







小语言模型的出现是为弥补大语言模型的训练、推理等成本昂贵的缺点,但其自身也存在训练到某个阶段后性能下降的事实 (饱和现象),那么这个现象的原因是什么?是否可以克服并利用它去提升小语言模型的性能?
语言建模领域的最新进展在于在极大规模的网络文本语料库上预训练高参数化的神经网络。在实践中,使用这样的模型进行训练和推断可能会产生本高昂,这促使人们使用较小的替代模型。然而,已经观察到较小的模型可能会出现饱和和现象,表现为在训练的某个高级阶段能力下降并趋于稳定。
最近的一篇论文发现,这种饱和和现象可以通过较小模型的隐藉维度与目标上下文概率分布的高秩之间的不匹配来解释。这种不匹配通过采用名为softmax瓶颈的模型中使用的线性预测头的性能来影响了这些模型中使用的线性预测头的性能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/pdf/2404.07647.pdf
本文在不同设置下相量了 softmax 瓶颈的影响,并发现基于小于 1000 个隐藏维度的模型往往在预训练的后期采用退化的潜在表征,从而导致评估性能降低。
简介
表征退化问题是影响于文本数据的自监督学习方法等多种模式的常见现象。对语言模型的中间表征进行观察揭示了它们的低角度可变性(或各向异性),或者在训练过程中出现的异常维度。然而,这些观察大多是针对维度与 BERT 或 GPT-2 等系列模型相当的相对较小规模模型进行的。
这些模型通常由一个神经网络 f_θ 组成,该神经网络接受 token 序列:
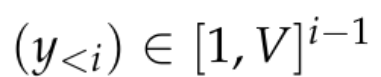
