
大模型涌向移动端的浪潮愈演愈烈,终于有人把多模态大模型也搬到了移动端上。近日,美团、浙大等推出了能够在移动端部署的多模态大模型,包含了 LLM 基座训练、SFT、VLM 全流程。也许不久的将来,每个人都能方便、快捷、低成本的拥有属于自己的大模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

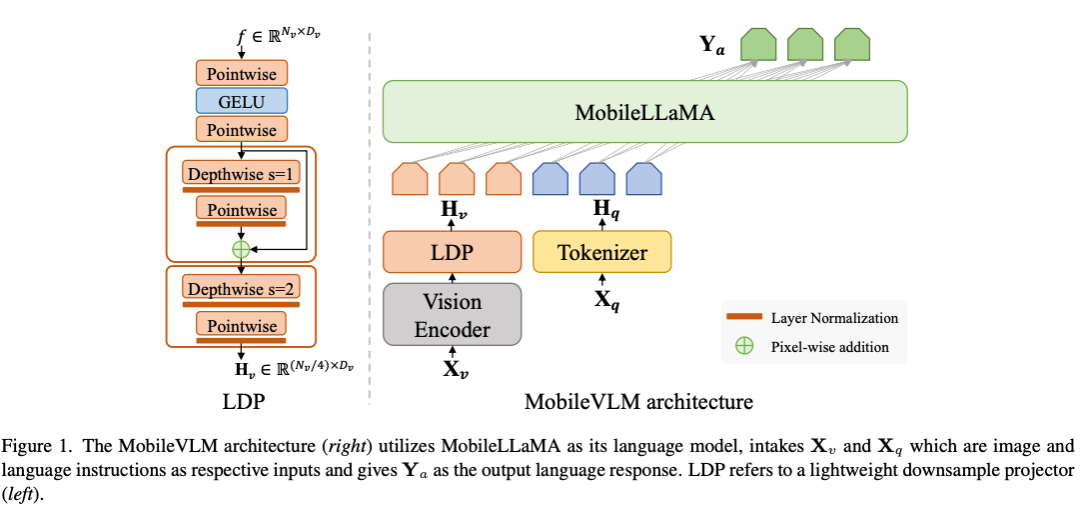
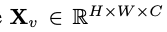 为输入,视觉编码器 F_enc 从中提取视觉嵌入
为输入,视觉编码器 F_enc 从中提取视觉嵌入 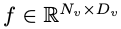 用于图像感知,其中 N_v = HW/P^2 表示图像块数,D_v 表示视觉嵌入的隐层大小。为了缓解因处理图像 tokens 效率问题,研究者设计了一种轻量级映射网络 P,用于视觉特征压缩和视觉 - 文本模态的对齐。它将 f 转换到词嵌入空间中,并为后续的语言模型提供合适的输入维度,如下所示:
