







标签传播算法是一种半监督机器学习算法,它将标签分配给以前未标记的数据点。要在机器学习中使用这种算法,只有一小部分示例具有标签或分类。在算法的建模、拟合和预测过程中,这些标签被传播到未标记的数据点。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

LabelPropagation
LabelPropagation是一种在图中查找社区的快速算法。它只使用网络结构作为指导来检测这些连接,不需要预定义的目标函数或关于群体的先验信息。标签传播通过在网络中传播标签并基于标签传播过程形成连接来实现。
接近的标签通常会被赋予相同的标签。单个标签可以在密集连接的节点组中占主导地位,但在稀疏连接的区域中会遇到麻烦。标签将被限制在一个紧密连接的节点组中,当算法完成时,那些最终具有相同标签的节点可以被视为同一连接的一部分。该算法使用了图论,具体如下:-
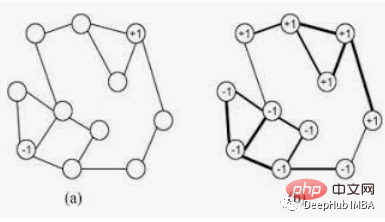
LabelPropagation算法以下列方式工作:-
- 每个节点都使用唯一的标签进行初始化。
- 这些标签通过网络传播。
- 在每次传播迭代中,每个节点都会将其标签更新为最大邻居数所属的标签。
- 当每个节点具有其邻居的多数标签时,标签传播算法达到收敛。
- 如果达到收敛或用户定义的最大迭代次数,则标签传播算法停止。
为了演示LabelPropagation算法的工作原理,们使用 Pima Indians 的数据集,创建程序时,我导入了运行它所需的库

复制一份数据并且将lable列作为训练目标

使用matplotlib可视化:

使用随机数生成器随机化数据集中70%的标签。然后随机标签被分配-1:-
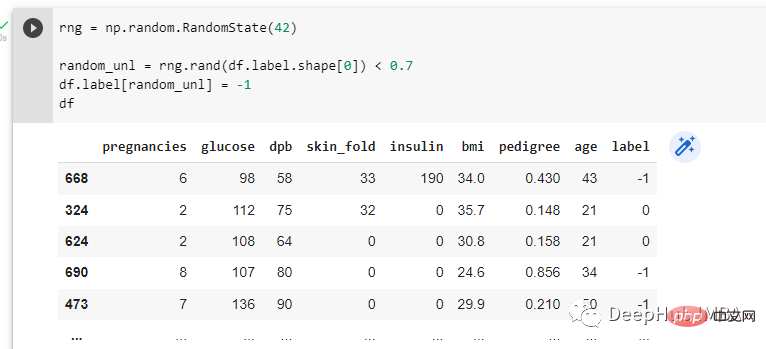
在对数据进行预处理之后,定义因变量和自变量,分别为y和X。y变量是最后一列,X变量是剩下的所有部分:-

使用sklearn的LabelPropagation数来标记所有未标记的数据点:-

准确率为发现它是76.9%。

下面我们看看另外一个算法LabelSpreading。
LabelSpreading
LabelSpreading也是一种流行的半监督学习方法。创建一个连接训练数据集中样本的图,并通过图的边缘传播已知的标签来标记未标记的示例。
LabelSpreading是由 Dengyong Zhou 等人在他们 2003 年题为“Learning with Local and Global Consistency”的论文中提出的的。半监督学习的关键是一致性的先验假设,这意味着:附近的点可能具有相同的标签,并且同一结构上的点(通常称为簇流形)很可能具有相同的标签。
LabelSpreading可以认为是LabelPropagation的正则化形式。在图论中,拉普拉斯矩阵是图的矩阵表示,拉普拉斯矩阵的公式为:

L是拉普拉斯矩阵,D是度矩阵,A是邻接矩阵。

下面是一个简单的无向图标记的例子和它拉普拉斯矩阵的结果

本文将使用sonar数据集演示如何使用sklearn的LabelSpreading函数。
这里的库比上面的多,所以简单解释一下:
- Numpy执行数值计算并创建Numpy数组
- Pandas处理数据
- Sklearn执行机器学习操作
- Matplotlib和seaborn来可视化数据,为可视化数据提供统计信息
- Warning,用于忽略程序执行期间出现的警告
导入完成后使用pandas将读入数据集:

我使用seaborn创建了热图:-

先做一个就简单的预处理,删除具有高度相关性的列,这样将列数从 61 减少到 58:

然后对数据进行打乱重排,这样在打乱的数据集中预测通常更准确,复制一个数据集的副本,并将 y_orig 定义为训练目标:

使用matplotlib来绘制数据点的2D散点图:-

使用随机数生成器随机化数据集中60%的标签。然后随机标签被分配-1:-

在对数据进行预处理之后,定义因变量和自变量,分别为y和X。y变量是最后一列,X变量是剩下的所有部分:-

然后使用sklearn的LabelSpreading算法对未标记的行进行训练和预测。
使用这种方法,能够达到87.98%的准确率:-

简单对比
1、labelspreading中含有alpha=0.2,alpha称为夹紧系数,指的是采用其邻居的信息而不是其初始标签的相对量,若为0,表示保留初始标签信息,若为1,表示替换所有初始信息;设置alpha=0.2,意味着始终保留80%的原始标签信息;
2、labelpropagation使用从数据中构造的原始相似矩阵,不做修改;labelspreading最小化具有正则化特性的损失函数,对噪声更加稳健,迭代了原始图的修改版,并通过计算归一化拉普拉斯矩阵来标准化边权重。
3、同时LabelSpreading非常占用CPU,物理内存占用率还好;LabelPropagation 的CPU占用率还好,非常占用物理内存,高纬度数据可能会有一些问题。




























