
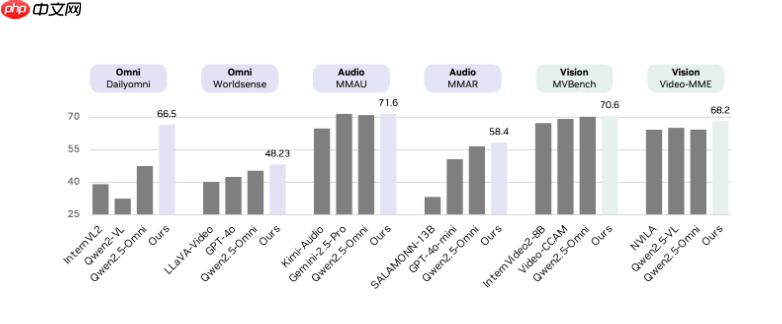
英伟达研究团队近日推出了一款名为 omnivinci 的全模态理解模型,该模型在关键的全模态基准测试中表现卓越,领先当前最优模型高达19.05分。更令人瞩目的是,omnivinci 仅依赖其六分之一的训练数据量,便实现了这一突破性成果,充分展现了其在数据利用效率和模型性能上的双重优势。
OmniVinci 致力于构建一个能同时处理视觉、音频与文本信息的通用人工智能系统,目标是让机器具备类似人类的多感官感知能力,从而更全面地理解和解析现实世界中的复杂场景。为达成此目标,研究团队设计了全新的架构方案与数据处理策略,通过构建统一的全模态潜在空间,实现跨模态信息的深度融合与协同理解。
在 Dailyomni 基准评测中,OmniVinci 显著优于 Qwen2.5-Omni:在音频理解任务 MMAR 上提升1.7分,在视觉理解任务 Video-MME 上高出3.9分。值得注意的是,其训练所使用的 Token 总量仅为0.2万亿,远低于 Qwen2.5-Omni 所需的1.2万亿,表明 OmniVinci 的训练效率达到后者的6倍之高。
该模型的核心技术突破在于其全模态对齐机制,包含三大关键组件:OmniAlignNet 模块、时间嵌入分组(TEG)以及约束旋转时间嵌入(CRTE)。其中,OmniAlignNet 充分利用视觉与音频信号之间的互补特性,增强两种模态间的联合学习与对齐效果;TEG 通过对音视频信号按时间片段进行分组处理,有效建模时序依赖关系;而 CRTE 则进一步优化了时间轴上的精确对齐,确保模型能够准确捕捉事件发生的绝对时间位置。
新生代企业网站管理系统是一款基于php+mysql+smarty的免费开源建站系统。整套系统的设计构造,完全考虑大中小企业类网站的功能要求,网站的后台功能强大,管理简捷,支持模板机制,配置中英文双语言版。通过新生代企业网站管理系统,企业建站者可以轻松构建一个企业网站,让企业用户可以更加便捷了解企业的相关信息与动态;方便快捷地发布企业信息、产品等;更可以十分方便的通过管理平台管理企业的站内新闻、产品
 0
0

研究团队采用了两阶段训练范式:第一阶段专注于各单一模态的能力培养,第二阶段则进行全模态联合训练,逐步提升模型的综合理解水平。此外,在隐式全模态学习方面,研究人员借助现有的视频问答数据集,显著增强了模型对音视频内容的协同理解能力。
源码地址:点击下载
以上就是英伟达开源全模态理解模型 OmniVinci的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 779
779



