用于图像感知,其中 N_v = HW/P^2 表示图像块数,D_v 表示视觉嵌入的隐层大小。为了缓解因处理图像 tokens 效率问题,研究者设计了一种轻量级映射网络 P,用于视觉特征压缩和视觉 - 文本模态的对齐。它将 f 转换到词嵌入空间中,并为后续的语言模型提供合适的输入维度,如下所示: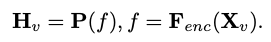
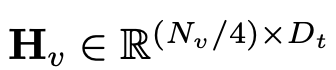 和文本的 tokens
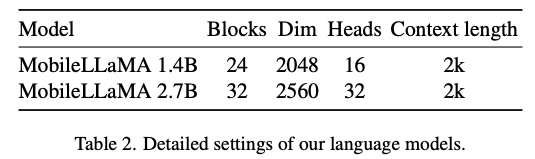
和文本的 tokens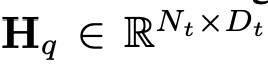 ,其中 N_t 表示文本 tokens 的数量,D_t 表示单词嵌入空间的大小。在目前的 MLLM 设计范式中,LLM 的计算量和内存消耗量最大,有鉴于此,本文为移动应用量身定制了一系列推理友好型 LLM,在速度上具有相当的优势,能够以自回归方式对多模态输入进行预测
,其中 N_t 表示文本 tokens 的数量,D_t 表示单词嵌入空间的大小。在目前的 MLLM 设计范式中,LLM 的计算量和内存消耗量最大,有鉴于此,本文为移动应用量身定制了一系列推理友好型 LLM,在速度上具有相当的优势,能够以自回归方式对多模态输入进行预测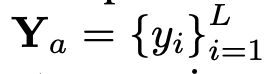 ,其中 L 表示输出的 tokens 长度。这一过程可表述为
