随着远程医疗的兴起,患者越来越倾向于选择在线问诊和咨询,以寻求便捷高效的医疗支持。最近,大型语言模型(llm)展示出了强大的自然语言交互能力,给健康医疗助手走进人们的生活带来了希望
医疗健康咨询场景通常较为复杂,个人助手需要有丰富的医学知识,具备通过多个轮次对话了解病人意图,并给出专业、详实回复的能力。通用语言模型在面对医疗健康咨询时,往往因为缺乏医疗知识,出现避而不谈或者答非所问的情况;同时,倾向于针对当前轮次问题完成咨询,缺少令人满意的多轮追问能力。除此之外,当前高质量的中文医学数据集也十分难得,这为训练强大的医疗领域语言模型构成了挑战。复旦大学数据智能与社会计算实验室(FudanDISC)发布中文医疗健康个人助手 ——DISC-MedLLM。在单轮问答和多轮对话的医疗健康咨询评测中,模型的表现相比现有医学对话大模型展现出明显优势。课题组同时公开了包含 47 万高质量的监督微调(SFT)数据集 ——DISC-Med-SFT,模型参数和技术报告也一并开源。
- 主页地址:https://med.fudan-disc.com
- Github 地址:https://github.com/FudanDISC/DISC-MedLLM
- 技术报告:https://arxiv.org/abs/2308.14346
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

患者感到身体不适时,可以向模型问诊,描述自身症状,模型会给出可能的病因、推荐的治疗方案等作为参考,在信息缺乏时会主动追问症状的详细描述。
用户还可以基于自身健康状况,向模型提出需求明确的咨询问题,模型会给予详尽有助的答复,并在信息缺乏时主动追问,以增强回复的针对性和准确性。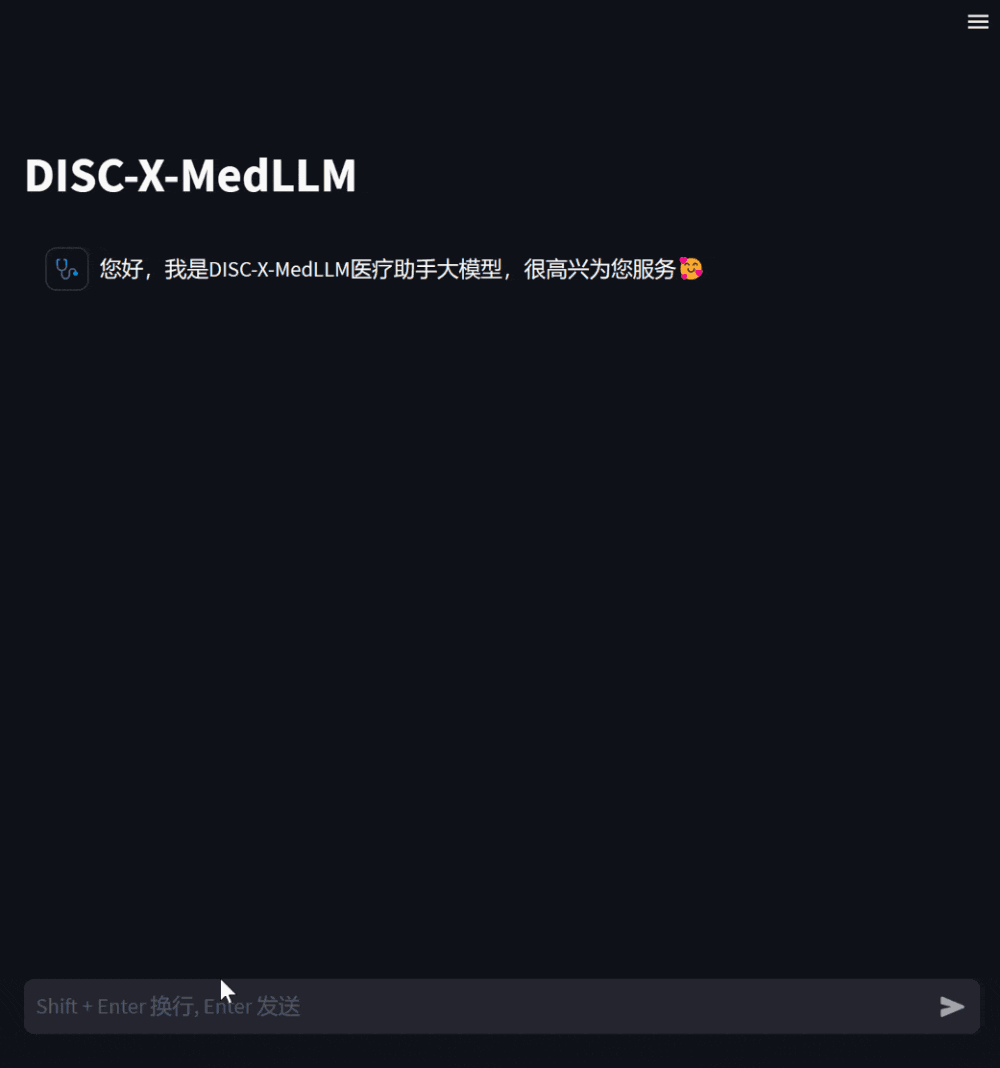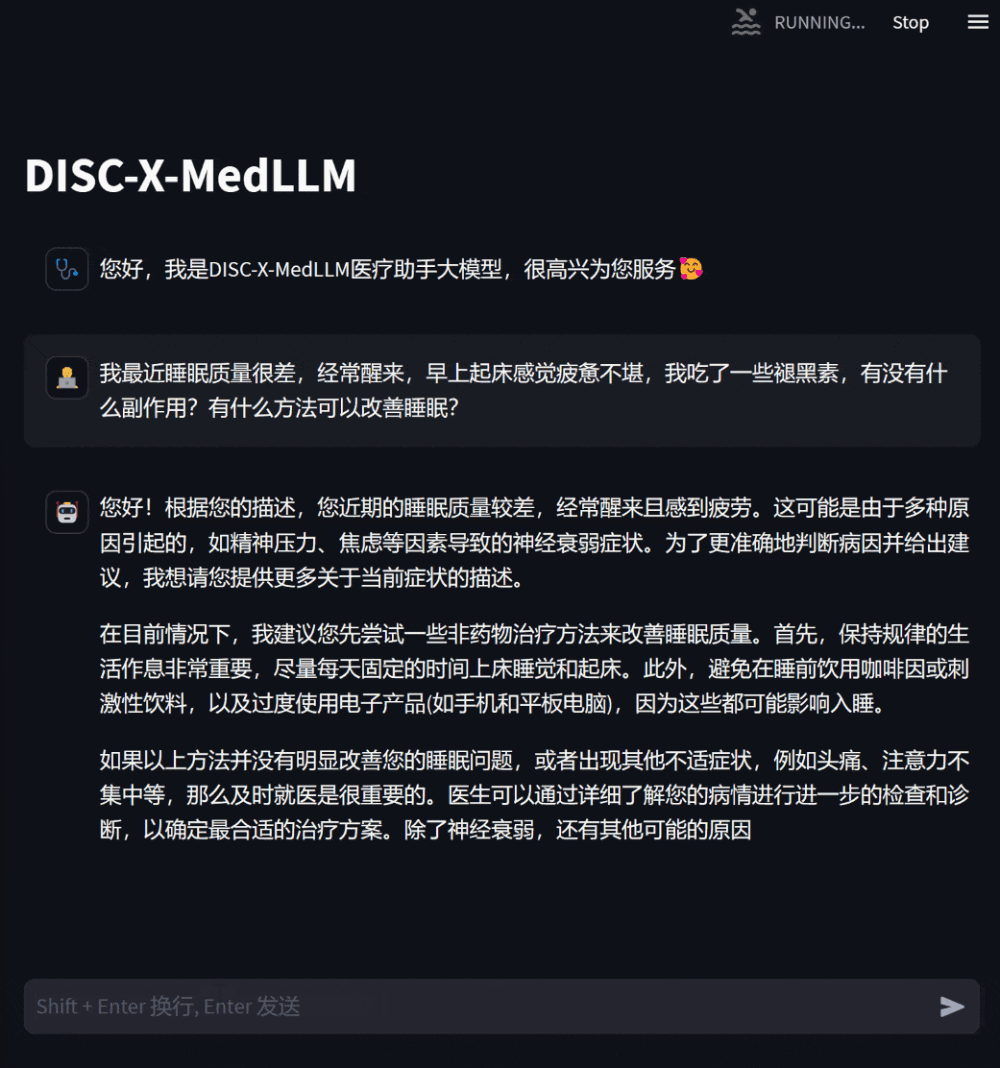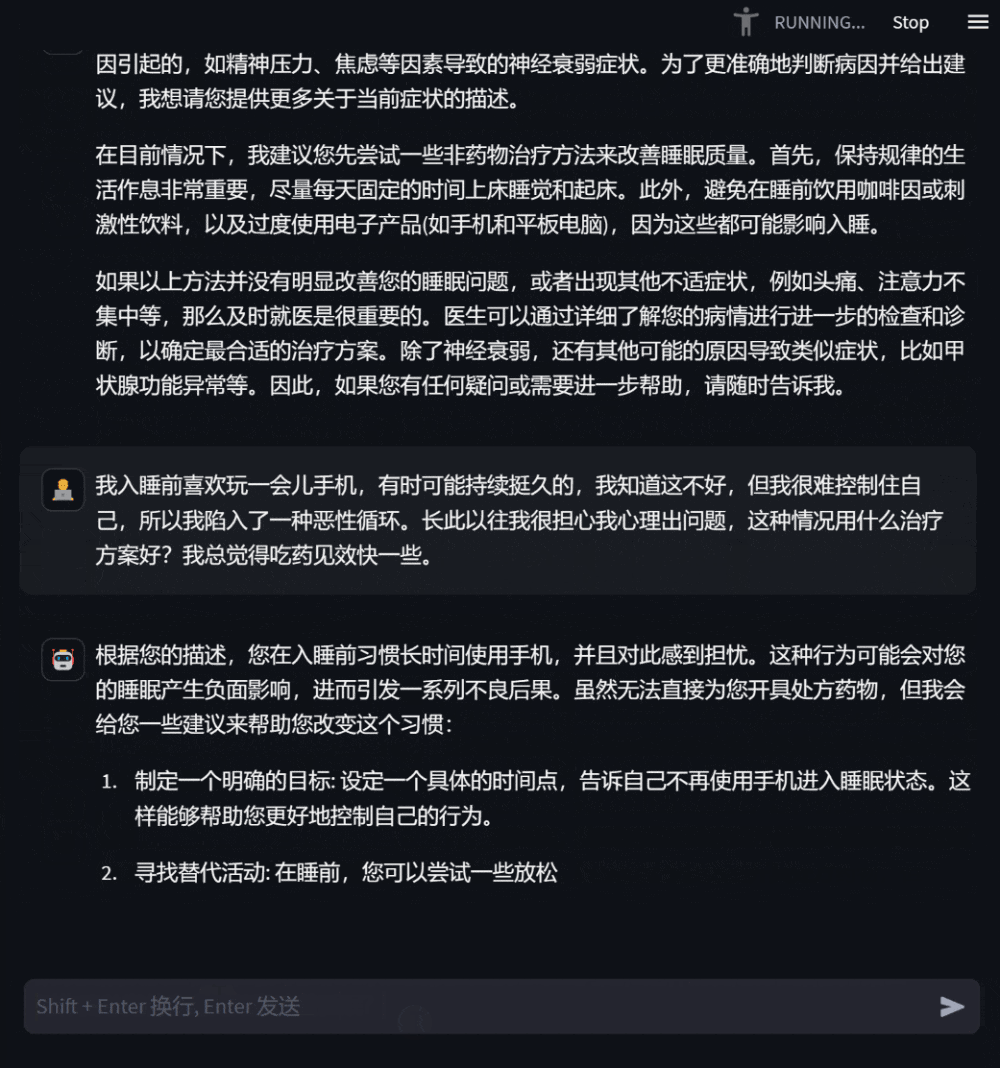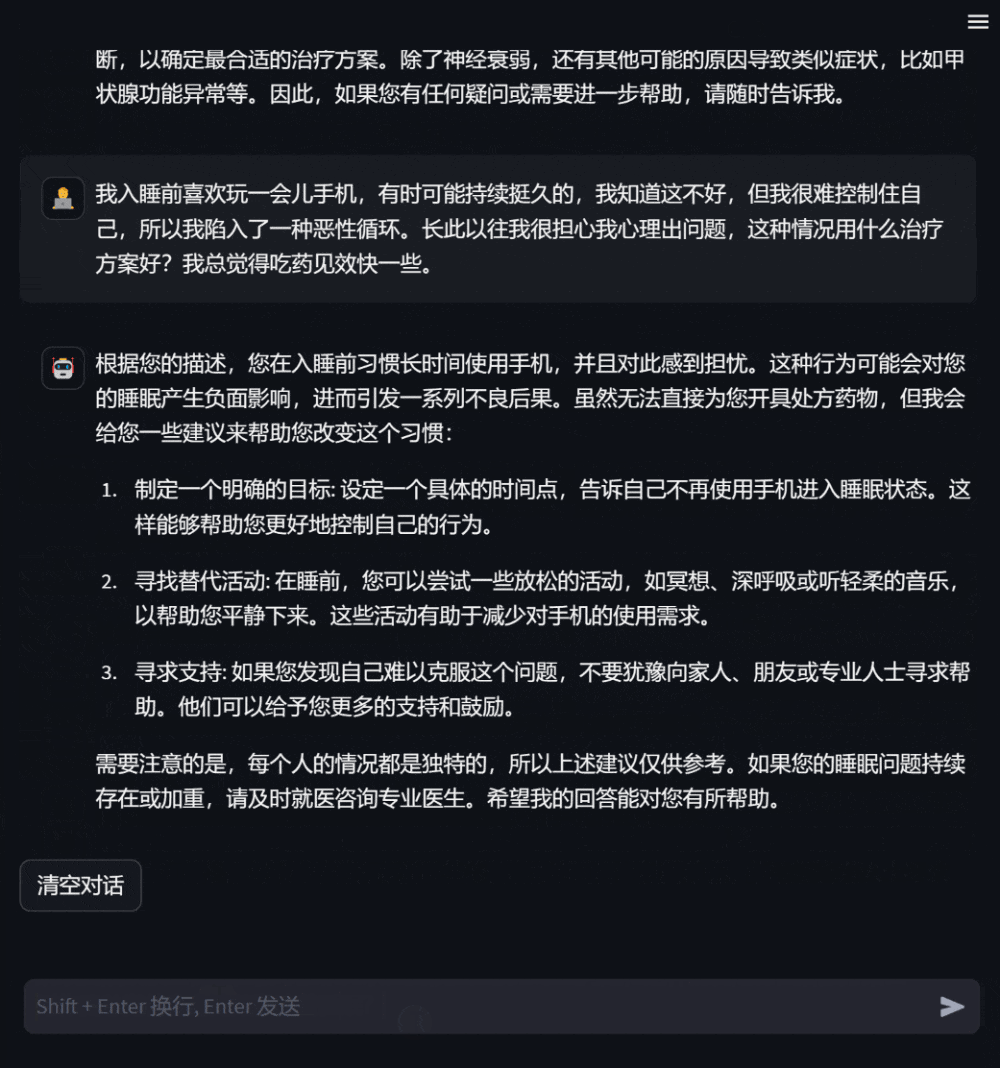
用户还可以询问与自身无关的医学知识,此时模型会尽可能专业地作答,使用户全面准确地理解。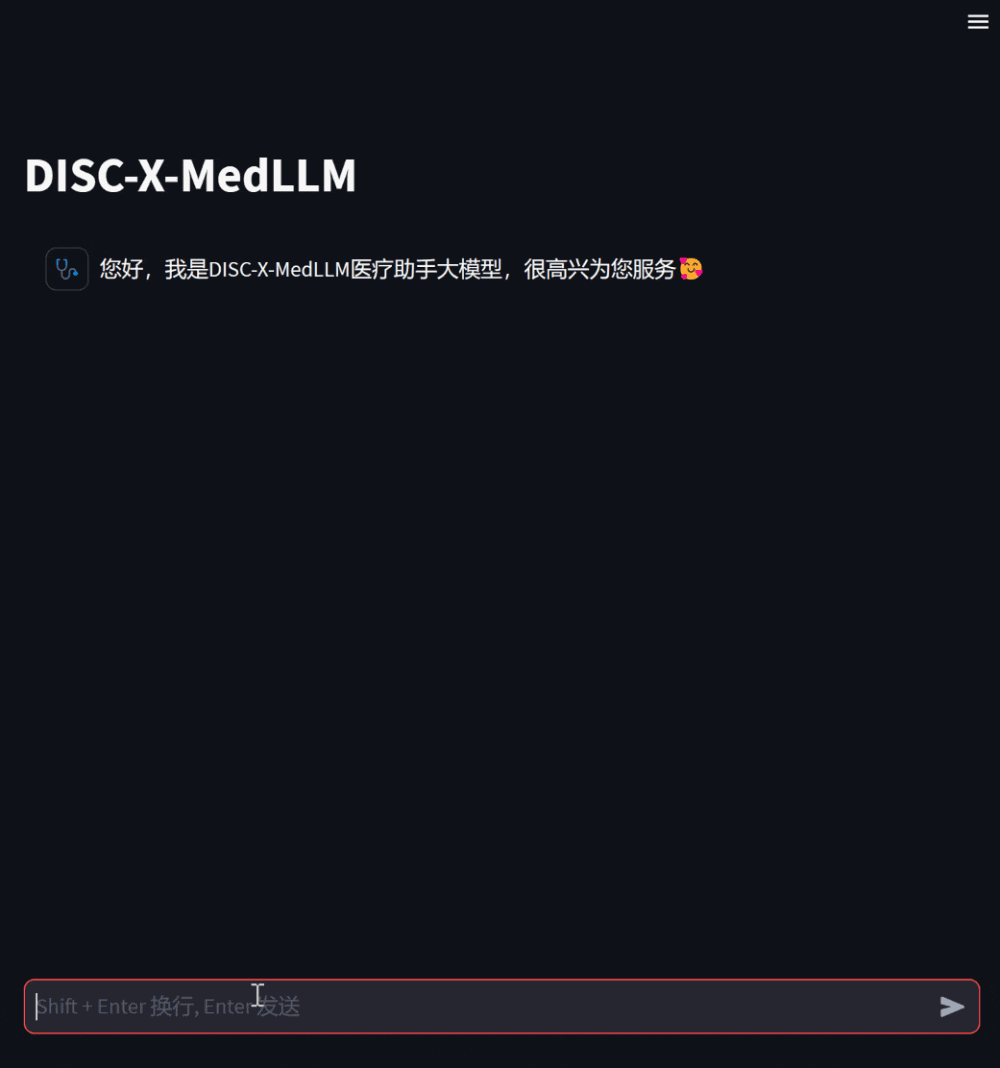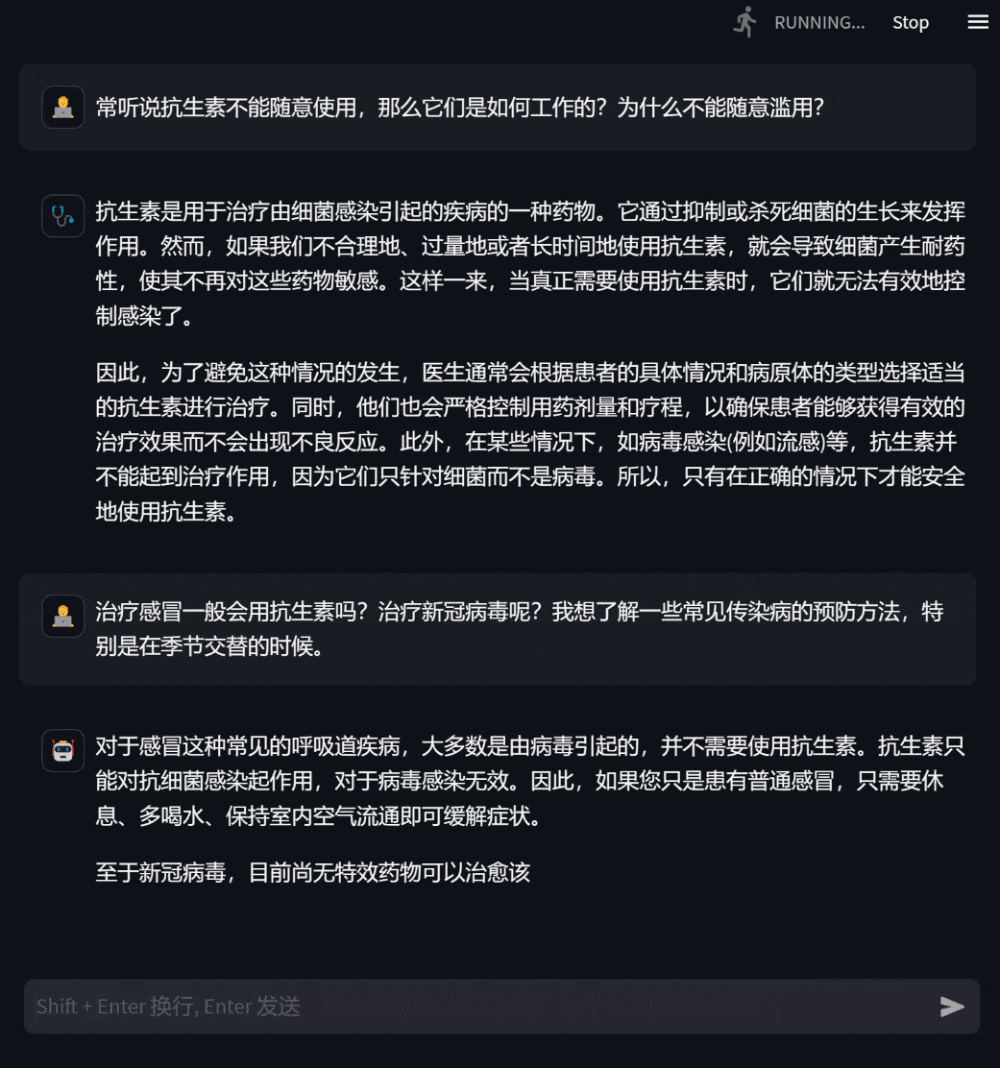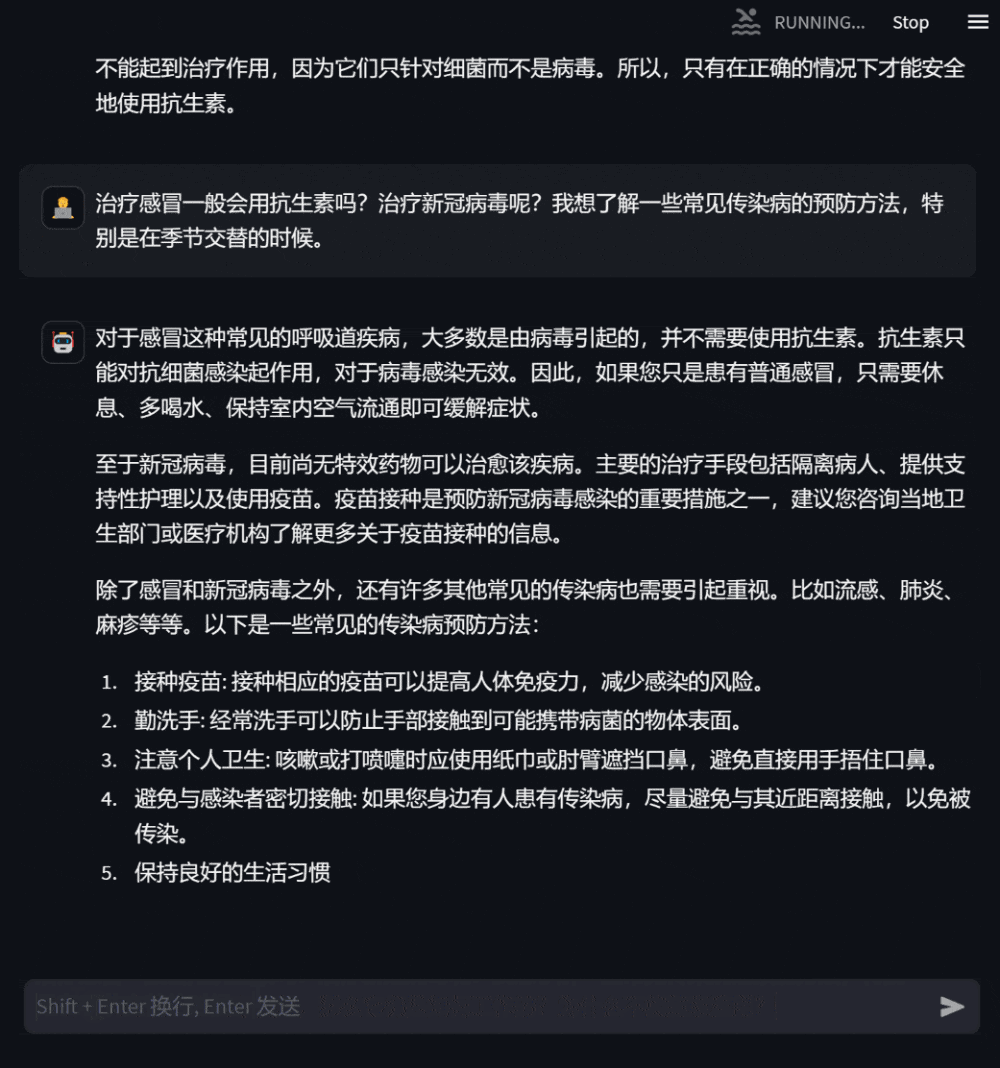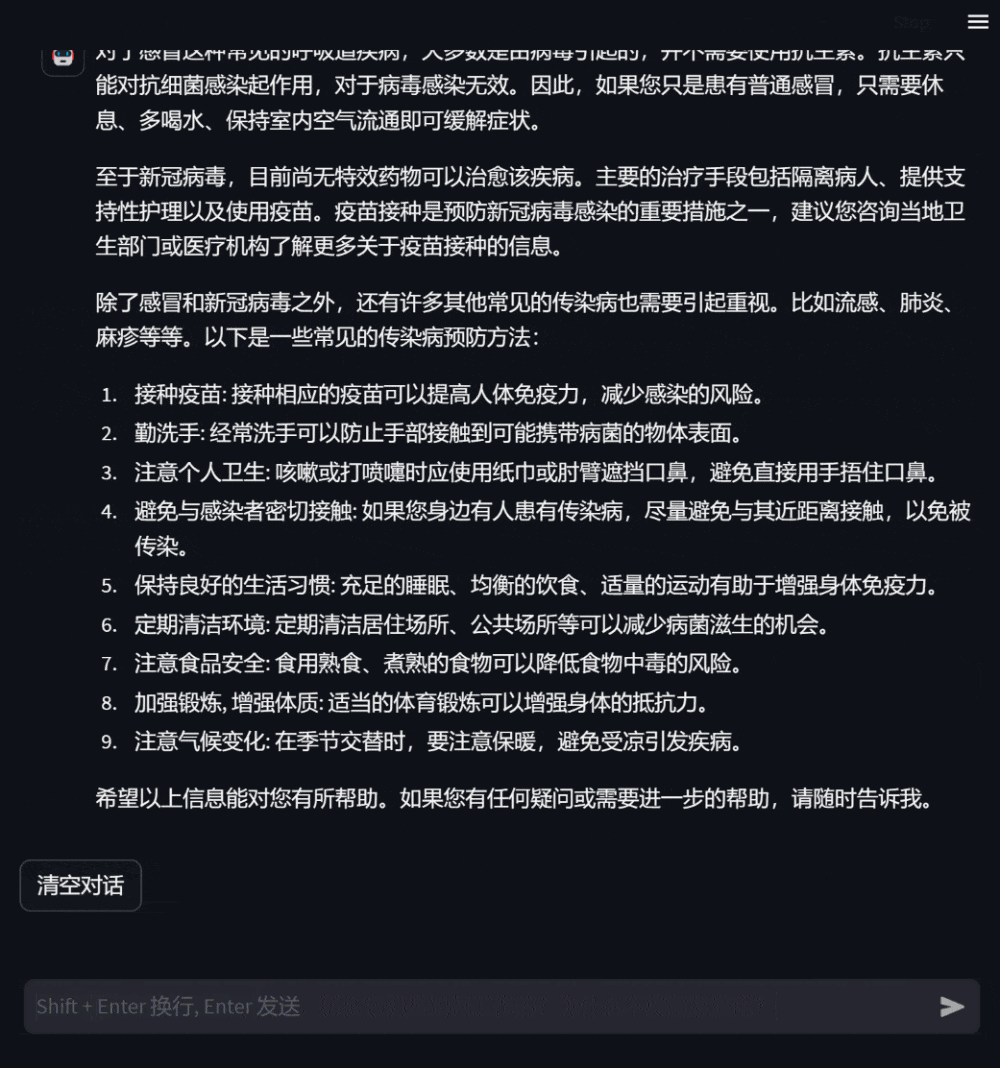
