粒度细节及复杂指令跟随方面取得系统性进展。然而,在生成内容的逻辑一致性、交互自然度以及文化表达方面仍面临持续性的挑战。谷歌的Nano Banana(gemini-2.5-flash-image)小幅领先,国内字节跳动的Seedream 4.0、腾讯的HunyuanImage 2.1、阿里巴巴的Qwen-image位居前列,头部大模型竞争白热化。视频生成方面,在时序一致性建模和动态场景合成等方面取得进步,但物理合理性与情感表现力等维度仍是持续探索的重点。稀宇科技的Hailuo02、谷歌的Veo3、生数的Vidu Q2内测版排名靠前。总体来看,国内多家企业跻身前列,技术加速跃迁,头部格局初显。
大模型代码应用能力在函数级这类单一问题方面,表现较为出色,但在真实项目级开发这类复杂任务中,仍存在明显短板。OpenAI的GPT-5在代码应用能力排名首位,月之暗面的Kimi-K2-0905版本排名国内第一,国内模型在游戏开发、应用开发等项目级任务中,其在功能实现完整度与效果呈现方面,仍与国际先进水平存在一定差距。在大模型代码能力方面,推理模型能力较基础模型更具备优势,本轮测试的Top 5中,有4个为推理模型,仅有1个为基础模型。不同模型间代码理解能力整体差异不大,代码生成能力差异较为显著,大模型的代码注释、代码解释、代码生成能力依次减弱。
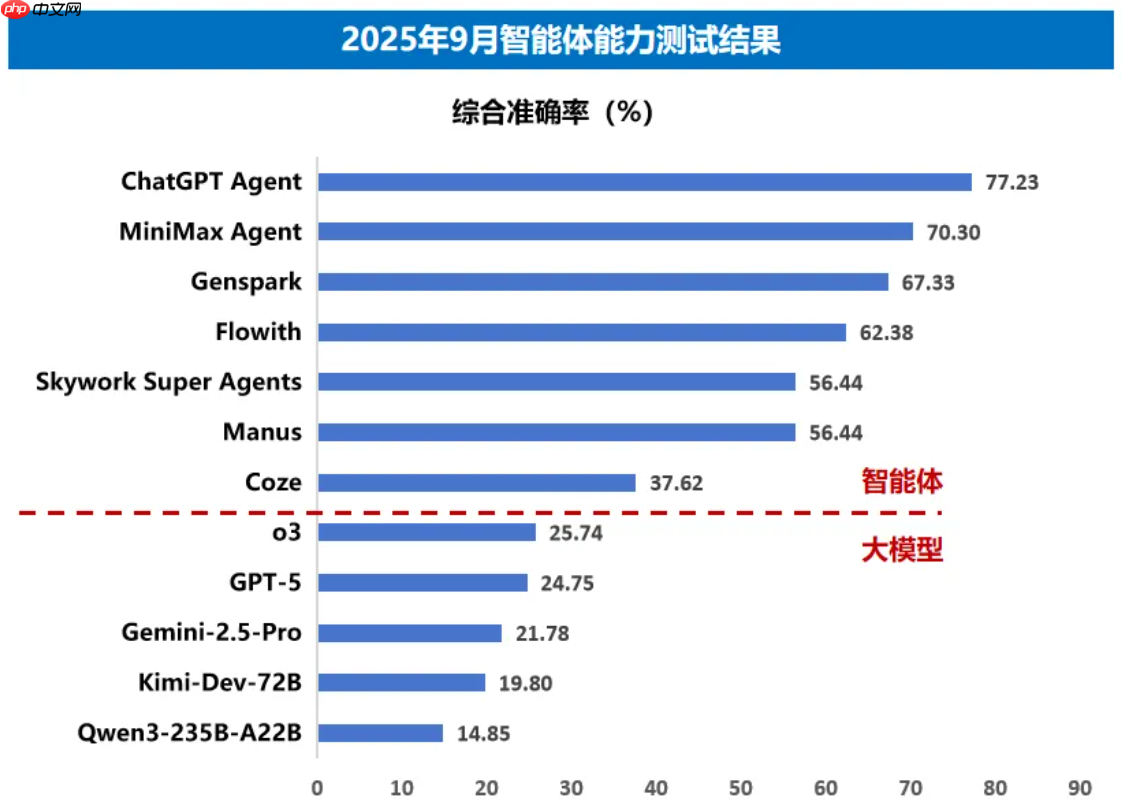
智能体应用能力相比大模型可以完成更复杂任务,但在细分任务上仍不及预期。综合表现方面,高度封装的智能体产品通过融合基座模型、MCP服务、智能体沙箱等,可以获得比GPT-5、o3等单一大模型更好的性能表现。细分场景表现方面,智能体仍处于起始发展阶段,自主性不断增强,但能力仍有一定提升空间。智能体在网页交互和复杂信息挖掘等任务上表现相对较好,主要得益于当前网页浏览工具较为成熟、基座模型推理能力不断提升。然而,在多模态理解任务方面,智能体普遍表现欠佳,暴露出其在视频内容解析、图表语义理解等关键环节的技术短板,同时存在工具调用策略不合理、信息源整合能力不足等问题。
下一步,中国信息通信研究院将持续加强大模型评测技术研发与推广,提升大模型评测公信力和权威性,支撑人工智能前沿创新与新型工业化发展。一是聚焦技术突破,夯实评测底层能力。攻关自动化测试、缺陷分析及未来高级智能评测技术,推动评测向“智能驱动”跃升。二是强化能力建设,拓展多模态多场景覆盖。拓展文本、图像、语音、视频等多模态和多应用场景,打造一体化自动测试平台,实现全栈能力覆盖。三是深化生态运营,构建闭环服务体系。提供测试分析、选型评估、闭环优化等专业服务,推进国际合作与公益测试,构建开放协同、可持续的大模型评测生态。
以上就是信通院发布“方升”3.0 体系及大模型基准测试结果的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 175
175



















