







今天,deepseek v3.1 正式亮相。相较于之前的 v3 与 r1 版本,此次升级带来了三大核心突破:
? 混合推理架构:单模型同时支持“思考模式”与“非思考模式”,灵活应对不同任务需求;
⚡ 更高的推理效率:在多数场景下,DeepSeek-V3.1-Think 能以更短时间输出高质量结果;
? 更强的 Agent 能力:通过后训练优化,在工具调用、任务分解与智能体执行等关键环节实现显著提升。
如果说 R1 是“探索思维链”的起点,那么 V3.1 则标志着迈向“实用化智能体”的关键一步。官方公众号将其定义为“迈向 Agent 时代的第一步”。然而,文中仅对比了自家前代模型 R1 和 V3,未提及其他主流模型。这不禁让人发问:它在全球顶尖大模型中的真实位置究竟如何?
为此,我们决定跳出内部对比,将 DeepSeek V3.1 置于全球第一梯队进行横向评测分析。
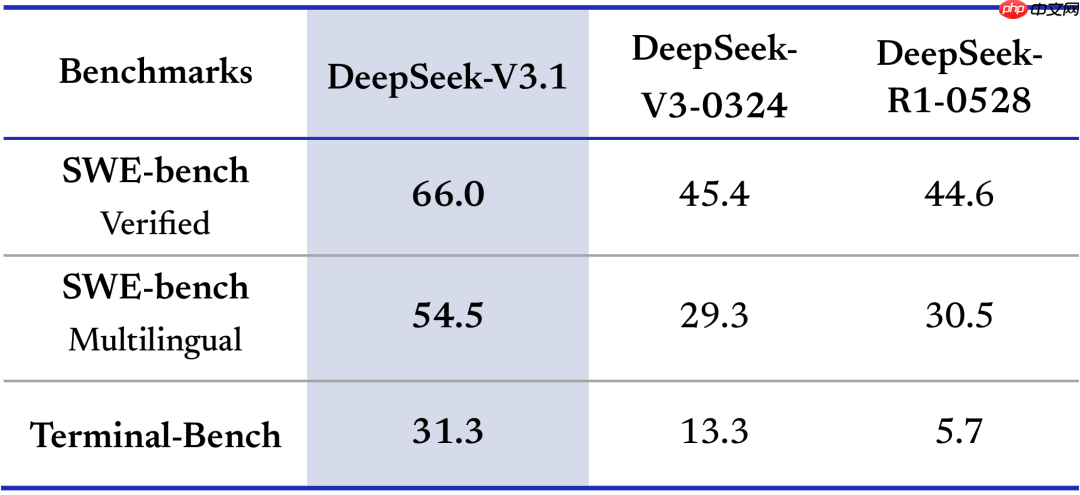
所有数据均来源于各厂商官方发布的公开评测报告(非第三方媒体整合),主要参考如下:
- Google Gemini: https://www.php.cn/link/6338c24be7d85863109dc1a27183263a
- Anthropic Claude 4.1: https://www.php.cn/link/26eba28391cc000f58d3b0f57bc83964
- OpenAI GPT-5: https://www.php.cn/link/12c0a9032599cc7067f93df32d3ab1cb
- DeepSeek 官方公众号
我们坚持“古法制表”,手工整理出以下横向对比榜单:
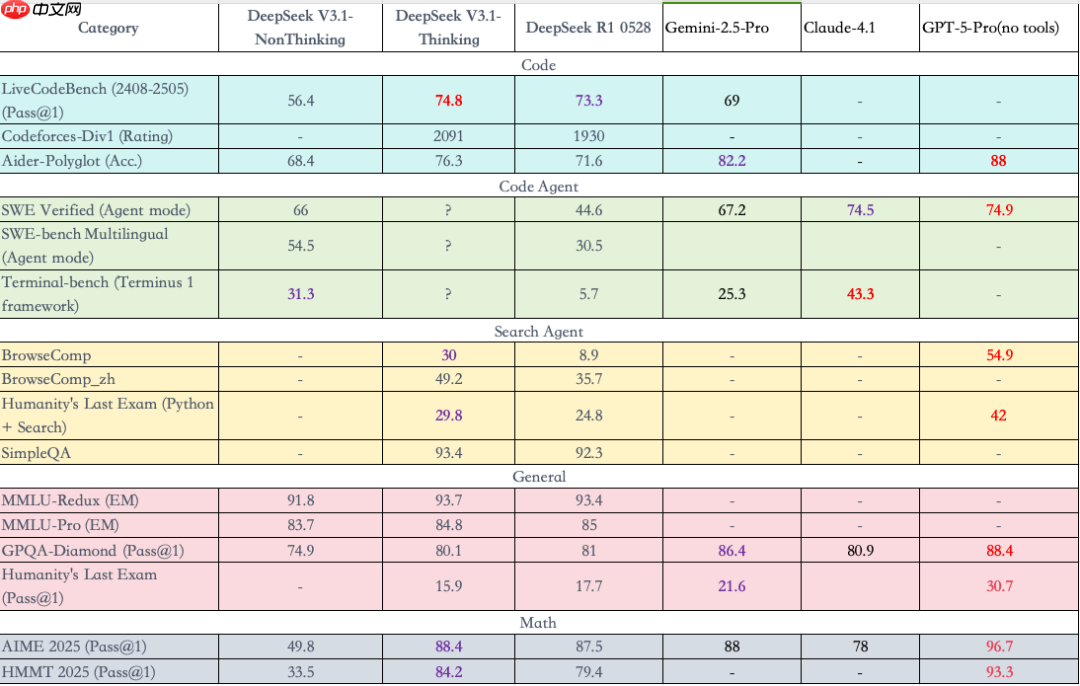
从数据可见:
- 在数学与复杂推理任务中,V3.1 已经紧追 Claude 4.1 与 GPT-5 的表现,在 General 和 Math 类 benchmark 上部分指标甚至超越 Gemini。
- 编码能力方面,DeepSeek V3.1 继续保持领先优势,与 GPT-5 的差距进一步缩小,尤其在 SWE Verified 和 Terminal-bench 上表现抢眼。
- 在综合 Agent 任务(如多步骤操作、工具调度)中,相较 R1 实现质的飞跃,已初步具备构建多智能体协作生态的能力。
重点来了!!!

