
it之家 10 月 26 日消息,jina ai 在其官网发布新闻稿,宣布推出 jina-embeddings-v2 模型,号称是目前是唯一支持 8k(8192 个 token)上下文长度的开源产品,在功能和性能上与 openai 的 text-embedding-ada-002 类似。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在MTEB排行榜方面,IT之家发现官方做出了以下解释:
与 OpenAI 的 8K 模型 text-embedding-ada-002 进行比较,jina-embedding-v2 在分类平均值、重排平均值、检索平均值和摘要平均值方面均优于 OpenAI 的 text-embedding-ada-002▲ 图源 Jina AI 官网
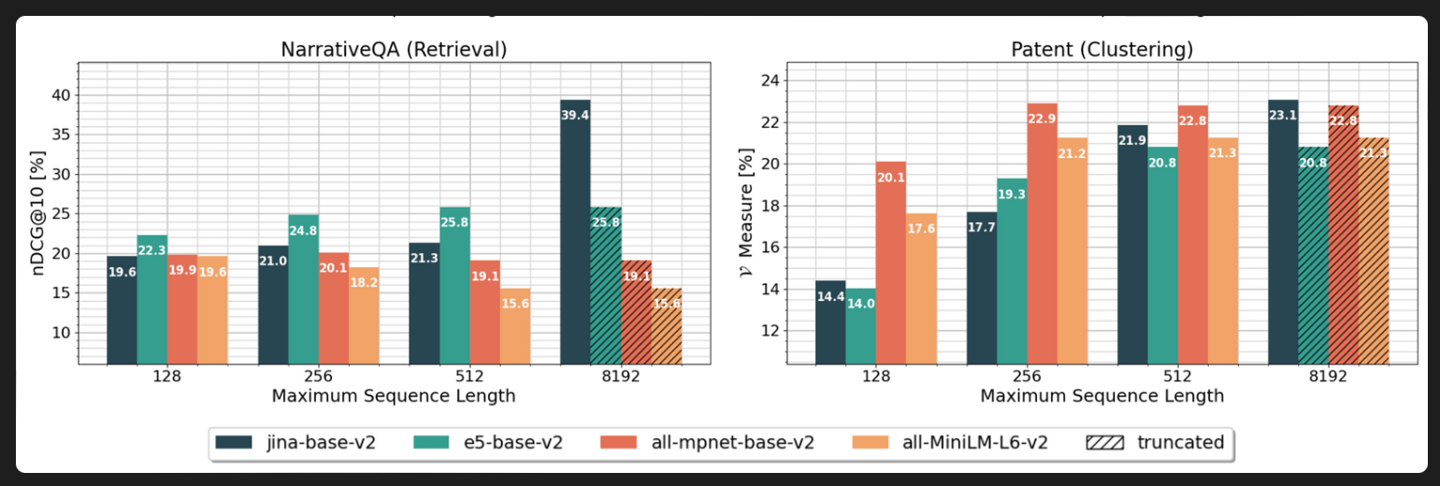
▲ 图源 Jina AI 官网
官方表示,jina-embeddings-v2 模型,是从头开始构建的。在过去的三个月里,Jina AI 团队进行了密集研发、数据收集和调整。
Jina AI 同时声称, jina-embeddings-v2 8K 的上下文长度有利于以下应用场景:
- 法律文件分析:确保对大量法律文本中的每一个细节进行捕捉和分析。
- 医学研究:为了进行高级分析和发现,全面地嵌入科学论文。
- 文学分析:深入研究长篇内容,捕捉微妙的主题元素。
- 财务预测:通过详细的财务报告获得卓越的洞察力。
- 会话式 AI:提升聊天机器人对复杂用户查询的响应能力。
以上就是Jina AI 推出全球首个开源 8K 文本嵌入模型,号称超越 OpenAI的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 723
723
