,其中 L 表示输出的 tokens 长度。这一过程可表述为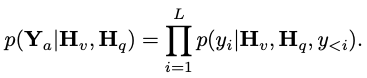 。
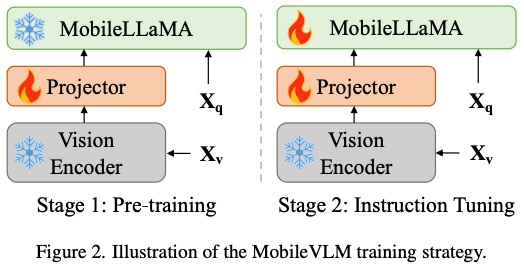
。
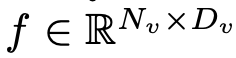 作为输入,并输出有效提取和对齐的视觉标记
作为输入,并输出有效提取和对齐的视觉标记 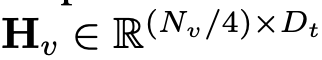 。
。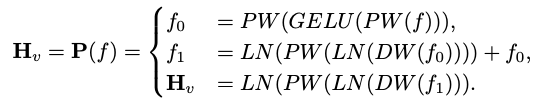
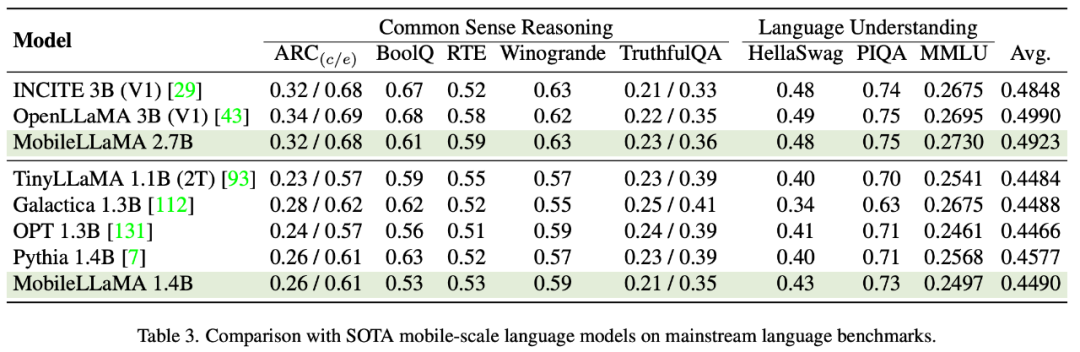
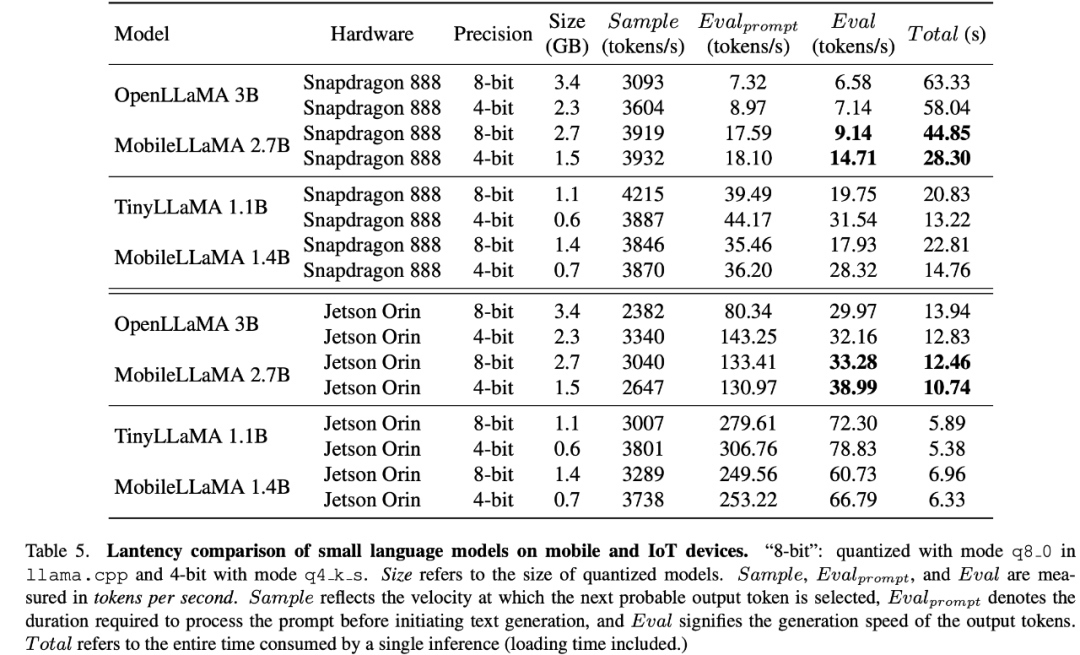
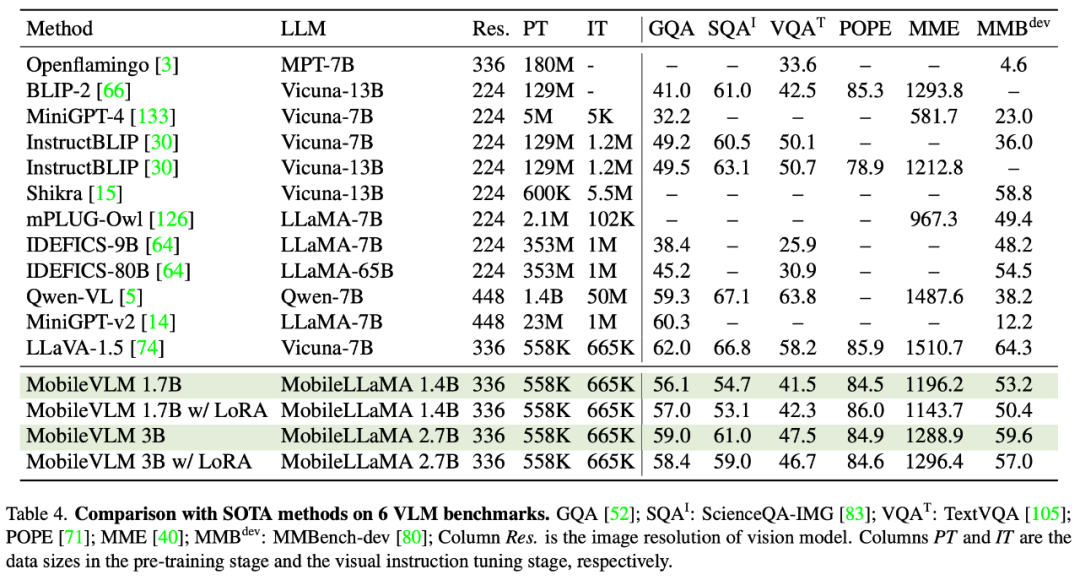
以上就是美团、浙大等合作,打造全流程移动端多模态大模型MobileVLM,能够实时运行,并且采用骁龙888处理器的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 179
179




