并在 R^d 中生成一个相对低维的上下文表征,其中 d 是模型的隐藏维度。然后它们依赖于一个语言建模头,该头部产生上下文 token 概率的对数。语言建模头的常见选择是一个线性层,其参数为 W ∈ R^(V×d),其中 V 是可能 token 的数量。因此得到的下一个 token 概率分布是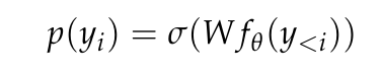 其中 σ 是 softmax 函数。
其中 σ 是 softmax 函数。
在语言建模领域,当前的趋势在于扩展引入了 GPT-2 的生成预训练方法,这意味着在巨大的网络文本语料库上训练由数十亿参数组成的神经模型。然而,训练和应用这些高参数化模型会引发能源和硬件相关的问题,这需要寻求通过较小的模型实现类似性能水平的方法。
然而,对 Pythia 模型套件的评估表明,将小型模型训练在非常大的语料库上可能会导致饱和,表现为在预训练后期性能下降。本文通过表征退化的视角探讨了这种饱和现象,并发现这两种现象之间存在着强烈的相关性,同时进一步证明了表征退化在小型模型的语言建模头中发生,并在理论和实证上展示了线性语言建模头如何成为基于小隐藏维度的架构的性能瓶颈。
语言模型饱和现象
本文首先验证了确实可以观察和量化 Pythia 检查点的性能饱和,因为它们是一系列模型尺寸的唯一发布的中间检查点。本文测量了从它们的预训练数据集(即 The Pile)中随机抽取的 5 万个 token 的 Pythia 检查点的交叉熵。
在图 1a 中可以清楚地看到,连 4.1 亿参数的模型都遇到了饱和现象,表现为在高级训练阶段域内损失的增加。
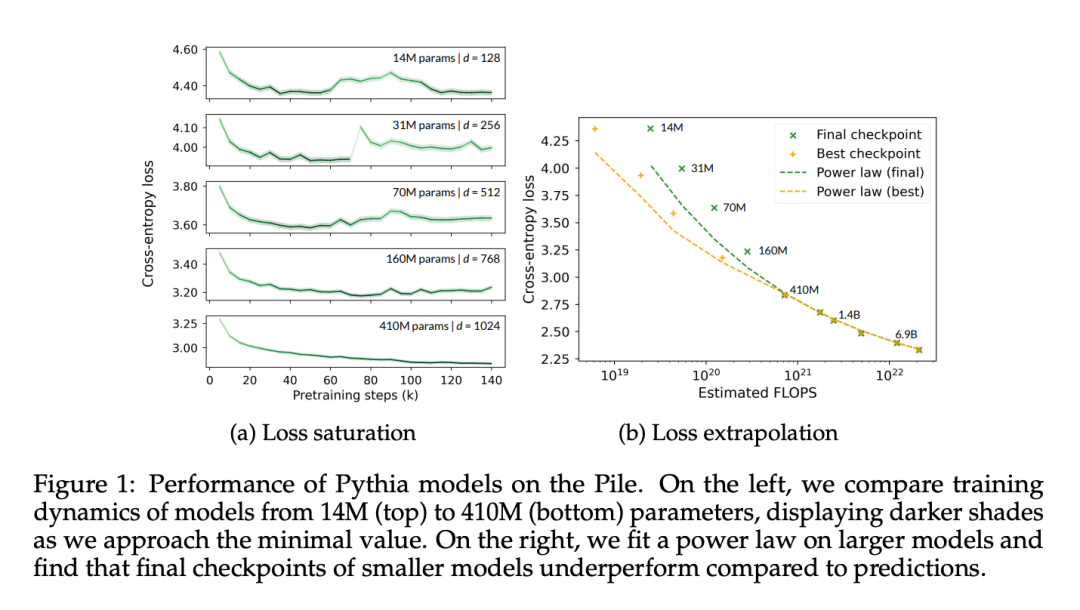
