
9 月 12 日,淘天集团联合爱橙科技正式对外开源大模型训练框架 ——megatron-llama,旨在让技术开发者们能够更方便的提升大语言模型训练性能,降低训练成本,并且保持和 llama 社区的兼容性。测试显示,在 32 卡训练上,相比 huggingface 上直接获得的代码版本,megatron-llama 能够取得 176% 的加速;在大规模的训练上,megatron-llama 相比较 32 卡拥有几乎线性的扩展性,而且对网络不稳定表现出高容忍度。目前 megatron-llama 已在开源社区上线。
开源地址:https://github.com/alibaba/megatron-llama
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图示:DeepSpeed ZeRO Stage-2
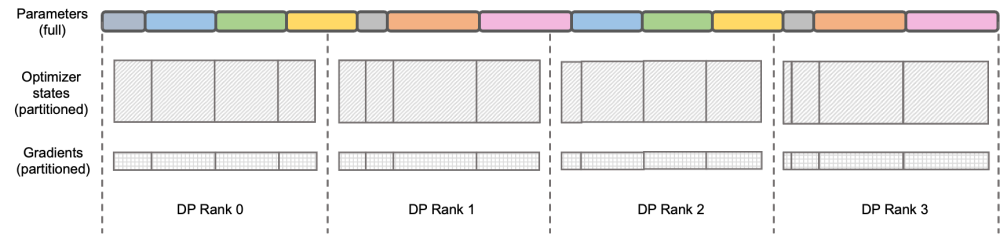
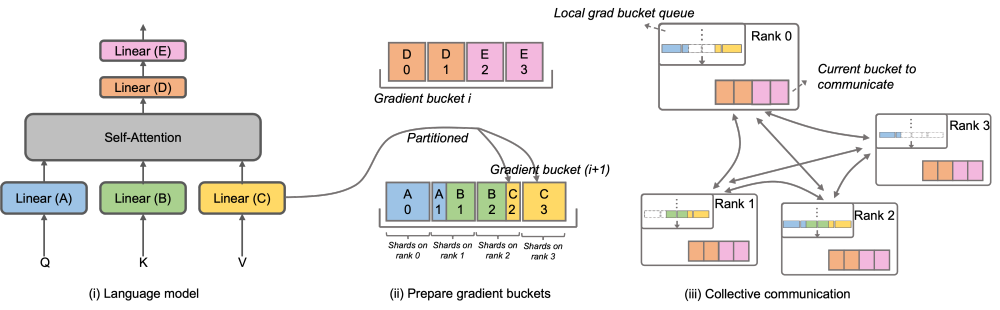
图示:DeepSpeed ZeRO Stage-2 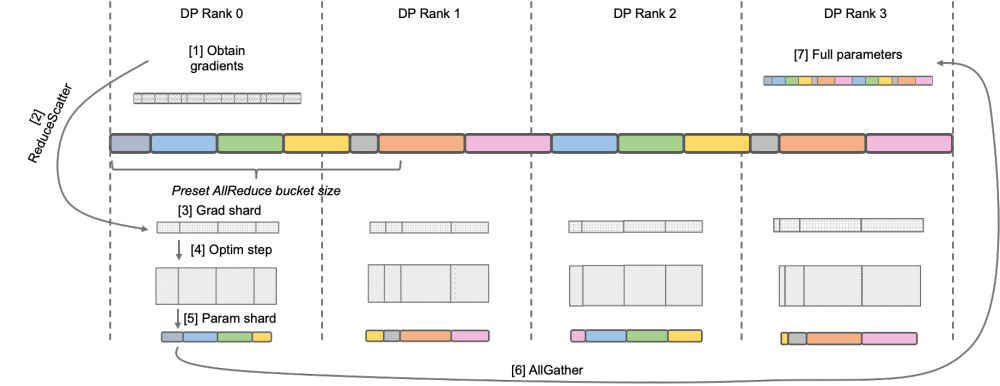 原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。
原生 Megatron-LM 通过 DistributedOptimizer 实现了类似 ZeRO-2 的梯度和优化器状态切分,以减少训练中的显存占用。如上图所示,DistributedOptimizer 在每次获得预设的梯度聚合过的所有梯度后,通过 ReduceScatter 算子,将之前累积的全部梯度分发到不同的 Rank。每个 Rank 只获得自己需要处理的部分梯度,而后进行优化器状态的更新和对应参数的更新。最后各个 Rank 通过 AllGather 的方式从其他节点上获取更新过的参数,最终取得全部的参数。实际训练的结果显示,Megatron-LM 的梯度和参数通信与其他计算串行进行,对于大规模预训练任务,为了保证总批数据大小不变,通常无法开启较大的 GA。于是通信占比会伴随机器增加上升,这时候串行通信的特点导致扩展性很弱。在社区内,这方面的需求也很迫切。 
以上就是淘天集团与爱橙科技合作发布开源大型模型训练框架Megatron-LLaMA的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 188
188




















