
在这个ai探索如大航海时代般波澜壮阔的当下,我们几乎每天都被新技术的突破所震撼。然而,有一个现实却常常被忽略:在全球超过7000种语言中,绝大多数在人工智能的世界里依然“无声无息”。当前的语音识别系统,往往只青睐那些拥有海量数据支撑的主流语言。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

如今,Meta的基础人工智能研究团队(FAIR)决定打破这一局限。他们最近正式发布了Omnilingual ASR——一个极具野心的自动语音识别系统。
它的使命非常直接:听懂地球上最多数的人类声音。

这个系统的第一个数字就令人震惊:它能够转录超过1600种口语语言。
让我们稍作停顿,感受一下这个规模。大多数人甚至无法说出1600种语言的名字,更别说分辨它们的地理分布。更重要的是,Meta明确指出,在这1600种语言中,有整整500种此前从未被任何AI系统覆盖过。
这不仅仅是数量的增长,而是在AI地图上点亮了500个此前完全空白的语言区域。FAIR团队的目标清晰而宏大:打造一个真正意义上的“通用语音转录系统”,填补现有AI技术在语言包容性上的巨大缺口。
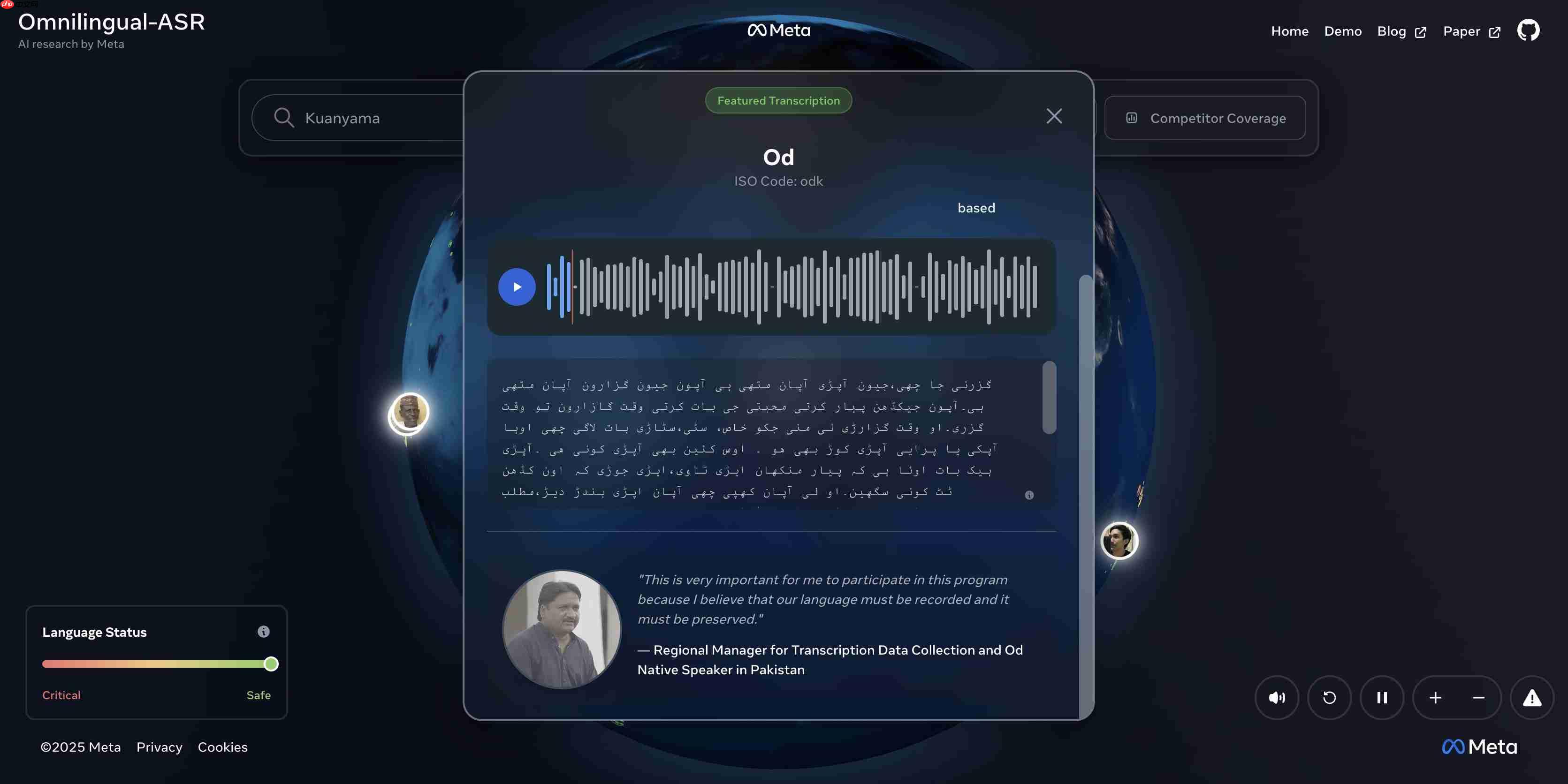
当然,科技圈见惯风浪,大家都知道“覆盖面广”不等于“体验出色”。如果一个系统号称支持上千语言,但识别错误百出,那也不过是华而不实的展示品。
Omnilingual ASR的实际表现却相当亮眼:
在其支持的1600种语言中,高达78%的语言实现了低于10个字符错误率(CER),达到了实际可用的标准。
对于资源充足的语言(即拥有至少10小时标注音频),达到这一精度的比例更是高达95%。
真正的挑战在于低资源语言(训练音频少于10小时)。即便如此,该系统仍为其中36%的语言提供了低于10 CER的高质量转录服务。对那些长期被数字世界边缘化的语言社群而言,这是一次意义深远的技术平权。

Omnilingual ASR最引人注目的创新,是一种名为“自带语言”(Bring-Your-Own-Language)的功能。
这项技术灵感来自大型语言模型中的“情境学习”(In-context Learning)。这意味着用户不再需要等待官方更新来支持自己的母语。
只需提供少量配对的音频与文本样本——例如几分钟录音及其对应文字——系统就能即时从这些样本中学习一门新语言。整个过程无需重新训练模型,也无需庞大的算力投入。
Meta表示,理论上,这一机制可将Omnilingual ASR的语言覆盖范围从目前的1600种扩展至超过5400种。这几乎是对全球7000多种语言终极目标发起的一次全面冲锋。

延续FAIR团队一贯作风,如此强大的工具自然选择开源。Meta此次构建了一个完整的“开放生态”:
模型全面开源:Omnilingual ASR基于PyTorch的fairseq2框架开发,并以Apache 2.0许可证发布。这意味着研究人员、开发者乃至企业均可自由使用、修改和部署。模型提供多个版本,参数量从3亿(适合移动端或嵌入式设备)到70亿(追求极致准确率)不等,满足不同需求。
公开数据集:Meta同步推出了“全语言自动语音识别语料库”(Omnilingual ASR Corpus),包含350种代表性不足语言的大规模转录语音数据,采用CC-BY(知识共享署名许可)协议开放获取。
Meta此举,实质上是向全球开发者发出诚挚邀请:工具和数据已备好,欢迎你们为本地社区创造真正有用的语音应用。
总的来说,Omnilingual ASR的诞生,标志着跨越全球语言鸿沟的重要一步。它不仅是一次技术飞跃,更是推动AI普惠化、实现语言平等的关键里程碑。
以上就是史上最全的AI 翻译模型来了!支持 1600 种语言的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 703
703






















