







东北大学“小牛翻译”团队近期正式对外开源其全新大规模多语言翻译模型——niutrans.lmt(large-scale multilingual translation),成功实现对60种语言、共计234个翻译方向的全面覆盖。该模型以中文和英文为双核心,构建起连接全球语言的高效桥梁,尤其在藏语、阿姆哈拉语等29种低资源语言翻译上取得重大突破。
与主流依赖英语作为唯一枢纽语言的翻译系统不同,NiuTrans.LMT创新性地采用中-英双中心架构,支持中文↔58种语言、英文↔59种语言之间的直接翻译,有效规避了传统“中文→英文→目标语”的级联翻译带来的信息失真问题。
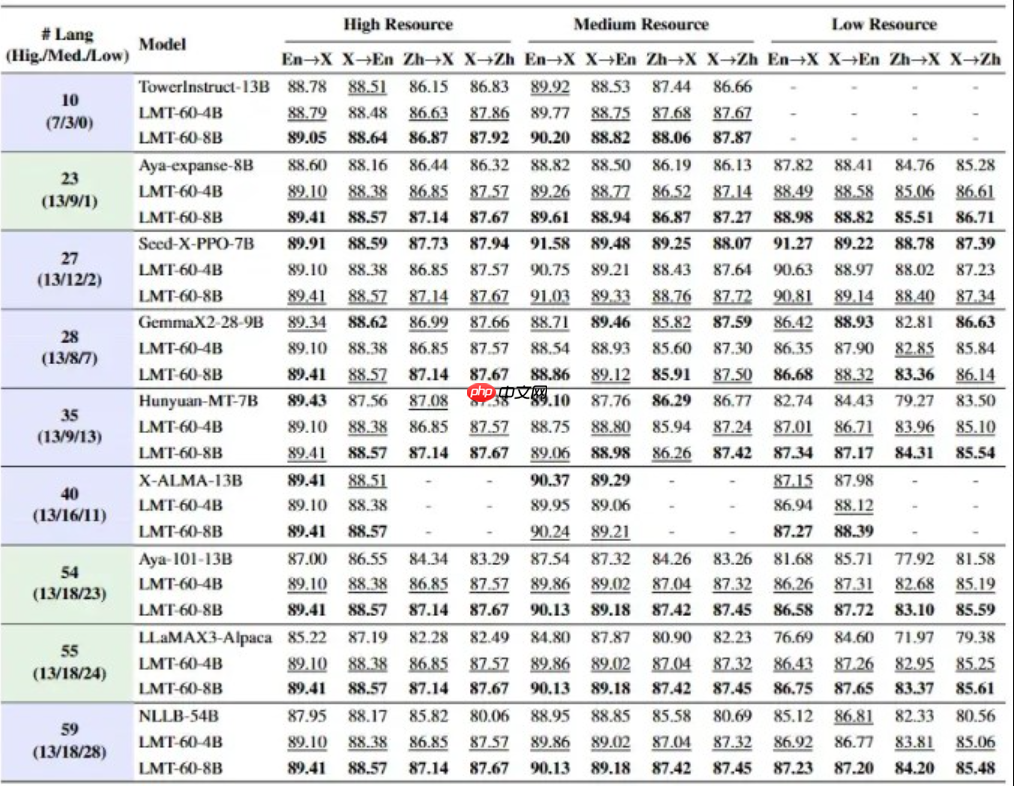
13种高资源语言(如法语、阿拉伯语、西班牙语):译文自然流畅,接近母语表达水平; 18种中资源语言(如印地语、芬兰语):术语准确、句式规范,在专业场景表现稳定; 29种低资源语言(包括藏语、斯瓦希里语、孟加拉语等):借助数据增强与迁移学习技术,实现从“难以翻译”到“基本可用”的关键跃升。
NiuTrans.LMT 的训练分为两个关键阶段:
外贸多语言保健品化妆品独立站源码(内置ai智能翻译)2.0.7
下载
这款 AI 智能翻译外贸多语言保健品化妆品独立站源码是zancms专为外贸化妆品企业量身定制。它由 zancms 外贸独立站系统 基于化妆品出口企业的独特需求进行研发设计,对各类智能产品企业的出口业务拓展同样大有裨益。其具备显著的语言优势,采用英文界面呈现,且内置智能 AI 翻译功能,在获得商业授权后更可开启多语言模式,充分满足不同地区用户的语言需求,并且整个网站的架构与布局完全依照国外用户的阅读
- 继续预训练(CPT):基于高达900亿token的多语言语料库进行均衡训练,防止小语种在训练过程中被高频语言淹没;
- 监督微调(SFT):融合FLORES-200、WMT等多个权威平行语料库,共纳入56.7万条高质量翻译样本,覆盖117个翻译方向,显著提升翻译精度与风格统一性。
为适配多样化的应用需求,项目团队同步发布了0.6B、1.7B、4B、8B四种参数量级的模型版本,全部开放于GitHub与Hugging Face平台免费下载。其中轻量版可在普通消费级GPU上运行,适用于移动端或边缘设备部署;而8B大模型则面向企业级高精度翻译任务,支持API接入及本地化私有部署。
源码地址:点击下载




