DISC-MedLLM 是基于我们构建的高质量数据集 DISC-Med-SFT 在通用领域中文大模型 Baichuan-13B 上训练得到的医疗大模型。值得注意的是,我们的训练数据和训练方法可以被适配到任何基座大模型之上。
- 可靠丰富的专业知识。我们以医学知识图谱作为信息源,通过采样三元组,并使用通用大模型的语言能力进行对话样本的构造。
- 多轮对话的问询能力。我们以真实咨询对话纪录作为信息源,使用大模型进行对话重建,构建过程中要求模型完全对齐对话中的医学信息。
- 对齐人类偏好的回复。病人希望在咨询的过程中获得更丰富的支撑信息和背景知识,但人类医生的回答往往简练;我们通过人工筛选,构建高质量的小规模指令样本,对齐病人的需求。
模型的优势和数据构造框架如图 5 所示。我们从真实咨询场景中计算得到病人的真实分布,以此指导数据集的样本构造,基于医学知识图谱和真实咨询数据,我们使用大模型在回路和人在回路两种思路,进行数据集的构造。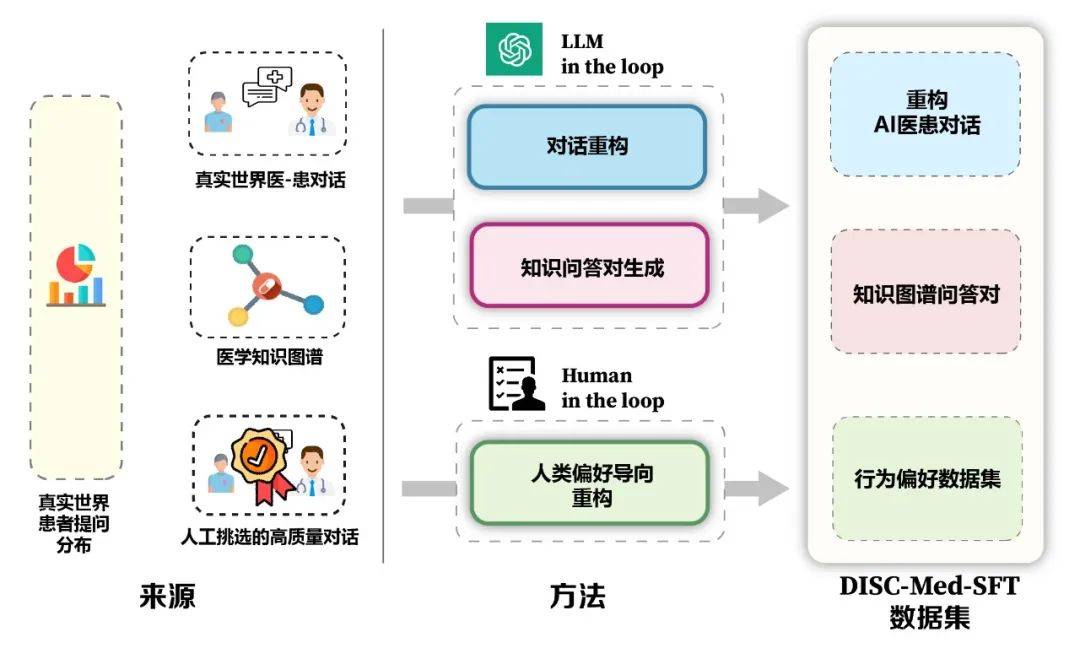
