







腾讯云联合小红书hilab infra团队,在sglang 中实现了deepseek量化模型的高效推理优化,并在huggingface中发布了deepseek-v3.1-terminus的量化模型。
量化方案介绍
当前主流的大语言模型普遍采用MoE架构,这种架构可以在减少训推成本的同时提升模型性能,与此同时,模型体积也变得越来越大。比如,DeepSeek系列为671B,Kimi K2达到了 1TB,而当前主流的GPU单卡显存只有 80GB/96GB,通常需要双机分布式部署。
模型量化是提升推理效率、降低推理成本的主流方式,它是指在保持模型精度尽量不变的前提下,将模型使用的**高精度数值(如 FP32/BF16 浮点数)转换为低精度数值(如 FP8、INT8、INT4 甚至更低比特)**的过程,从而减少了大模型内存占用、提升了推理性能。
当前针对MoE模型,社区普遍使用W4AFP8 混合量化方案,这种量化方案的特点在于:
-
对权重(Weight)采用 INT4 量化,对激活(Activation)采用 FP8 动态量化;
-
只对普通专家权重使用INT4量化,而对其他线性层保留DeepSeek原生的FP8量化方式;
这样做的好处在于,普通路由专家权重占整个模型体积的 97% ,只对普通路由专家权重做 4-bit量化,可以在降低一半模型体积的同时,尽可能减小模型运行时精度损失,并且提升了权重读写带宽,进而加快了推理速度。
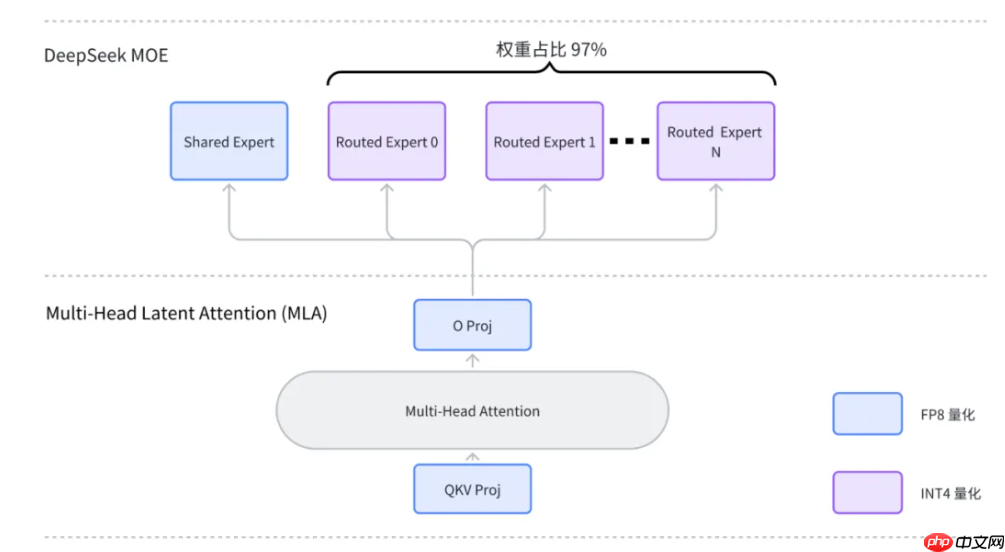
W4AFP8混合量化方案
通过上述W4AFP8混合量化方案,可以将DeepSeek系列模型大小从689GB减小到 367GB,从而可以实现单机八卡部署,推理成本降低 50%。为了实现这种量化模型的高效推理,项目团队在SGLang中实现了一种优化的推理方案,并贡献给了开源社区。
推理框架优化
大模型中的MoE模块推理时一般有两种并行策略:TP并行(Tensor Parallel)和 EP并行(Expert Parallel),如下图所示。 EP并行时,每个 GPU 负责一部分专家(Experts),不同 GPU 上的专家各不相同,而TP并行是将单个专家(例如 MLP 的权重矩阵)在多 GPU 之间做切分,共同计算。

TP并行和EP并行的权重划分对比示意图
SGLang中最初针对W4AFP8模型的推理方案是EP并行。EP并行的好处是在并行度比较大的时候,整体通信效率更高,但是在单机八卡时通信效率跟TP没有差异;另外,EP并行在并发比较小时还有负载不均衡的问题,热点 Expert所在的GPU卡会拖慢整体计算速度,如下图。
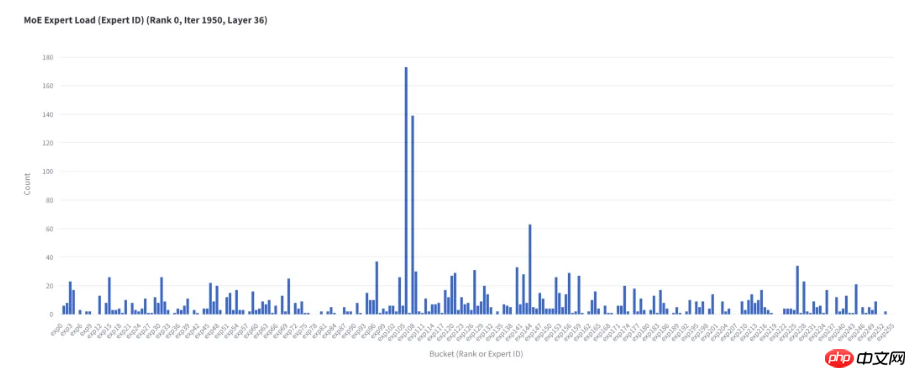
不同专家被激活的token数量(图片源于NVIDIA公众号)

