

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文主要作者来自 lmms-lab 团队与新加坡南洋理工大学。共同一作中,张培源是南洋理工大学研究助理,张恺宸是南洋理工大学四年级本科生,李博为南洋理工大学三年级博士生,指导教师为 mmlab@ntu 刘子纬教授。lmms-lab 是一个由学生、研究人员和教师组成的团队,致力于多模态模型的研究,主要研究方向包括多模态模型的训练与全面评估,此前的工作包括多模态测评框架 lmms-eval 等。
为什么说理解长视频难如 “大海捞针”?
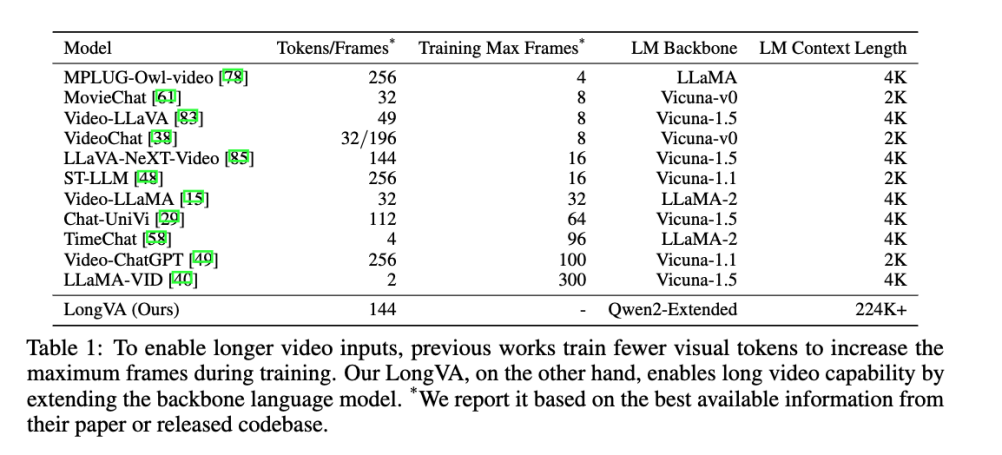
现有的 LMMs 在处理长视频时面临的一个主要挑战是视觉 token 数量过多。比如,LLaVA-1.6 对单张图片就能生成 576 到 2880 个视觉 token。视频帧数越多,token 数量也就更多。虽然 BLIP2,LLaMA-VID, Chat-UniVI 等工作 通过改动 ViT 和语言模型之间的连接层来减少视觉 token 数量,但仍然不能处理特别多的帧数。
此外,缺乏高质量的长视频数据集也是一大瓶颈。现有训练数据集大多是 1 分钟内的短视频,即使有长视频,标注的文本对仅限于视频的几个帧,缺乏密集的监督信号。
近日 LMMs-Lab, 南洋理工大学等机构的研究团队推出了 LongVA 长视频模型, 它可以理解超过千帧的视频数据,超越了当前一众开源视频多模态模型的性能!
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/abs/2406.16852
演示地址:https://longva-demo.lmms-lab.com/
代码地址:https://github.com/EvolvingLMMs-Lab/LongVA
作者团队首次在多模态领域提出长上下文迁移(Long Context Transfer),这一技术使得多模态大模型(LMMs)能够在不进行长视频训练的情况下,处理和理解超长视频。他们的新模型 LongVA 能够处理 2000 帧或者超过 20 万个视觉 token, 在视频理解榜单 Video-MME 上实现了 7B 规模的 SoTA。在最新的长视频 MLVU 榜单上, LongVA 更是仅次于 GPT4-o 的最强模型!
