







传统强化学习(rl)在具备明确答案的任务中,如数学解题、代码生成等领域已取得显著进展。然而,在需要主观判断与创造性表达的开放任务中,例如创意写作或情感对话,由于缺乏统一的评判标准,传统 rl 方法难以施展拳脚。如何让强化学习突破“可验证奖励”的限制,迈向更复杂的主观世界?蚂蚁技术研究院联合浙江大学推出全新强化学习范式——rubicon,并正式开源其成果 rubicon-preview 模型,为这一难题提供了创新解决方案。
自 OpenAI o1 系列模型引领潮流以来,“基于可验证奖励的强化学习”(RLVR)已成为提升大模型推理能力的核心路径。通过大量客观任务训练,AI 在有标准答案的领域表现卓越。
但这也暴露出当前技术的局限:当面对没有唯一正确答案、依赖人类感知与审美的开放式任务时,AI 显得力不从心。
如何让 AI 写出打动人心的文字,而非千篇一律的“AI 腔”?如何激发它进行真正有想象力的构思,而不是堆砌已有信息?这些正是通向更高阶智能必须跨越的关键门槛。
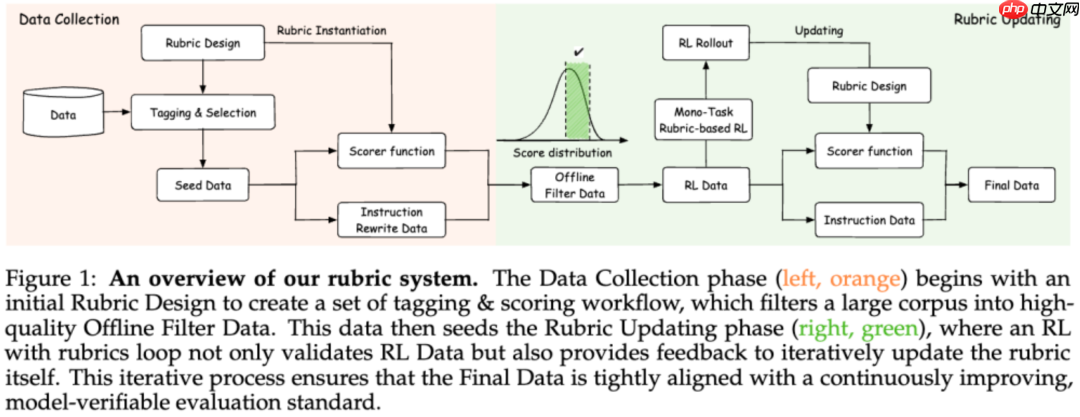
为此,蚂蚁技术研究院与浙江大学携手发布 Rubicon-preview 模型,提出一种全新的学习框架——“基于评分标尺的强化学习”(Rubric-based Reinforcement Learning),首次系统性地将人类对主观内容的偏好转化为可量化的训练信号,为 AI 注入更具人性化的创造力。
 论文标题:Reinforcement Learning with Rubric Anchors论文地址:https://www.php.cn/link/68b550d21bf148b92cc007171305afb1: https://www.php.cn/link/6fe3ec8f08093fb71744041532af3382”
论文标题:Reinforcement Learning with Rubric Anchors论文地址:https://www.php.cn/link/68b550d21bf148b92cc007171305afb1: https://www.php.cn/link/6fe3ec8f08093fb71744041532af3382”
不同于传统强化学习依赖二元化的对错反馈,Rubicon 的核心理念是放弃追求唯一的“正确输出”,转而教会模型理解多层次的“评分准则”(Rubric)。名称“Rubicon”源自 RUBrIC aNchOrs —— 即以评分规则作为锚点,帮助模型在模糊、多变的主观空间中稳定导航。
为了实现这一目标,研究团队构建了目前业内规模最大、覆盖最广的 Rubric 知识库,包含超过 10,000 条精细设计的评分标准,涵盖创意写作、情感表达、叙事结构等多个维度。这些标准将人类评委在文学创作、心理对话等场景中的隐性偏好显性化,首次大规模实现了主观评价的可计算化。
这不仅是一次数据规模的跃升,更是对强化学习奖励机制的根本重构,极大拓展了其适用边界。
 Rubicon-preview 模型核心优势
Rubicon-preview 模型核心优势
1. 小样本大成效:5000 样本即超越超大规模模型
实验证明,仅使用 5000 多个训练样本,团队训练出的 30B 参数模型 Rubicon-preview 在多个开放式人文任务上实现 +5.2% 的绝对性能提升,甚至反超参数高达 671B 的 DeepSeek-V3 模型。

这一结果凸显了“规模化评分标准”(Scaling Rubrics)的巨大潜力,有望减少 AI 对海量标注数据的依赖,推动高效、低成本的模型进化。
 2. 打破机械感:实现细腻风格控制,语言更有温度
2. 打破机械感:实现细腻风格控制,语言更有温度
得益于 Rubric 的精细化引导,模型展现出前所未有的表达灵活性和风格掌控力。
面对情感类问题,传统模型常回应“我没有情绪”这类程式化语句,而 Rubicon-preview 能够生成富有共情力、具故事性的回答,语言更加自然、贴近人类表达习惯。
3. 兼顾理性与感性:破解创意与推理的“此消彼长”
长期以来,增强模型的创意能力往往导致逻辑推理能力下降,形成所谓的“跷跷板效应”。Rubicon 采用多阶段协同训练策略,有效平衡两者需求。
结果显示,在大幅提升主观任务表现的同时,模型在 AIME 等数学推理基准测试中也保持稳定进步,真正实现了感性创造与理性思维的同步成长。
 结语
结语
蚂蚁技术研究院与浙江大学团队表示,此次开源不仅是发布一个高性能模型,更重要的是向全球社区贡献一套可复用的强化学习新范式及底层基础设施。他们相信,未来的 AI 不仅要聪明,更要懂得人心。一个能理解情感、激发创意的智能时代正在加速到来,期待更多开发者加入这场探索之旅。





