TP并行时,所有GPU卡计算量一致,整体计算时间稳定,性能相比 EP有明显提升。
然而,将这一理论上的优势转化为实际可用的功能,需要克服以下两个挑战:
1. 权重切分与加载的适配:实现TP并行需要设计一套新的权重加载逻辑,能够正确识别需要切分的权重(如专家MLP层的权重矩阵),并按照TP的策略(如行切分或列切分)将其均匀地切分到多个GPU上。同时,新的TP实现需要能够无缝集成到推理框架现有的分布式调度逻辑中。
2. 推理计算内核的兼容:模型推理时前向传播计算需要适配TP模式,这是实现TP部署的核心工作。例如,对于一个线性层,TP部署时输入的权重和对应的量化参数维度已经变化,如果直接使用原来的算子可能会有计算错误,或者性能无法达到最优;这要求对推理框架中负责MoE层计算的核心内核有深入的了解并进行修改。

SGLang中W4AFP8量化模块架构图,深色为TP并行需要修改的部分
为此,腾讯云联合小红书Hilab Infra团队,为SGLang提供了完整的 W4AFP8模型TP并行推理实现。在开发过程中,团队深入分析了模型结构,修改了SGLang中与模型权重加载相关的代码,确保W4AFP8格式的量化权重能被正确切分并加载到TP组内的各个GPU中;另外,重构了CUDA内核调度模块,修改了CUDA内核实现,确保了MoE模块TP计算时精度无损;同时,遍历了各种内核调优配置(TileShape,ClusterShape和 Scedule策略),并从中选取最优组合,保证了MoE算子的高性能。
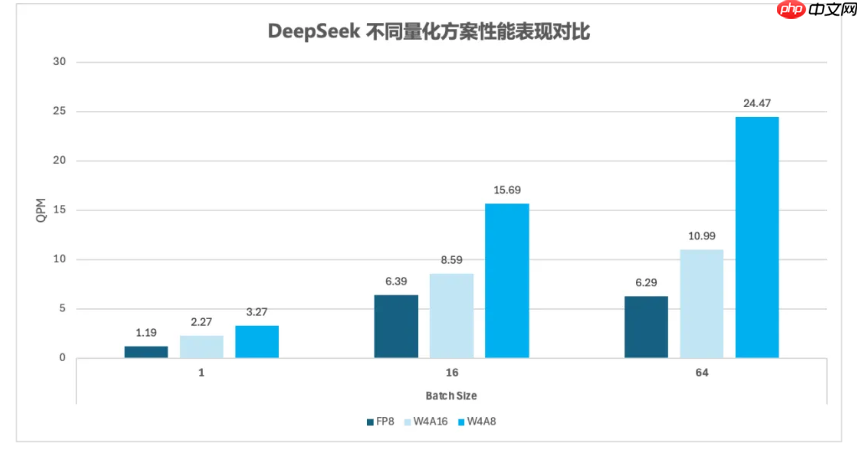
通过上述优化攻坚,当前TP方案推理性能相比最初方案有了显著提升:TTFT最高降低了 20%,QPM最高提升了 14%。目前相关PR已正式合入 SGLang V0.5.2版本。详见 https://github.com/sgl-project/sglang/pull/8118
在SGLang V0.5.2之后的版本用TP并行部署 W4AFP8模型很简单,只需要如下命令:
python3 -m sglang.launch_server --model-path /path/to/model --tp 8 --trust-remote-code --host 0.0.0.0 --port 8000
DeepSeek-V3.1-Terminus 量化高效推理方案
DeepSeek-V3.1-Terminus 是 DeepSeek 最新一代开源模型,在保持超强推理能力的同时,进一步提升了通用任务性能与代码生成能力。与前代模型相比,Terminus 在多语言理解、数学推理、长上下文等任务上均有显著提升。详见 https://api-docs.deepseek.com/news/news250922
项目团随完成了DeepSeek-V3.1-Terminus的 W4AFP8量化,在这个过程中使用了更多场景下的校准数据集, 使得MMLU-Pro任务精度损失仅为 0.38%。目前该模型已经上传到 HuggingFace。详见:https://huggingface.co/tencent/DeepSeek-V3.1-Terminus-W4AFP8
该模型可以由上述推理优化方案直接支持,单台GPU部署时推理性能相比量化FP8模型,可以提升 2.7×~3.9×。
源码地址:点击下载





























