
复旦大学携手美团longcat共同发布了 r-horizon——首个专注于系统性评估与提升大型推理模型(lrms)长链推理能力的评测框架与训练方法。

R-HORIZON 创新性地提出了“问题组合”(Query Composition)策略,通过在不同问题之间建立逻辑依赖关系,将原本独立的任务转化为复杂的多阶段推理流程。
以数学推理任务为例,该方法包含以下三个关键步骤:
核心优势:
基于这一机制,研究团队构建了 R-HORIZON Benchmark,用于全面评估 LRMs 在多步推理场景下的表现,并同步生成大规模长链推理训练数据。结合强化学习(RLVR)技术,显著提升了模型的深层推理能力。
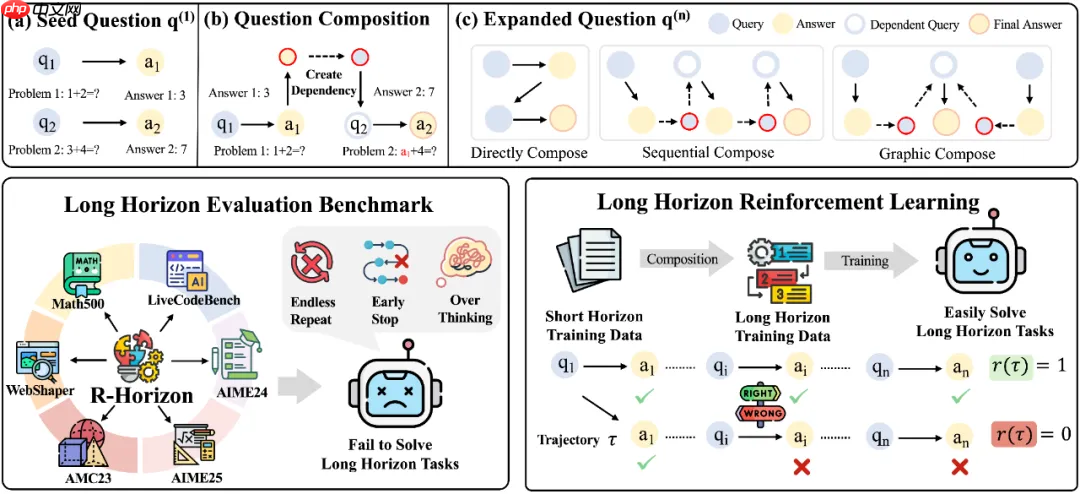
R-HORIZON 方法流程示意图——从单一问题到多层依赖推理链的构建过程及应用方向
R-HORIZON 代表了大型推理模型研究范式的重大演进——不再局限于“能解决哪些问题”,而是深入探索“推理链条能延伸多远”。
主要技术贡献:
论文标题: R-HORIZON: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth? 论文链接: https://www.php.cn/link/5a7a6185f07dab689218c182fcf3b4ae 项目主页: https://www.php.cn/link/b62b2fca53f1466b2d09f6f05325e357 开源代码: https://www.php.cn/link/b9b1446d5dac7a83f7478d31f514dcf1 数据集地址:https://www.php.cn/link/f54fd264edeb6c5043be90f1570d4ea3
以上就是复旦大学与美团联合发布 R-HORIZON,长链推理评测框架的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 574
574
