在图 1b 中,本文根据 Hoffmann et al. (2022) 的方法,对从 4.1 亿参数开始的模型的数据点进行了拟合,只优化模型相关的常数(A 和 α),同时重用所有其他值(B = 410.7,β = 0.28,E = 1.69)。这里回顾了 Hoffmann et al. (2022) 给出的参数计数 N 和 token 计数 T 之间的关系:

本文发现最佳参数为 A = 119.09 和 α = 0.246。作者展示了与最佳和最终检查点相对应的 token 计数的拟合曲线。可以观察到,最终检查点的性能平均低于外推值约 8%。损失最小(最佳)检查点由于学习率冷却不完全,预计会低于外推法,但其表现仅低于外推法约 4%。
在用于语言模型评估工具(LM Evaluation Harness)评估的数据集中,也观察到了类似的性能饱和现象,如表 1 所示。

性能饱和是秩饱和(Rank Saturation)
规模各向异性
各向异性是是在各种小型语言模型中观察到的一种常见的表征退化形式,它包括特定层中表征分布的角度可变性降低。之前的研究(Ethayarajh, 2019; Godey et al., 2024)注意到,小型变形语言模型的几乎所有层都是各向异性的。衡量向量表征集合 H 中各向异性的常用方法是平均余弦相似度:
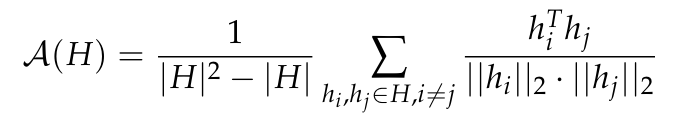
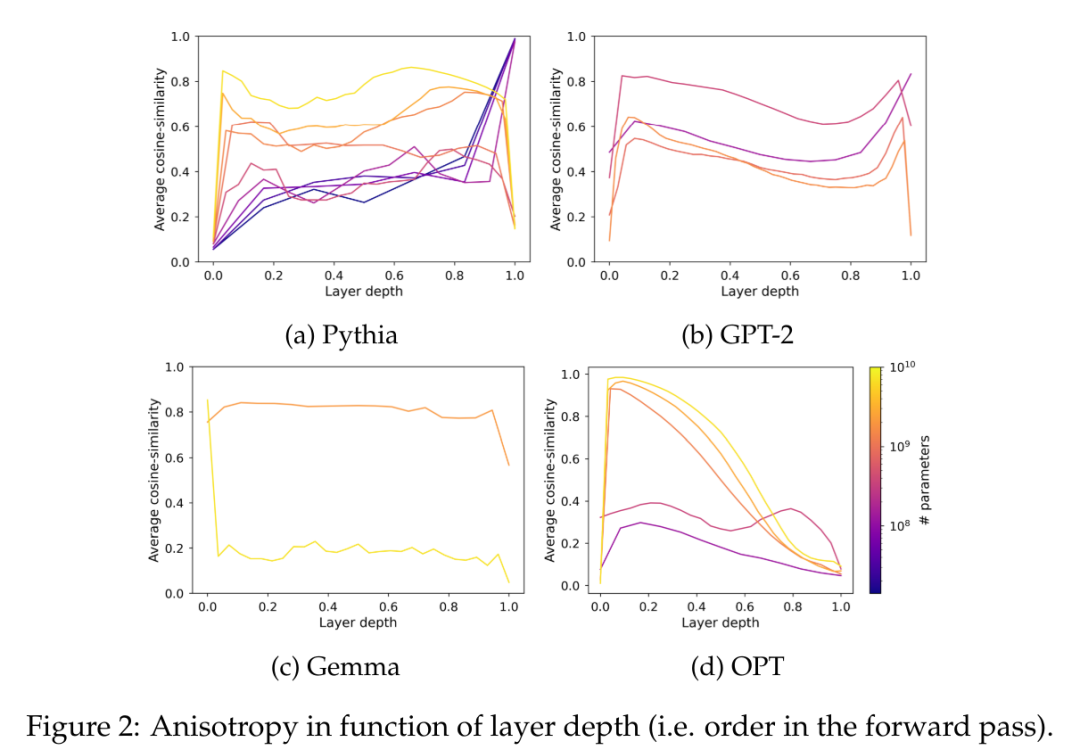
然而,目前尚不清楚各向异性是否会影响具有超过 10 亿参数的模型。为了解决这个问题,本文计算了一系列模型中间表征在层间的平均余弦相似度;即 GPT-2,OPT,Pythia 和 Gemma。本文使用了 The Pile 的子样本,因为假设该数据集的领域包括或匹配这些套件中使用的预训练数据集的领域。