3、方法:数据集 DISC-Med-SFT 的构造在模型训练的过程中,我们向 DISC-Med-SFT 补充了通用领域的数据集和来自现有语料的数据样本,形成了 DISC-Med-SFT-ext,详细信息呈现在表 1 中。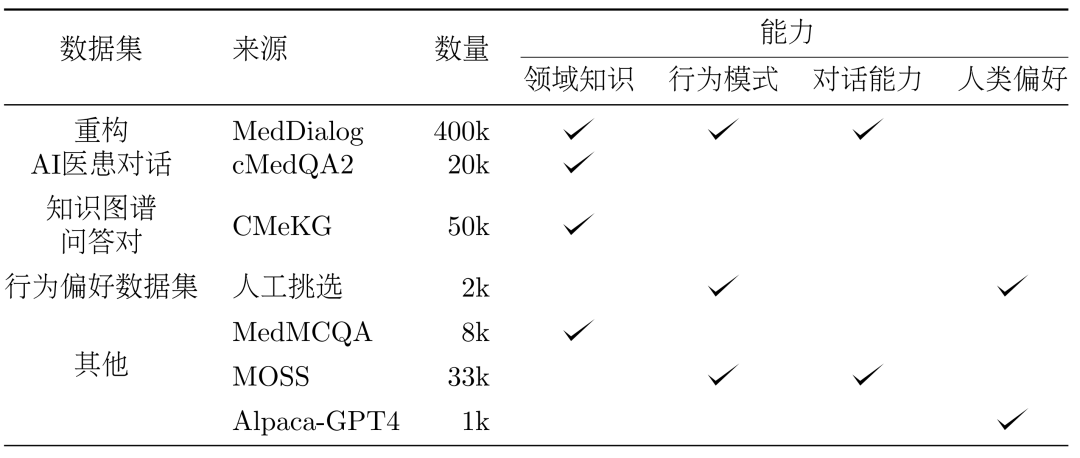
表 1:DISC-Med-SFT-ext 数据内容介绍数据集。分别从两个公共数据集 MedDialog 和 cMedQA2 中随机选择 40 万个和 2 万个样本,作为 SFT 数据集构建的源样本。重构。为了将真实世界医生回答调整为所需的高质量的统一格式的回答,我们利用 GPT-3.5 来完成这个数据集的重构过程。提示词(Prompts)要求改写遵循以下几个原则:
- 去除口头表达,提取统一表达方式,纠正医生语言使用中的不一致之处。
- 坚持原始医生回答中的关键信息,并提供适当的解释以更加全面、合乎逻辑。
- 重写或删除 AI 医生不应该发出的回复,例如要求患者预约。
图 6 展示了一个重构的示例。调整后医生的回答与 AI 医疗助手的身份一致,既坚持原始医生提供的关键信息,又为患者提供更丰富全面的帮助。

知鹿匠
