







Vidi2是什么
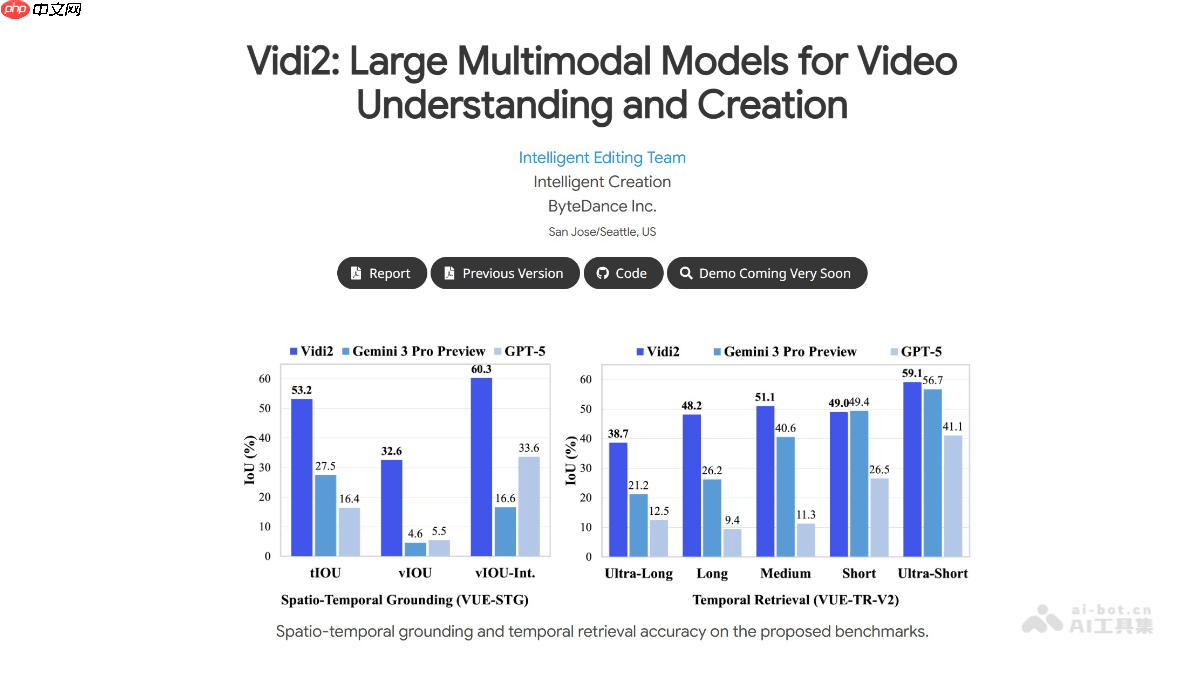
vidi2是由字节跳动研发的、专注于视频理解与智能创作的多模态大语言模型。该模型在多模态时间检索(tr)任务中表现卓越,达到业界领先水平,并在时空定位(stg)和视频问答(video qa)方面实现了重要突破。vidi2能够根据文本指令精准识别视频中的时间节点,并标注出目标物体的边界框,实现细粒度的时空感知。为更准确评估其stg能力,vidi2引入了两个新基准:vue-stg 和 vue-tr-v2。在实际应用中,vidi2支持智能剪辑、自动分镜、智能字幕生成等功能,显著提升视频内容创作者的工作效率。

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 Vidi2的主要功能
Vidi2的主要功能
- 长视频理解与检索:可处理长达数小时的视频内容,依据自然语言查询快速定位相关片段,适用于复杂场景下的长视频分析。
- 时空目标定位(STG):不仅识别事件发生的时间段,还能在对应帧中标注出具体对象的位置框,实现“何时+何地”的双重定位。
- 视频内容问答(Video QA):支持基于视频语义的问题回答,具备较强的跨模态推理能力,能理解动态视觉内容并作出合理回应。
- 智能视频创作辅助:提供自动化剪辑建议、镜头拆解、字幕生成等工具,帮助用户将原始素材高效转化为适合TikTok等平台传播的短视频内容。
- 多视角切换与智能重构图:具备构图感知能力,可自动选择最佳视角或进行智能裁剪,优化画面布局,增强视觉表现力。
Vidi2的技术原理
- 多模态融合架构:结合高性能视觉编码器与大规模语言模型,通过指令微调和跨模态对齐训练,构建统一的视频-文本理解体系。
- 时空定位机制:利用Transformer结构建模视频的时空特征,结合文本描述进行联合嵌入学习,实现对目标出现时刻及空间位置的精确预测。
- 文本-视频跨模态检索:将文本查询与视频片段映射至共享向量空间,通过余弦相似度等方法完成高效匹配,支撑快速内容查找。
- 多粒度时序建模策略:采用滑动窗口、记忆token保留以及检索增强机制,有效捕捉从瞬时动作到长期情节演变的多层次时间信息。
- 跨模态信息对齐技术:深度融合视频中的图像、音频与文本语义,确保不同模态间的信息一致性,提升整体理解准确性。
Vidi2的项目地址
- 官方主页:https://www.php.cn/link/19081333d0f55f0e056d42691466a191
- GitHub代码库:https://www.php.cn/link/5f963b42063bb09eaf0529dd0e6d84ce
- arXiv论文链接:https://www.php.cn/link/2f02ebc2e4fc50a2545e0709c5fb526c
Vidi2的应用场景
- 自动化视频剪辑:从直播回放、访谈或会议录像中提取关键片段,自动生成高光集锦。
- 交互式视频问答:允许用户提问如“人物什么时候拿起杯子?”等问题,系统直接返回时间点与画面信息。
- 编辑流程智能化:为专业剪辑师提供精准的对象与时间定位,简化多轨道编辑、转场设计等工作。
- 智能字幕生成:同步识别语音内容并生成带时间戳的字幕,适用于无障碍访问和多语言适配。
- 创意脚本生成:根据主题提示自动生成包含标题、开场钩子、镜头顺序在内的完整分镜脚本,助力内容构思。




