在图 2 中,可以观察到,大多数 Transformer 模型的大多数层在某种程度上都是各向异性的,而不论其规模如何。然而,在最后一层中似乎存在一个二分现象,其中模型要么几乎是各向同性的,要么是高度各向异性的。本文注意到这种二分现象与 Pythia 套件的饱和现象之一相一致,其中只有包含 1.6 亿个或更少参数的模型受到最后一层各向异性的影响。

本文研究了 Pythia 套件中各向异性的训练动态,并将其与图 3 中的饱和现象进行比较。
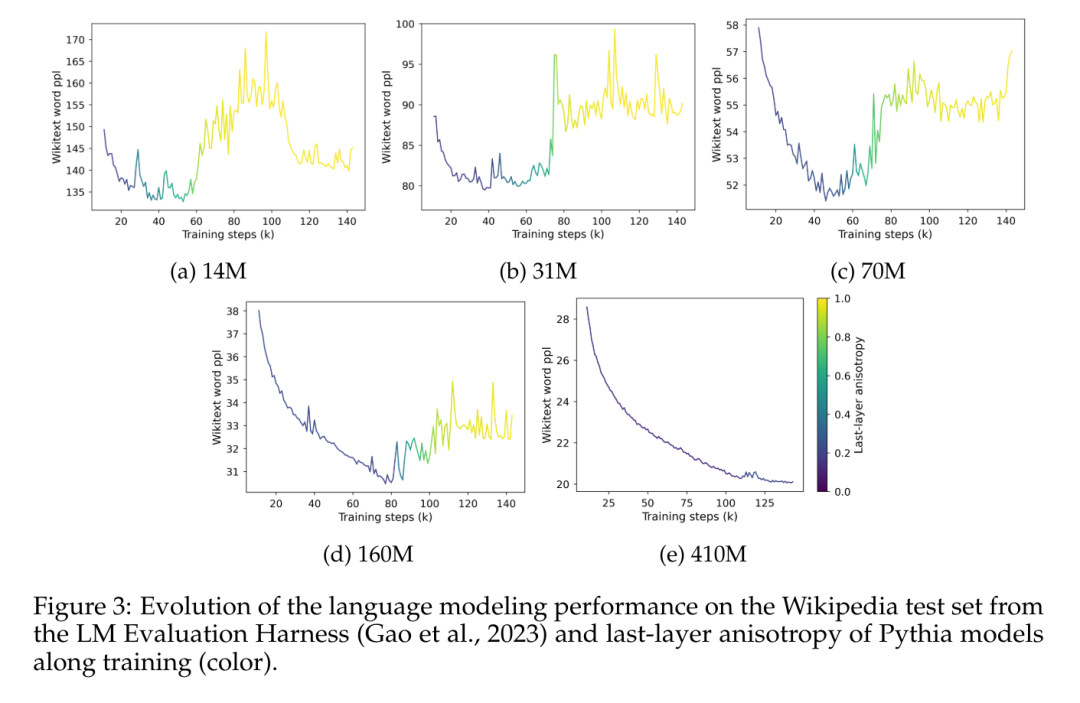
图 3 清晰地展示了性能饱和现象的出现与模型最后一层表征中各向异性出现之间的明显相关性。它还显示了在训练过程中,各向异性在饱和点附近会突然增加。在这里观察到,在特定的领域内语料库中,模型在饱和时迅速失去性能,并且似乎永远无法完全从这种爆炸中恢复过来。
奇异值饱和
平均余弦相似度是衡量分布均匀性的有价值的指标,但包含其他指标可以帮助更好地捕捉某些流形的复杂性。此外,它只关注语言模型的输出嵌入,而不关注它们的权重。本节通过研究语言建模头的奇异值分布来扩展本文的分析,以将实证观察与本文的理论发现联系起来。
图 4 展示了沿训练过程中最终预测层权重 W 的奇异值分布:
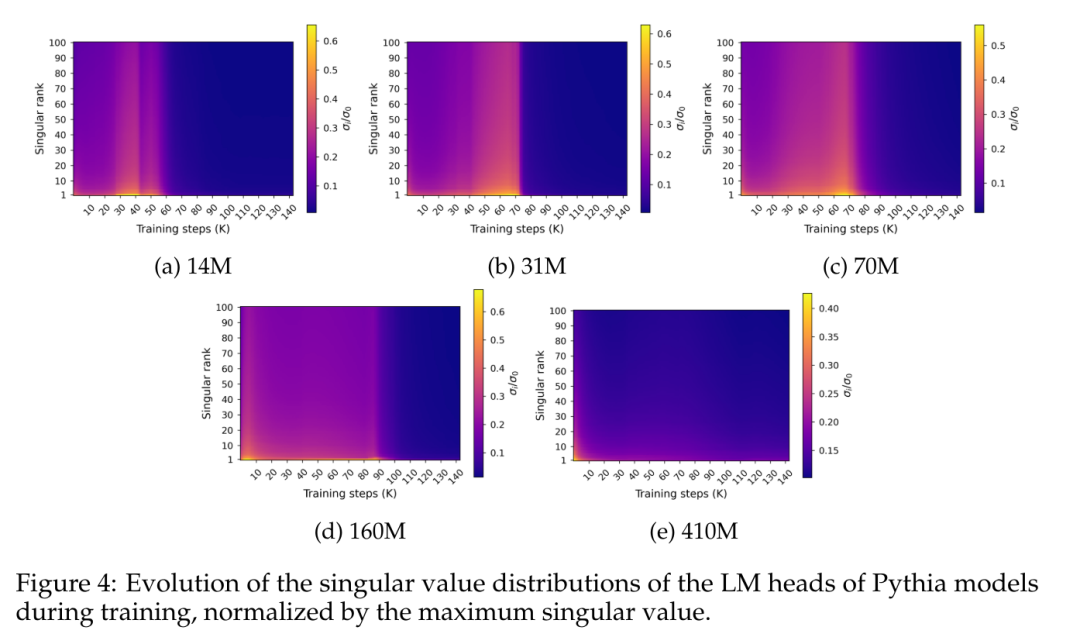
图 4 揭示了一种特定的频谱饱和模式,它与性能饱和现象大致同时发生。图中显示,奇异值分布在训练过程中逐渐变平,几乎达到均匀性,然后突然演变为尖峰分布,最大奇异值相对其他分布较高。
