
在谷歌gemini 3强势反超仅半个月后,openai迅速发起首轮回击——将原定计划中的gpt-5.2发布时间大幅提前至12月9日。而距离其前代版本gpt-5.1的亮相,尚不足一个月。
这一节奏折射出当前全球AI大模型赛道已进入前所未有的高强度竞速阶段:一方面,技术迭代速度远超早期市场预期;另一方面,在Scaling Law(规模法则)持续生效的逻辑驱动下,单一大模型所需的训练算力正以指数级攀升。双重因素叠加,令全球算力基础设施的爆发式增长仍处于加速通道,远未见顶。
近期,瑞银与高盛相继上调AI算力基础设施及相关硬件厂商的增长预测。瑞银指出,头部云服务商的大规模资本开支投入至少将持续至2027年。在此背景下,联想集团等深度绑定国内外主流云厂商、兼具核心技术壁垒与高客户粘性的硬件供应商,不仅充分享受行业整体扩容红利,更在市场份额上展现出显著提升势头。
大模型博弈升级,算力链率先受益
谷歌Gemini 3的成功,被业界广泛视为“Scaling Law极致实践”的典范。所谓规模法则,即模型性能随参数量、训练数据规模及计算资源投入呈幂律式增长。Gemini 3以实证方式重申了该规律的长期有效性,有力驳斥了此前关于“大模型逼近能力天花板”的悲观判断。
对模型研发方而言,这进一步强化了“以算力换性能”的战略共识——与其被动等待颠覆性架构突破,不如主动加码训练资源,持续拉高性能基线。例如,DeepSeek在发布V3.2与Speciale版本后即在技术报告中明确表示:“受限于总训练FLOPs规模,DeepSeek-V3.2在世界知识广度上仍落后于领先闭源模型。后续我们将通过扩大预训练算力投入,系统性弥补这一差距。”
对算力产业链而言,这意味着参数规模、数据体量与计算资源三者的扩张周期仍在延续。仅就参数维度看,业内普遍预计下一代主流模型将迈入10万亿参数时代。据中信建投测算,一次千亿参数模型的完整训练需消耗价值逾千万美元的算力资源;而10万亿级模型的训练成本与资源需求,无疑将跃升至全新量级。
Gemini 3对算力生态的影响,远不止于刺激需求。长期以来,OpenAI凭借技术先发优势与产品成熟度占据市场主导地位,Gemini 3的横空出世则实质性打破了这一格局。“双雄并立”态势倒逼OpenAI全面提速模型演进节奏。有消息称,为确保新模型如期发布并稳固技术领导力,OpenAI甚至暂停了广告平台、智能Agent及Pulse等多项业务线推进,将核心资源全部聚焦于即将面世的新一代模型。
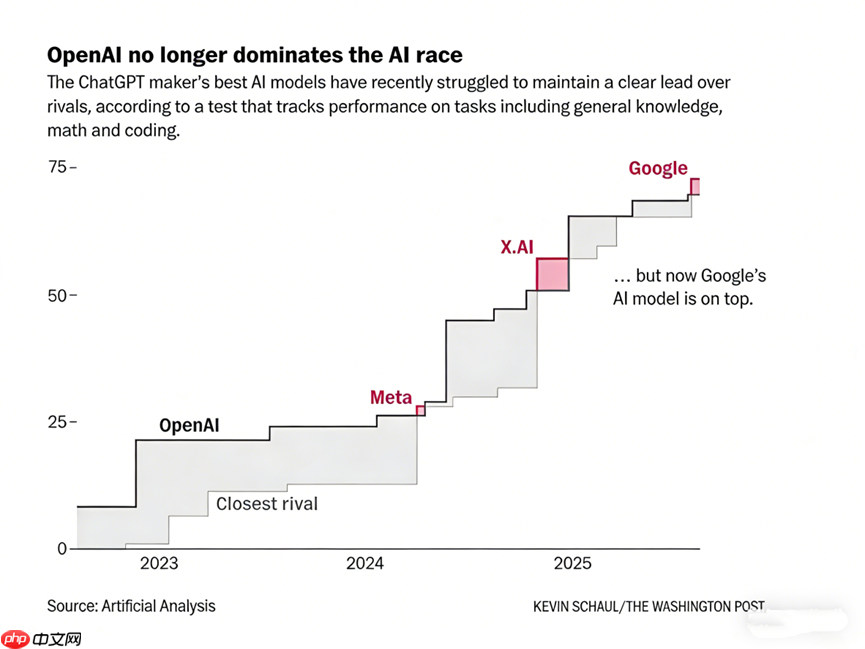
更深远的影响在于,“加速效应”正快速向全行业扩散。尤其在全球大模型技术代差持续收窄的当下,更多挑战者正加速涌现:Anthropic最新推出的Claude Opus 4.5已在编程能力维度全面超越Gemini 3 Pro与GPT-5.1;阿里千问发布的视觉大模型Qwen3-VL与Qwen2.5-VL,则在空间智能任务中实现对竞品的领先。有分析指出,在这种高频次、多点位的“密集反超”趋势下,AI模型发展正从“线性演进”迈向“指数跃迁”,行业整体已步入“周级迭代”的爆发临界点。
正是“算力驱动性能跃升+迭代节奏持续加速”的双重引擎,不断刷新算力产业增长曲线。12月5日,瑞银最新深度研报显示,北美、欧洲及亚太地区数据中心空置率分别维持在1.8%、3.6%和5.8%,均处于历史低位,供需失衡格局清晰可见。结合强劲的在建项目储备与极低空置水平,瑞银正式上调该领域中期增长预期,预计2026年涵盖电力供应、散热系统及IT设备在内的整体市场增速将达20%-25%。