为何官方标题强调“迈向 Agent 时代的第一步”?
查看 Agent 相关榜单即可明白:在 Terminal-bench 上,V3.1 从 R1 的 5.7 飙升至 31.3,提升近 6 倍——即便在 Non-Thinking 模式下也已超过 Gemini。而在 SWE-bench 上,性能提升达 50%,直逼 Gemini 水准!
因此,我们必须大声指出:DeepSeek V3.1 在智能体能力上走出了一条新路径,堪称“摸着 Google Gemini 过河”!
Google Gemini:让你学,没让你超啊!!!(一边嘀咕一边退场)
还有一个重磅消息:除了模型本身的跃迁,DeepSeek 官宣 V3.1 正在适配下一代国产 GPU 芯片。

wechat_2025-08-21_160157_383
wechat_2025-08-21_160157_383
据业内传闻:
这意味着未来国产大模型有望逐步摆脱对海外算力的依赖,走向真正的自主可控。这不仅是技术路线的重要转向,更是产业布局上的深远落子。国产之光,实至名归!
总结
如果把 2023–2024 年中国大模型的主题定义为“追赶”,那么 2025 年的 DeepSeek V3.1 提供了一个更具雄心的答案:
- 技术层面:缩小差距,局部反超;
- 应用层面:强化 Agent 能力,推动多模态与工具化落地;
- 产业层面:拥抱国产芯片,探索可持续发展路径。
一句话总结:DeepSeek V3.1 不是终点,而是国产大模型挺进世界第一梯队的真正开端。





