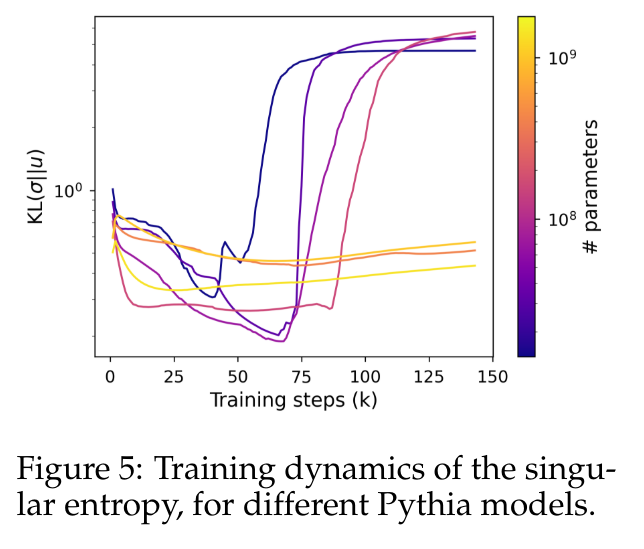
为了更准确地量化这种行为,本文使用奇异熵度量,计算为归一化奇异值分布与均匀分布之间的 Kullback-Leibler 散度。
图 5 显示了使用少于 4.1 亿个参数的模型与使用较大参数的模型的奇异分布演变方式不同。小型模型的头部看到它们的奇异值分布逐渐变得更加均匀,直到它们突然退化为止,这再次与语言模型性能下降相关。较大模型的奇异值分布趋于更稳定,并且在整个训练过程中没有显示出明显的单调模式。
Softmax 瓶颈与语言维度
自然语言的固有维度
直观地说,上文中观察到的奇异值分布饱和现象只适用于较小的模型,这就对 LM 头的优化所涉及的维度提出了质疑。本节建议根据经验测量 LM 头的秩的临界值,并估计该头的输出应该匹配的上下文概率分布的维度。
为了经验性地测量线性头部秩的影响,本文提出在预训练的上下文表征上训练秩受限的头部,这些上下文表征来自高参数化语言模型。为了控制最大秩 r,考虑形式为 W = AB ∈ R^(V×d) 的头部,其中 A ∈ R^(V×r) 和 B ∈ R^(r×d) 的系数从 N(0,1)中抽取(d 是模型的隐藏维度)。这种 W 矩阵的秩受参数 r ∈ [1, d] 的限制对一系列值进行了扫描。
通过冻结语言模型,并在大约 1.5 亿 token 上训练秩受限的头部,同时调整学习速率以适应可训练参数的数量。
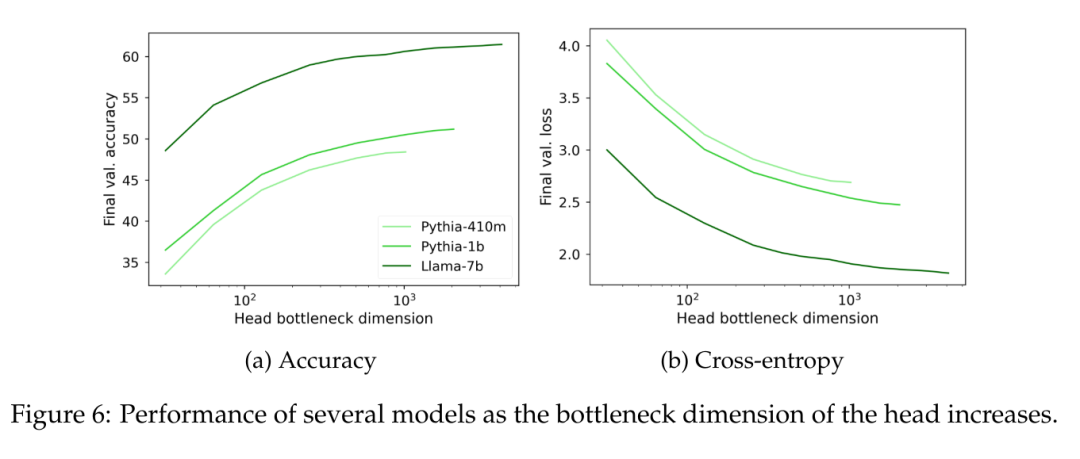
