







这篇文章主要介绍了详解python读取邮件数据并下载附件的实例的相关资料,这里提供实现实例,帮助大家学习理解这部分内容,需要的朋友可以参考下
详解python实现读取邮件数据并下载附件的实例
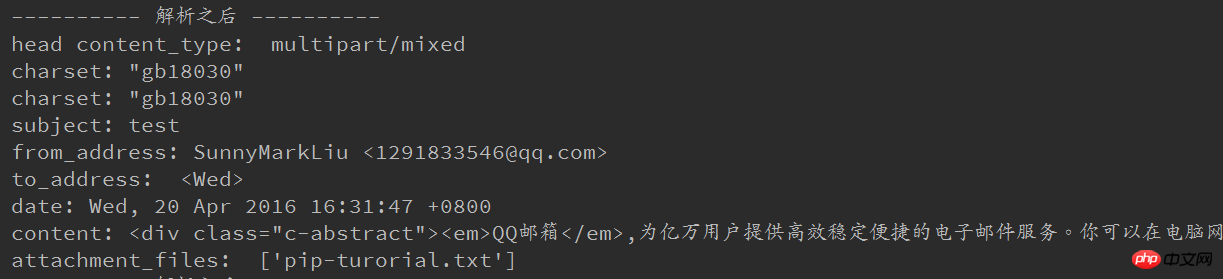
实现结果图:

实现代码:
立即学习“Python免费学习笔记(深入)”;
#!/usr/bin/python2.7
# _*_ coding: utf-8 _*_
"""
@Author: MarkLiu
"""
import poplib
import email
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
def guess_charset(msg):
# 先从msg对象获取编码:
charset = msg.get_charset()
if charset is None:
# 如果获取不到,再从Content-Type字段获取:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
def get_email_headers(msg):
# 邮件的From, To, Subject存在于根对象上:
headers = {}
for header in ['From', 'To', 'Subject', 'Date']:
value = msg.get(header, '')
if value:
if header == 'Date':
headers['date'] = value
if header == 'Subject':
# 需要解码Subject字符串:
subject = decode_str(value)
headers['subject'] = subject
else:
# 需要解码Email地址:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
if header == 'From':
from_address = value
headers['from'] = from_address
else:
to_address = value
headers['to'] = to_address
content_type = msg.get_content_type()
print 'head content_type: ', content_type
return headers
# indent用于缩进显示:
def get_email_cntent(message, base_save_path):
j = 0
content = ''
attachment_files = []
for part in message.walk():
j = j + 1
file_name = part.get_filename()
contentType = part.get_content_type()
# 保存附件
if file_name: # Attachment
# Decode filename
h = email.Header.Header(file_name)
dh = email.Header.decode_header(h)
filename = dh[0][0]
if dh[0][1]: # 如果包含编码的格式,则按照该格式解码
filename = unicode(filename, dh[0][1])
filename = filename.encode("utf-8")
data = part.get_payload(decode=True)
att_file = open(base_save_path + filename, 'wb')
attachment_files.append(filename)
att_file.write(data)
att_file.close()
elif contentType == 'text/plain' or contentType == 'text/html':
# 保存正文
data = part.get_payload(decode=True)
charset = guess_charset(part)
if charset:
charset = charset.strip().split(';')[0]
print 'charset:', charset
data = data.decode(charset)
content = data
return content, attachment_files
if __name__ == '__main__':
# 输入邮件地址, 口令和POP3服务器地址:
emailaddress = 'xxxxxx@163.com'
# 注意使用开通POP,SMTP等的授权码
password = 'xxxxxx'
pop3_server = 'pop.163.com'
# 连接到POP3服务器:
server = poplib.POP3(pop3_server)
# 可以打开或关闭调试信息:
# server.set_debuglevel(1)
# POP3服务器的欢迎文字:
print server.getwelcome()
# 身份认证:
server.user(emailaddress)
server.pass_(password)
# stat()返回邮件数量和占用空间:
messagesCount, messagesSize = server.stat()
print 'messagesCount:', messagesCount
print 'messagesSize:', messagesSize
# list()返回所有邮件的编号:
resp, mails, octets = server.list()
print '------ resp ------'
print resp # +OK 46 964346 响应的状态 邮件数量 邮件占用的空间大小
print '------ mails ------'
print mails # 所有邮件的编号及大小的编号list,['1 2211', '2 29908', ...]
print '------ octets ------'
print octets
# 获取最新一封邮件, 注意索引号从1开始:
length = len(mails)
for i in range(length):
resp, lines, octets = server.retr(i + 1)
# lines存储了邮件的原始文本的每一行,
# 可以获得整个邮件的原始文本:
msg_content = '\n'.join(lines)
# 把邮件内容解析为Message对象:
msg = Parser().parsestr(msg_content)
# 但是这个Message对象本身可能是一个MIMEMultipart对象,即包含嵌套的其他MIMEBase对象,
# 嵌套可能还不止一层。所以我们要递归地打印出Message对象的层次结构:
print '---------- 解析之后 ----------'
base_save_path = '/media/markliu/Entertainment/email_attachments/'
msg_headers = get_email_headers(msg)
content, attachment_files = get_email_cntent(msg, base_save_path)
print 'subject:', msg_headers['subject']
print 'from_address:', msg_headers['from']
print 'to_address:', msg_headers['to']
print 'date:', msg_headers['date']
print 'content:', content
print 'attachment_files: ', attachment_files
# 关闭连接:
server.quit() 




























