
10月21日,中文精确指令遵循测评基准superclue-cpif正式上线,文心x1.1以75.51分位列国产大模型榜首,在任务类型与指令数量两大维度的评估中均居国内首位,展现出其在真实生产场景中的突出应用潜力。
此次测评共纳入包括GPT-5(high)、DeepSeek-V3.2-Exp-Thinking、Claude-Sonnet-4.5-Reasoning、Gemini-2.5-Pro在内的10款国内外主流大模型。SuperCLUE-CPIF聚焦于大型语言模型(LLM)在中文语境下对复杂、多约束指令的精准执行能力,核心考察模型能否将自然语言指令准确转化为完全符合各项要求的具体输出。
测评结果表明,在国产大模型阵营中,文心X1.1以75.51分领先,紧随其后的是得分为73.98分的DeepSeek-V3.2-Exp-Thinking和65.82分的Hunyuan-T1-20250822,分别位列第二和第三。
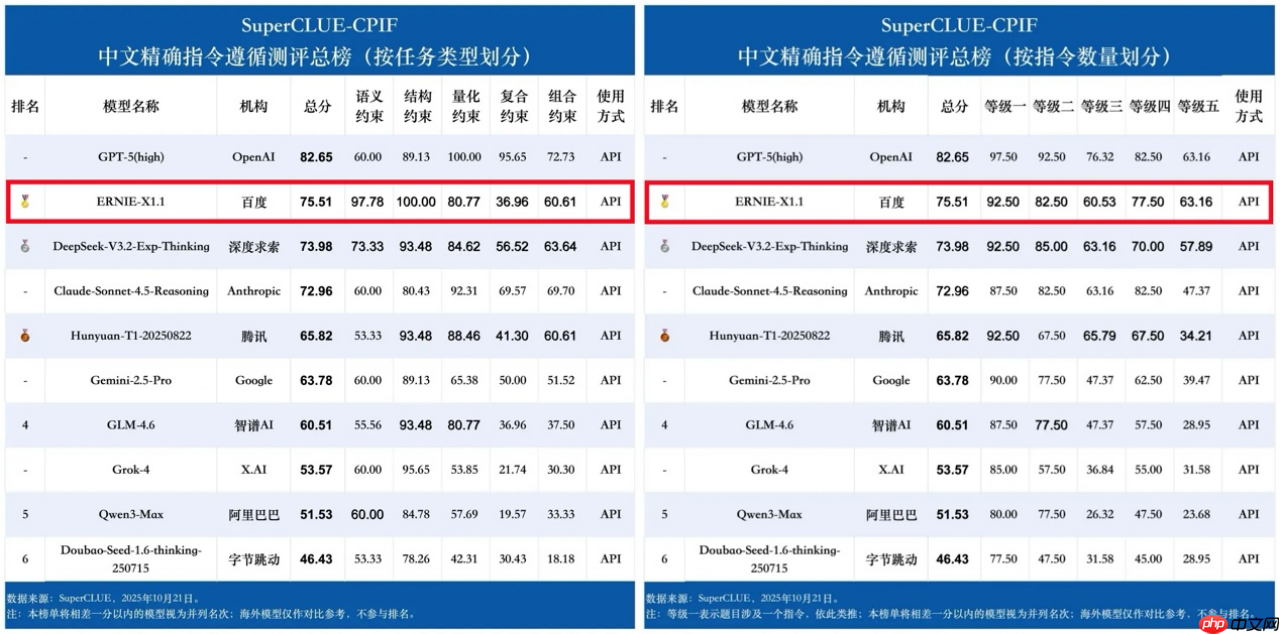
SuperCLUE-CPIF中文精确指令遵循测评总榜,文心X1.1位居国内第一
文心大模型X1基于文心4.5版本训练而成,是一款具备深度推理能力的思考型模型。升级至X1.1后,采用了迭代式混合强化学习训练架构:一方面通过混合强化学习同步提升通用任务与智能体任务表现;另一方面借助自蒸馏数据的循环生成与再训练,持续优化整体性能。
据悉,文心X1.1在应对高难度写作任务时,不仅能调用内在知识库或联网搜索获取准确信息,还能深入理解用户创意意图与具体需求,最终生成事实无误、结构清晰、逻辑严密且语言优美的内容。
在更复杂的长流程任务中,例如处理共享单车平台中不同等级用户提出的多样化问题,并叠加用户情绪状态等多重因素时,文心X1.1能够严格遵循业务逻辑进行规划,主动调用相关工具,并结合情感识别快速响应,实现全流程闭环服务,表现出高度自主性与完整性。
作为国内最早布局大模型研发与落地的企业之一,百度依托“芯片-框架-模型-应用”全栈自研技术体系,持续推进文心大模型的能力升级。得益于飞桨与文心的深度协同优化,文心大模型在能力扩展与运行效率方面持续提升。根据此前公开数据,相较于X1版本,文心X1.1在事实准确性上提升了34.8%,指令遵循能力提升12.5%,智能体行为能力提升9.6%。
源码地址:点击下载
以上就是大模型谁最“可靠”?SuperCLUE-CPIF测评出炉,文心X1.1国内第一的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 175
175
