LongVA 的作者总结了下面这张图, 可以看到,目前的多模态大模型在长视频理解上还不尽如人意,能够处理的帧数限制了长视频的处理和理解。为了处理更多的帧,LLaMA-VID 等工作不得不急剧压缩单张帧对应的 token 数量。
长上下文迁移
针对处理长视频面临的挑战,研究团队提出了 “长上下文迁移” 这一全新思路。他们认为, 目前长视频大模型的多帧瓶颈不在如如何从 Vision Encoder 抽取压缩的特征上面(下图(a)), 而在于扩展模型的长上下文能力上。
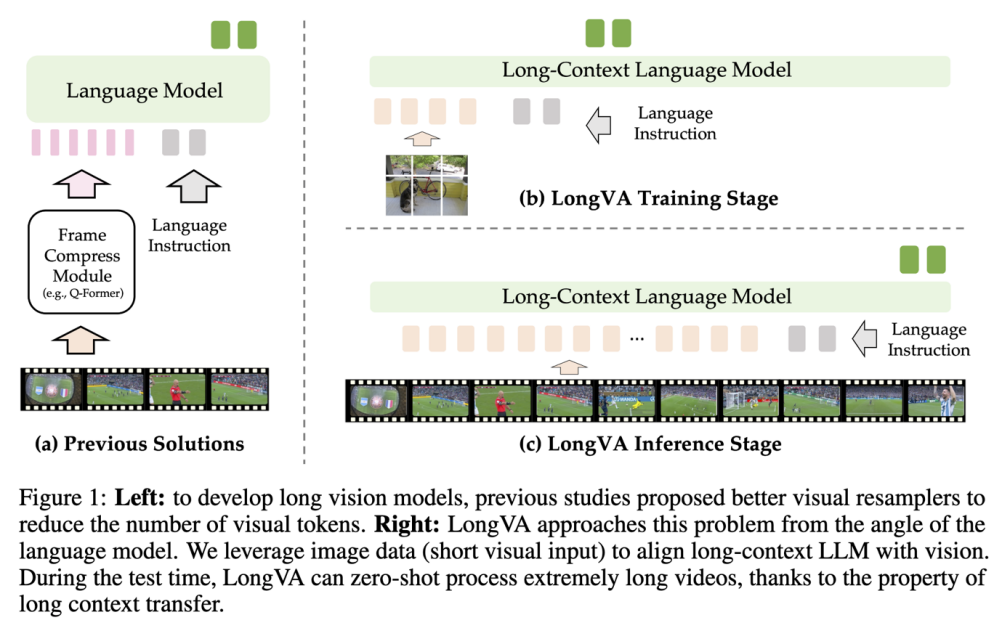
他们发现,通过简单地扩展语言模型的在文字上的上下文长度,他们能成功地将这种能力传递到视觉模态上,而无需进行任何长视频训练。具体做法是,首先通过长文本数据训练语言模型,然后利用短图像数据进行模态对齐。他们发现在这样训练的模型在测试时就可以直接理解多帧的视频, 省去了长视频训练的必要性。
在长语言模型训练过程中,作者团队使用了 Qwen2-7B-Instruct 作为底座,并通过长上下文训练将其文本上下文长度扩展到 224K。训练过程中使用了 FlashAttention-2、Ring Attention、activation checkpoint 和 parameter offload 等多种优化策略,以提高训练效率和内存利用率。
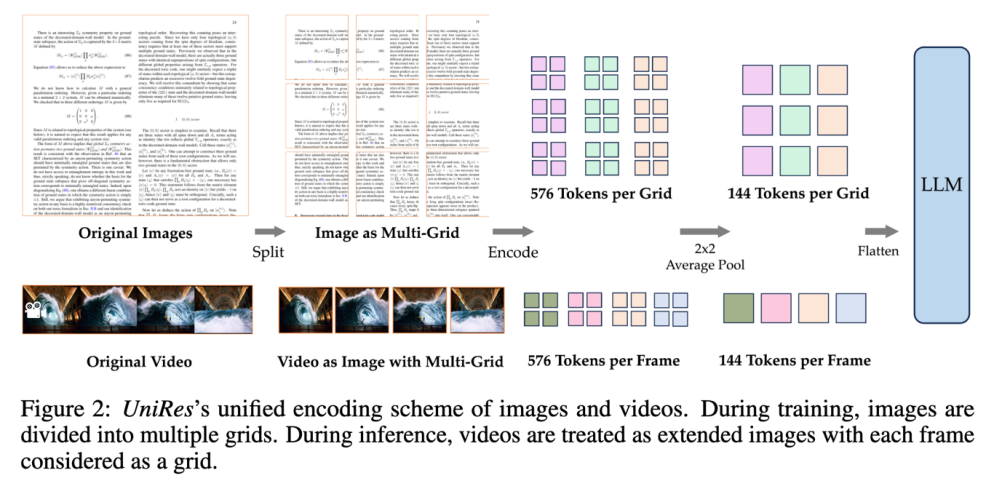
在模态对齐阶段,作者设计了一个名为 “UniRes” 的统一编码方案,用于同时处理图像和视频。UniRes 方案与 LLaVA-1.6 中的 AnyRes 编码方案类似,但去处了 base image 部分,针对每个 grid 分别一维化,并在每个网格内进行了 2x2 特征池化。这种方法确保了在将图像数据扩展到视频时,能够保持一致的表示形式。