在图 6 中可以观察到,无论模型大小如何,当语言建模头 W 的秩低于 1000 时,困惑度开始明显下降。这暗示了对于具有更大隐藏维度的模型来说,头部不是主要的性能瓶颈,但对于具有较小隐藏维度的模型来说,它可能会独立于输出表征的质量而损害性能。
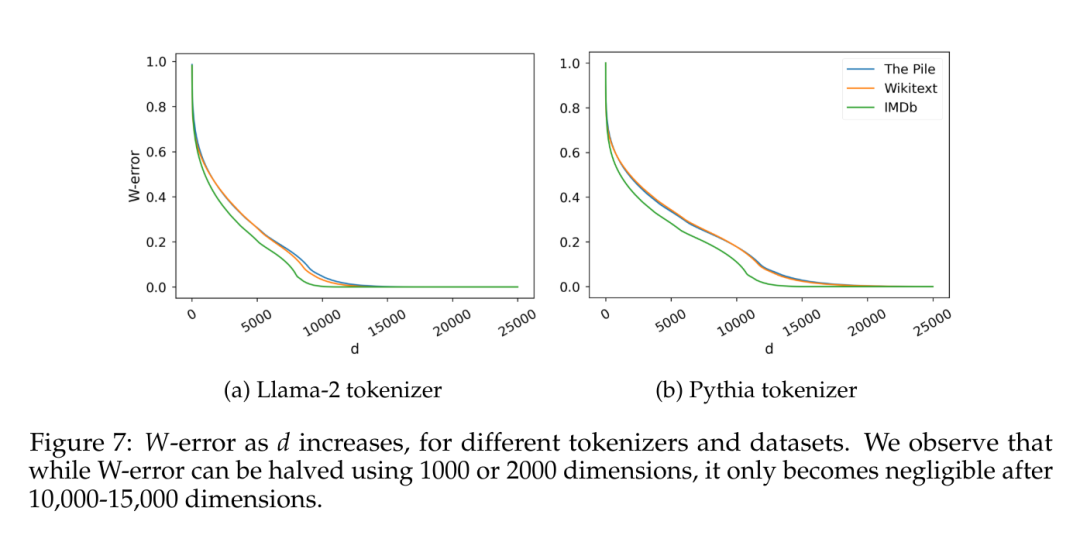
另一个有趣的因素是估计数据本身固有的维度。为了避免与特定归纳偏差相关的可能影响,本文在覆盖范围各异的几个数据集上训练了朴素的 5-gram 语言模型(IMDb,Wikitext,以及 The Pile),使用了两种不同词汇量的分词器(Llama-2 为 30k tokens,Pythia 为 50k tokens)。给定 C 个观察到的 5-gram,本文考虑矩阵 W ∈ R^(C×V),其中每行是给定 4 个 token 上可能 token 的概率分布,并计算它们的奇异值分布,如 Terashima et al. (2003) 所述。
图 7 报告了 W-error,根据 Eckart-Young-Mirsky 定理预测的秩为 d 的矩阵 W 的最小近似误差(见引理 5.2),并将其归一化为 W 的 Frobenius 范数。
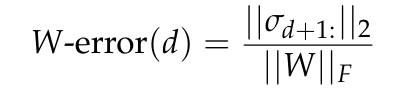
理论瓶颈
同时,W 的估计秩与隐藏维度的常规数量级相比也不可忽视。这里将从理论角度分析理想线性语言建模头的维度与性能之间的联系。
本节旨在确定上下文分布固有维度与可归因于语言模型输出表征的较低维度而产生的性能瓶颈之间的正式联系。为此构想了一个在理想上下文表征上优化的语言建模头,探讨了其谱特性与在相同表征上训练低秩头时产生的性能差距之间的关系。
更多研究细节,可查看原论文。





























