







k最近邻算法是一种用于分类和识别的基于实例或基于内存的机器学习算法。它的原理是通过找到给定查询点的最近邻数据来进行分类。由于该算法严重依赖已存储的训练数据,它可以被看作是一个非参数化的学习方法。
k最近邻算法适用于处理分类或回归问题。对于分类问题,它使用离散值进行处理,而对于回归问题,它使用连续值进行处理。在进行分类之前,必须定义距离,常见的距离度量方法有多种选择。
欧几里得距离
这是常用的距离度量,适用于实值向量。公式测量查询点与另一点之间的直线距离。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
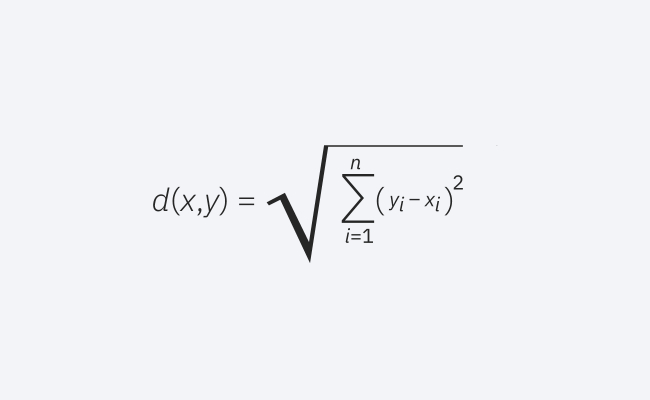
欧几里得距离公式
曼哈顿距离
这也是一种流行的距离度量,它测量两点之间的绝对值。

曼哈顿距离公式
闵可夫斯基距离
此距离度量是欧几里德和曼哈顿距离度量的广义形式。


闵可夫斯基距离公式
汉明距离
该技术通常与布尔或字符串向量一起使用,识别向量不匹配的点。因此,它也被称为重叠度量。

汉明距离公式
确定k最近邻算法距离的意义
为了确定哪些数据点最接近给定查询点,需要计算查询点与其他数据点之间的距离。这些距离度量有助于形成决策边界,将查询点划分为不同的区域。




