知鹿匠教师AI工具,新课标教案_AI课件PPT_作业批改
下载
医学知识图谱包含大量经过良好组织的医学专业知识,基于它可以生成噪声更低的 QA 训练样本。我们在 CMeKG 的基础上,根据疾病节点的科室信息在知识图谱中进行采样,利用适当设计的 GPT-3.5 模型 Prompts,总共生成了超过 5 万个多样化的医学场景对话样本。在训练的最终阶段,为了进一步提高模型的性能,我们使用更符合人类行为偏好数据集进行次级监督微调。从 MedDialog 和 cMedQA2 两个数据集中人工挑选了约 2000 个高质量、多样化的样本,在交给 GPT-4 改写几个示例并人工修订后,我们使用小样本的方法将其提供给 GPT-3.5,生成高质量的行为偏好数据集。通用数据。为了丰富训练集的多样性,减轻模型在 SFT 训练阶段出现基础能力降级的风险,我们从两个通用的监督微调数据集 moss-sft-003 和 alpaca gpt4 data zh 随机选择了若干样本。MedMCQA。为增强模型的问答能力,我们选择英文医学领域的多项选择题数据集 MedMCQA,使用 GPT-3.5 对多项选择题中的问题和正确答案进行了优化,生成专业的中文医学问答样本约 8000 个。