







让theta=模型参数和max_iters=时期数。对于itr=1,2,3,...,max_iters:对于mini_batch(x_mini,y_mini):
批量X_mini的前向传递:
1、对小批量进行预测
2、使用参数的当前值计算预测误差(J(theta))
后传:计算梯度(theta)=J(theta)wrt theta的偏导数
立即学习“Python免费学习笔记(深入)”;
更新参数:theta=theta–learning_rate*gradient(theta)
Python实现梯度下降算法的代码流程
第一步:导入依赖项,为线性回归生成数据,并可视化生成的数据。以8000个数据示例,每个示例都有2个属性特征。这些数据样本进一步分为训练集(X_train,y_train)和测试集(X_test,y_test),分别有7200和800个样本。
import numpy as np import matplotlib.pyplot as plt mean=np.array([5.0,6.0]) cov=np.array([[1.0,0.95],[0.95,1.2]]) data=np.random.multivariate_normal(mean,cov,8000) plt.scatter(data[:500,0],data[:500,1],marker='.') plt.show() data=np.hstack((np.ones((data.shape[0],1)),data)) split_factor=0.90 split=int(split_factor*data.shape[0]) X_train=data[:split,:-1] y_train=data[:split,-1].reshape((-1,1)) X_test=data[split:,:-1] y_test=data[split:,-1].reshape((-1,1)) print(& quot Number of examples in training set= % d & quot % (X_train.shape[0])) print(& quot Number of examples in testing set= % d & quot % (X_test.shape[0]))
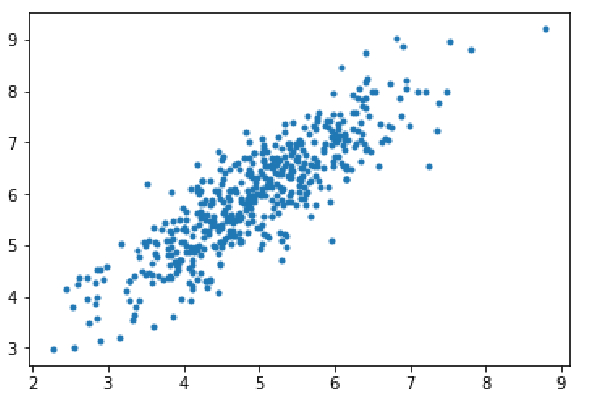
训练集中的示例数=7200测试集中的示例数=800
第二步:
使用小批量梯度下降实现线性回归的代码。gradientDescent()是主要的驱动函数,其他函数是辅助函数:
进行预测——hypothesis()

计算梯度——gradient()
计算误差——cost()
创建小批量——create_mini_batches()
驱动程序函数初始化参数,计算模型的最佳参数集,并返回这些参数以及一个列表,其中包含参数更新时的错误历史记录。
def hypothesis(X,theta):
return np.dot(X,theta)
def gradient(X,y,theta):
h=hypothesis(X,theta)
grad=np.dot(X.transpose(),(h-y))
return grad
def cost(X,y,theta):
h=hypothesis(X,theta)
J=np.dot((h-y).transpose(),(h-y))
J/=2
return J[0]
def create_mini_batches(X,y,batch_size):
mini_batches=[]
data=np.hstack((X,y))
np.random.shuffle(data)
n_minibatches=data.shape[0]//batch_size
i=0
for i in range(n_minibatches+1):
mini_batch=data[i*batch_size:(i+1)*batch_size,:]
X_mini=mini_batch[:,:-1]
Y_mini=mini_batch[:,-1].reshape((-1,1))
mini_batches.append((X_mini,Y_mini))
if data.shape[0]%batch_size!=0:
mini_batch=data[i*batch_size:data.shape[0]]
X_mini=mini_batch[:,:-1]
Y_mini=mini_batch[:,-1].reshape((-1,1))
mini_batches.append((X_mini,Y_mini))
return mini_batches
def gradientDescent(X,y,learning_rate=0.001,batch_size=32):
theta=np.zeros((X.shape[1],1))
error_list=[]
max_iters=3
for itr in range(max_iters):
mini_batches=create_mini_batches(X,y,batch_size)
for mini_batch in mini_batches:
X_mini,y_mini=mini_batch
theta=theta-learning_rate*gradient(X_mini,y_mini,theta)
error_list.append(cost(X_mini,y_mini,theta))
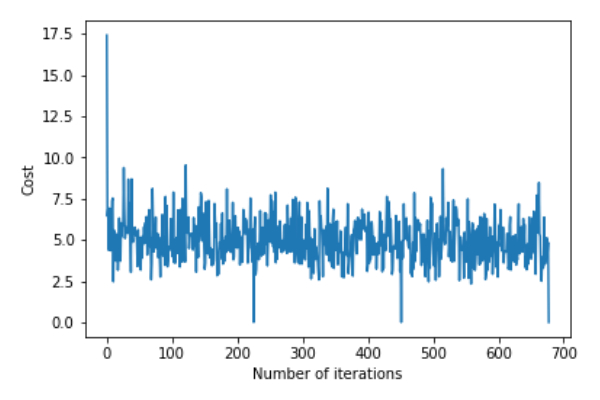
return theta,error_list调用gradientDescent()函数来计算模型参数(theta)并可视化误差函数的变化。
theta,error_list=gradientDescent(X_train,y_train)
print("Bias=",theta[0])
print("Coefficients=",theta[1:])
plt.plot(error_list)
plt.xlabel("Number of iterations")
plt.ylabel("Cost")
plt.show()偏差=[0.81830471]系数=[[1.04586595]]
第三步:对测试集进行预测并计算预测中的平均绝对误差。
y_pred=hypothesis(X_test,theta) plt.scatter(X_test[:,1],y_test[:,],marker='.') plt.plot(X_test[:,1],y_pred,color='orange') plt.show() error=np.sum(np.abs(y_test-y_pred)/y_test.shape[0]) print(& quot Mean absolute error=",error)
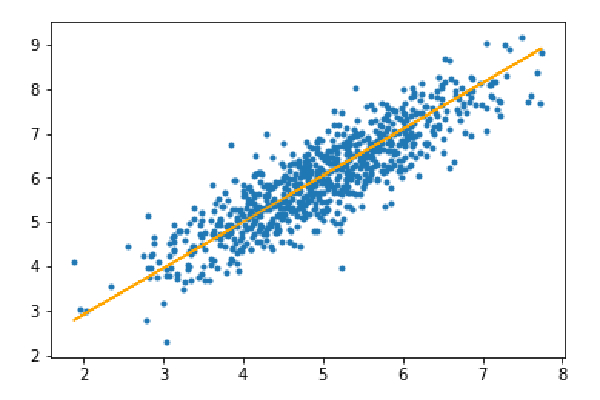
平均绝对误差=0.4366644295854125
橙色线代表最终假设函数:theta[0]+theta[1]*X_test[:,1]+theta[2]*X_test[:,2]=0





