从企业端观察,作为全球AI算力基础设施核心硬件提供商,联想集团最新财报表现全面超出市场一致预期。其中,专注AI算力基础设施的ISG业务集团营收达293亿元,同比增长24%,较里昂证券上调后的预测值仍高出一截。依托“云服务商(CSP)+企业级客户(E/SMB)”双轨并进战略,联想ISG同步承接大模型训练侧与应用落地侧的双重增长红利。其“一横四纵”全栈布局——“一横”指万全异构智算方案,“四纵”覆盖服务器、存储、数据网络、软件及超融合系统——是国内覆盖最完整的AI算力解决方案体系,可提供端到端交付能力,并借力“全球资源、本地交付”的韧性供应链,高效响应全球各地差异化、本地化需求,从而牢牢把握行业加速窗口。
对于联想集团未来展望,高盛认为,随着生成式AI渗透率持续提升,公司在AI基础设施及边缘AI设备领域的成长动能将进一步释放,故将2026至2028财年收入预测整体上调1%-2%。
放眼长远,据瑞银全球科技与AI大会纪要披露,一线科技企业普遍认同:AI产业正处于一个“十年超级周期”的第二年,其底层驱动力呈现出“永不饱和、持续攀升”的鲜明特征。这意味着,无论是算力基础设施行业的整体高景气,还是联想集团等头部参与者的超预期增长,都仍处于上升通道的早期阶段。
技术护城河与客户黏性:硬件竞争的双重支点
值得特别关注的是,Gemini 3完全依托谷歌自研TPU集群完成训练,真正实现了从芯片、算力平台到大模型的全栈垂直整合。更关键的是,谷歌已开始将TPU作为英伟达GPU的替代方案推向第三方市场。
与此同时,亚马逊于12月2日正式发布第三代定制AI芯片Trainium 3,并明确将以云服务形式向企业客户规模化输出算力,对英伟达与谷歌同步发起挑战。
从英伟达“一家独大”,到谷歌、亚马逊强势入局形成“三国鼎立”,底层AI芯片格局的重构,或将逐步削弱英伟达的议价能力,进而降低上游硬件厂商的采购成本——但这只是长期影响。对硬件供应商而言,更具现实意义的信号在于:相较英伟达GPU在通用性、CUDA生态及灵活性方面的传统优势,谷歌TPU与亚马逊Trainium系列所展现的深度定制化能力正日益凸显。而这种“按需匹配”的适配逻辑,不会止步于芯片层,亦将深刻重塑整机系统、服务器架构乃至散热方案的设计范式。
尤其在大模型性能趋同、应用场景加速落地的双重背景下,模型差异化竞争与场景个性化需求,将持续强化对硬件定制化能力的要求。

以联想集团与亚马逊的合作为例,双方在AWS定制化服务器领域已建立深度协同。这些专为AWS云平台优化的服务器,不仅为其基础设施提供高稳定性硬件支撑,合作范围更已延伸至AI训练服务器等前沿领域。
此类深度定制模式,使更换供应商面临系统集成适配、历史数据迁移、工程师技能重构、软硬兼容性验证等一系列隐性成本与漫长周期,同时可能波及系统稳定性、运行可靠性与数据安全性。因此,云服务商通常不会轻易切换硬件伙伴,行业天然具备强客户黏性。目前,联想集团已成功进入全球十大云服务商中的七家供应链,并全部实现长期、稳固合作。
而定制化能力的背后,是扎实的技术壁垒支撑。例如,联想为亚马逊定制服务器所搭载的“海神”液冷技术,可降低数据中心整体功耗达40%,已成为高密度机柜的标准配置。尤其在英伟达新一代Rubin架构下,单颗GPU热设计功耗(TDP)飙升至2300W,整柜功率逼近200KW,对散热系统的极限能力提出全新挑战。联想今年集中发布的“飞鱼”仿生散热设计与“双循环”相变浸没制冷系统,进一步夯实了其在先进散热领域的技术护城河。
12月5日,联想集团重磅推出新一代高端大模型训练AI服务器——基于英特尔®至强®6处理器的联想问天WA8080aG5,以及全面升级的联想万全异构智算平台4.0。该发布恰逢Gemini 3与GPT-5.2在参数指标上激烈“贴身缠斗”,且英伟达、谷歌、亚马逊三方芯片格局初现、引发市场高度关注之际。不难推断,此举正是联想集团对AI大模型训练范式演进趋势的精准预判与快速响应。

根据联想集团2025/26财年第二季度财报,公司AI服务器业务实现高双位数收入增长,“海神”液冷技术相关业务收入同比激增154%,进一步巩固其在绿色节能AI基础设施领域的领先地位。这一成果,与其在技术洞察力、响应敏捷性及客户协同深度等方面的持续强化密不可分。换言之,在大模型竞争日趋白热化的当下,唯有像联想集团这样兼具前瞻视野、执行效率与生态协同能力的AI基础设施硬件提供商,才能持续筑牢技术壁垒、深化客户绑定,并在市场份额争夺中赢得更大主动权。
随着GPT-5.2等主流模型加速迭代节奏不断加快,中信建投分析指出,AI产业链已正式迈入“算力定义上限”的核心竞争阶段,全球科技巨头向AI倾斜的资本开支趋势已不可逆转。在此确定性背景下,全球算力需求的增长动能仍将强劲延续,而联想集团这类兼具技术纵深、生态厚度与商业韧性的优势厂商,其成长空间亦将持续打开。
以上就是Gemini3触发AI格局剧变,算力产业链成最大受益者的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 206
206


