训练。如下图所示,DISC-MedLLM 的训练过程分为两个 SFT 阶段。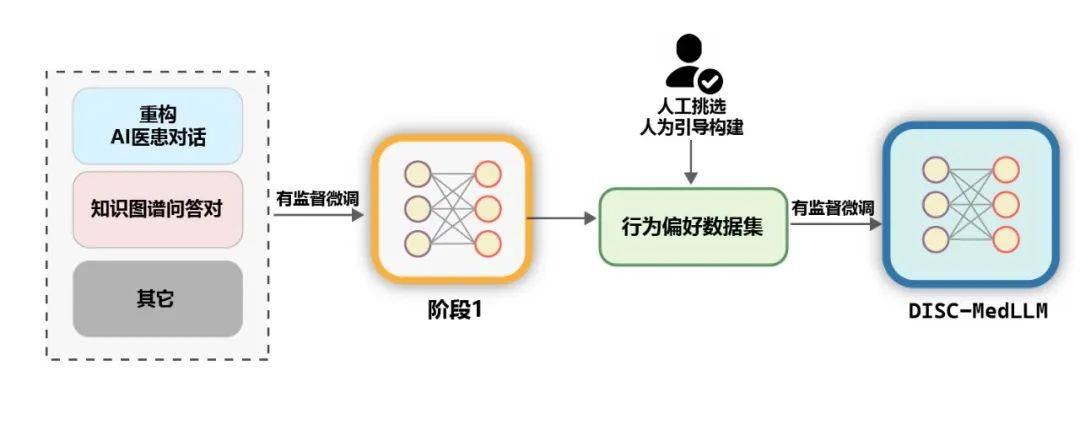
评测。在两个场景中评测医学 LLMs 的性能,即单轮 QA 和多轮对话。
- 单轮 QA 评测:为了评估模型在医学知识方面的准确性,我们从中国国家医疗执业医师资格考试(NMLEC)和全国硕士研究生入学考试(NEEP)西医 306 专业抽取了 1500 + 个单选题,评测模型在单轮 QA 中的表现。
- 多轮对话评测:为了系统性评估模型的对话能力,我们从三个公共数据集 —— 中文医疗基准评测(CMB-Clin)、中文医疗对话数据集(CMD)和中文医疗意图数据集(CMID)中随机选择样本并由 GPT-3.5 扮演患者与模型对话,提出了四个评测指标 —— 主动性、准确性、有用性和语言质量,由 GPT-4 打分。
比较模型。将我们的模型与三个通用 LLM 和两个中文医学对话 LLM 进行比较。包括 OpenAI 的 GPT-3.5, GPT-4, Baichuan-13B-Chat; BianQue-2 和 HuatuoGPT-13B。单轮 QA 结果。