
美团迈出通往“世界模型”的关键一步,旨在更高效地连接现实世界的“原子”与数字世界的“比特”。
▲美团LongCat团队发布并开源LongCat-Video视频生成模型,开启“世界模型”探索之路(资料图)
10月27日,美团旗下LongCat团队正式推出并开源其最新研发的LongCat-Video视频生成模型。该模型在文生视频和图生视频任务中均达到开源领域的SOTA(最先进)水平,同时通过原生支持视频续写任务的预训练机制,成功实现分钟级长度的高质量、连贯性视频生成,在跨帧时序一致性与物理运动合理性方面表现突出,显著提升了长视频生成的技术上限。
近年来,“世界模型”(World Model)因其具备理解、预测乃至重构真实世界运行规律的能力,被广泛视为通向下一代人工智能的核心路径。作为一种能够学习物理法则、时空动态及场景逻辑的智能系统,“世界模型”使AI获得对现实世界的深层认知能力。而视频生成技术正被视为构建此类模型的重要突破口——通过从大量视频数据中提炼几何结构、语义信息与物理规律,AI可在虚拟空间中模拟和推演真实世界的演变过程。
基于这一愿景,LongCat团队指出,此次发布的LongCat-Video正是迈向“世界模型”的首次实质性尝试。未来,该模型将有望应用于美团持续布局的自动驾驶、具身智能等需要深度环境交互的业务场景中,成为连接“比特世界”与“原子世界”的核心技术桥梁。

▲LongCat-Video实现视频推理速度提升至10.1倍,突破效率瓶颈(资料图)
根据技术文档披露,LongCat-Video基于Diffusion Transformer(DiT)架构打造,是一款多功能统一的视频生成基座模型。其创新性地利用“条件帧数量”作为任务区分信号:无条件帧时执行文本生成视频,输入1帧图像则进行图生视频,多帧历史序列则用于视频续写任务,无需额外微调或模块切换,真正实现了“文生—图生—续写”三大任务的一体化闭环。
尤为值得一提的是,得益于以视频续写为核心的预训练策略,该模型可稳定输出长达5分钟的连续视频内容,且在整个过程中保持画质稳定、动作流畅,有效避免了行业常见的色彩漂移、画面降级和动作断裂等问题,确保长时间序列下的视觉一致性和物理合理性,满足数字人、机器人仿真、世界模型训练等高要求应用场景的需求。

Easily find JSON paths within JSON objects using our intuitive Json Path Finder
 193
193

为应对长序列处理中的计算冗余问题,模型引入块稀疏注意力(BSA)与条件token缓存机制,在处理93帧以上的长视频时仍能维持高效推理与高质量输出,彻底打破“视频越长,质量越差”的技术困局。
针对高分辨率、高帧率带来的算力挑战,LongCat-Video采用“二阶段粗到精生成(C2F)+ 块稀疏注意力(BSA)+ 模型蒸馏”三重优化方案,使整体视频推理速度提升达10.1倍,在保证视觉表现力的同时实现极致效率平衡。
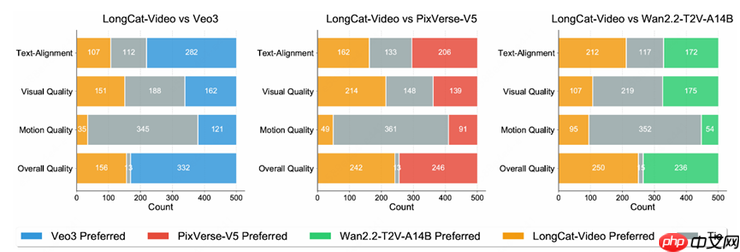
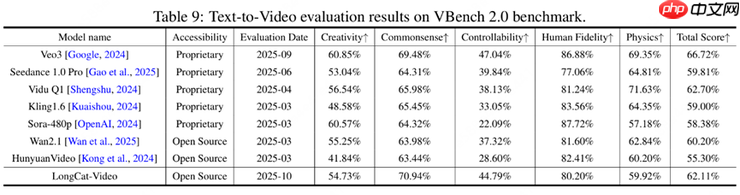
▲LongCat-Video在多项基础任务中达到开源SOTA水平(资料图)
据评估报告,LongCat-Video的性能测试涵盖内部基准与多个公开评测体系,重点考察Text-to-Video(文本生成视频)和Image-to-Video(图像生成视频)两大核心任务,并从文本对齐度、图像保真度、视觉质量、运动连贯性及整体观感等多个维度进行全面评估。结果显示:其136亿参数规模的基座模型在两项任务上均达到当前开源模型中的领先水平;尤其在文本匹配精度、动作自然性等关键指标上优势明显;在VBench等权威公开基准测试中,综合表现位居前列,展现出强大的泛化能力与实用性。
以上就是美团开源LongCat-Video支持高效长视频生成,迈出“世界模型”探索第一步的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号






 642
642



