单项选择题评测的总体结果显示在表 2 中。GPT-3.5 展现出明显的领先优势。DISC-MedLLM 在小样本设置下取得第二名,在零样本设置中落后于 Baichuan-13B-Chat,排名第三。值得注意的是,我们的表现优于采用强化学习设置训练的 HuatuoGPT (13B)。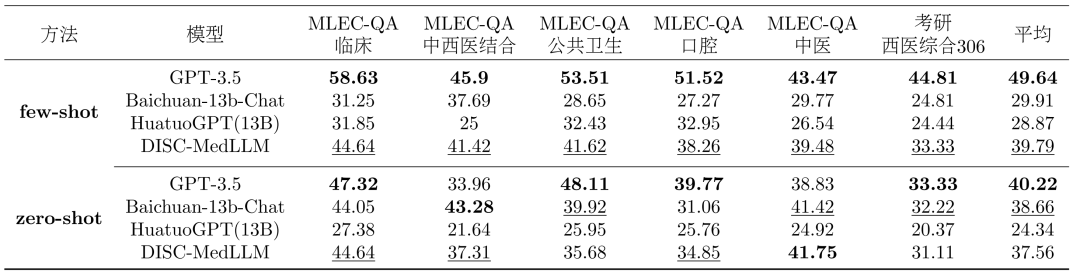
多轮对话结果。在 CMB-Clin 评估中,DISC-MedLLM 获得了最高的综合得分,HuatuoGPT 紧随其后。我们的模型在积极性标准中得分最高,凸显了我们偏向医学行为模式的训练方法的有效性。结果如表 3 所示。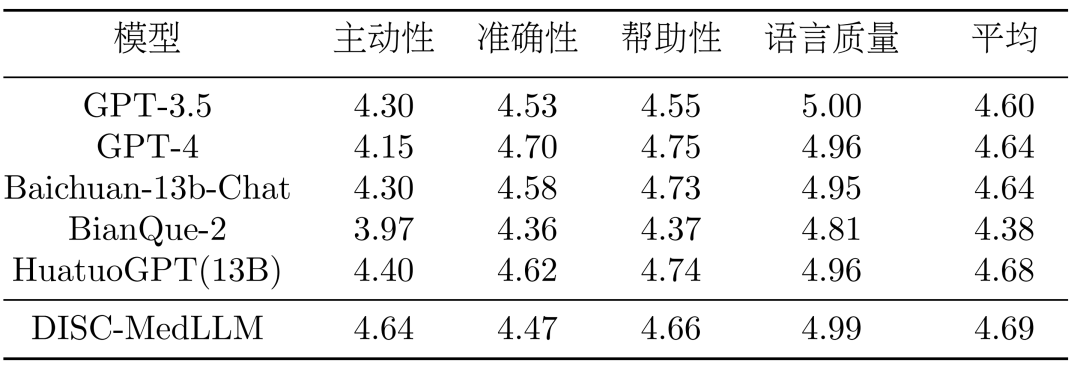
在 CMD 样本中,如图 8 所示,GPT-4 获得了最高分,其次是 GPT-3.5。医学领域的模型 DISC-MedLLM 和 HuatuoGPT 的整体表现分数相同,在不同科室中表现各有出色之处。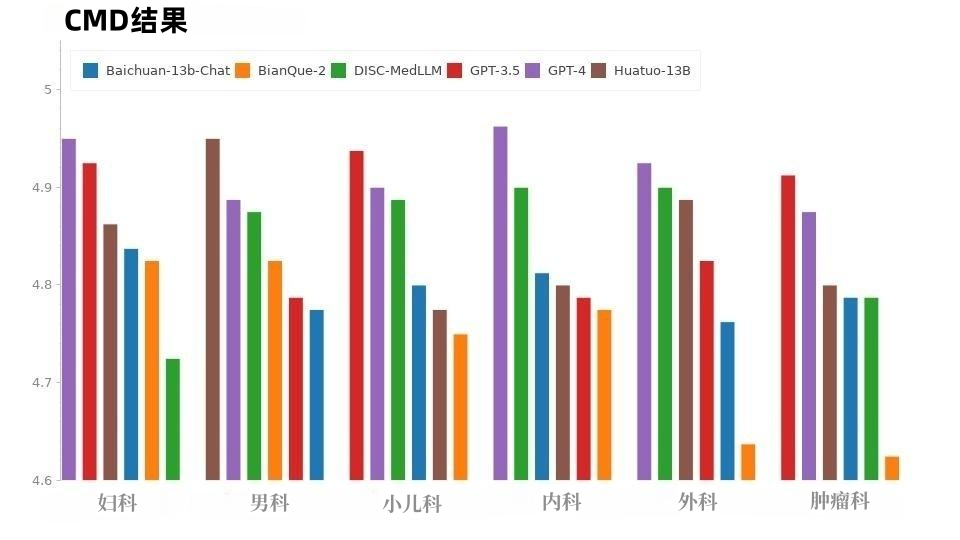
CMID 的情况与 CMD 类似,如图 9 所示,GPT-4 和 GPT-3.5 保持领先。除 GPT 系列外,DISC-MedLLM 表现最佳。在病症、治疗方案和药物等三个意图中,它的表现优于 HuatuoGPT。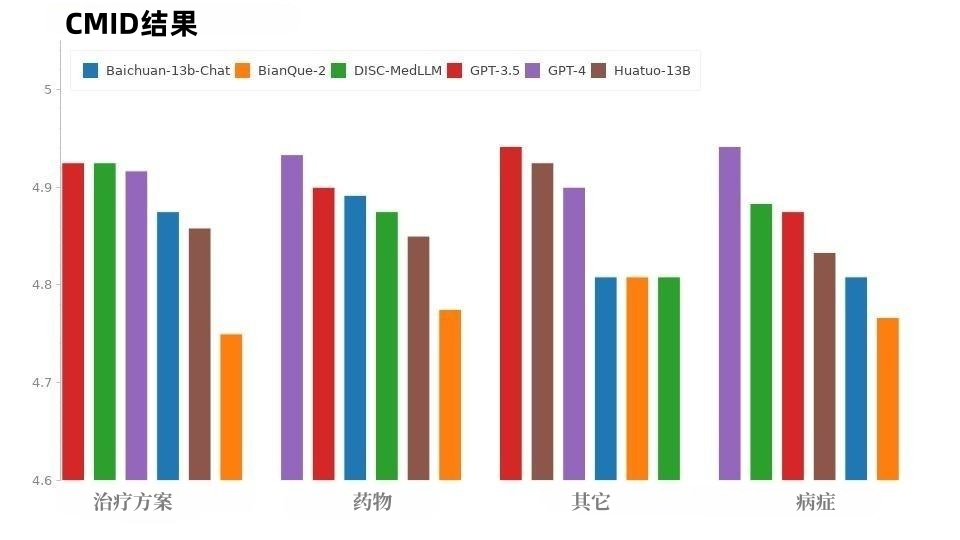
各模型在 CMB-Clin 和 CMD/CMID 之间表现不一致的情况可能是由于这三个数据集之间的数据分布不同造成的。CMD 和 CMID 包含更多明确的问题样本,患者在描述症状时可能已经获得了诊断并表达明确的需求,甚至患者的疑问和需求可能与个人健康状况无关。在多个方面表现出色的通用型模型 GPT-3.5 和 GPT-4 更擅长处理这种情况。DISC-Med-SFT 数据集利用现实世界对话和通用领域 LLM 的优势和能力,对三个方面进行了针对性强化:领域知识、医学对话技能和与人类偏好;高质量的数据集训练了出色的医疗大模型 DISC-MedLLM,在医学交互方面取得了显著的改进,表现出很高的可用性,显示出巨大的应用潜力。该领域的研究将为降低在线医疗成本、推广医疗资源以及实现平衡带来更多前景和可能性。DISC-MedLLM 将为更多人带来便捷而个性化的医疗服务,为大健康事业发挥力量。




