Easily find JSON paths within JSON objects using our intuitive Json Path Finder
 193
193

LongVA 采用了 “短上下文训练,长上下文测试” 的策略,也就是让模型在模态对齐阶段仅使用图像 - 文本数据进行训练,而在测试直接利用长视频进行处理测试。这种策略有效地展示了长上下文迁移的现象,使得模型能够在未进行长视频训练的情况下,可以获得理解和处理长视频的能力。
LongVA 的超强性能
目前还没有评估 LMMs 长视频视觉上下文长度的基准测试。为了解决这一问题,LongVA 团队将大海捞针测试从文本扩展到视觉,并提出了 Visual Needle-In-A-Haystack (V-NIAH) 基准测试。
在 V-NIAH 测试中,团队设计了 5 个图像问答问题,将每个问题作为单帧插入到数小时的电影中,并以 1 帧 / 秒的频率采样视频作为视觉输入。这些 “针” 的图像来源于现有的视觉问答数据集或 AI 生成的图像,这样是为了确保模型无法仅通过语言知识来回答问题。每个问题都包含一个 “定位提示”,使得正确的系统或人类能够从视频中定位 “针” 帧并回答问题。
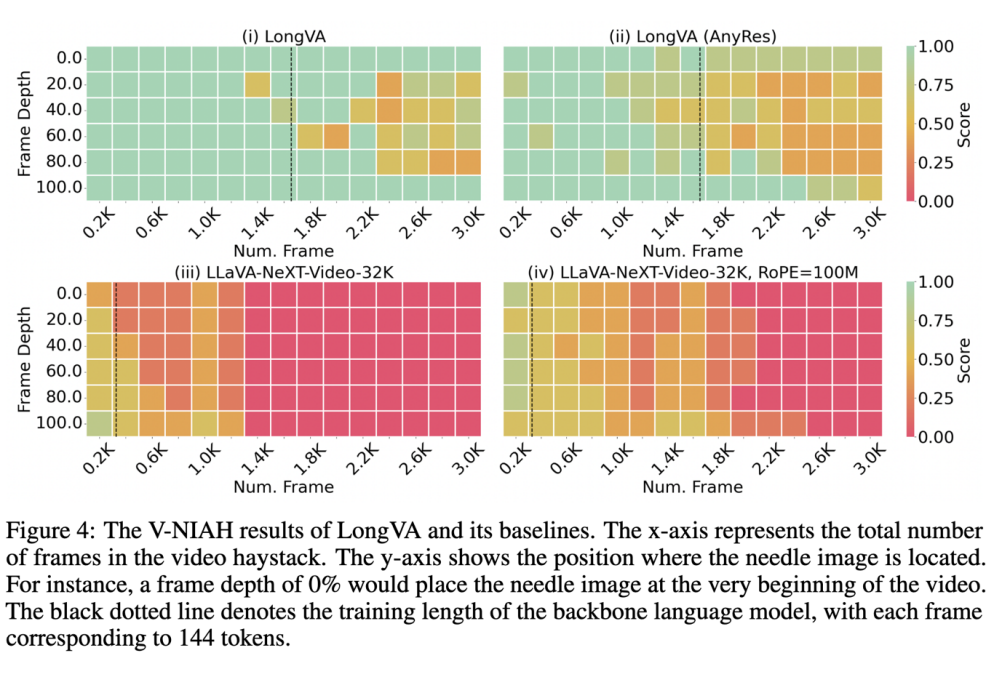
V-NIAH 测试结果显示,LongVA 在 2000 帧(每帧 144 个 token)以内的视觉大海捞针测试几乎全对, 在 3000 帧的尺度上也保持了不错的正确率 。有趣的是,和语言模型类似, 他们发现 LongVA 在 V-NIAH 上也存在一定程度的 Lost-In-The-Middle 现象。
在最近腾讯,中科大等机构提出的 Video-MME 榜单上, LongVA 排名第七并且达到了 7B 模型的 SoTA。
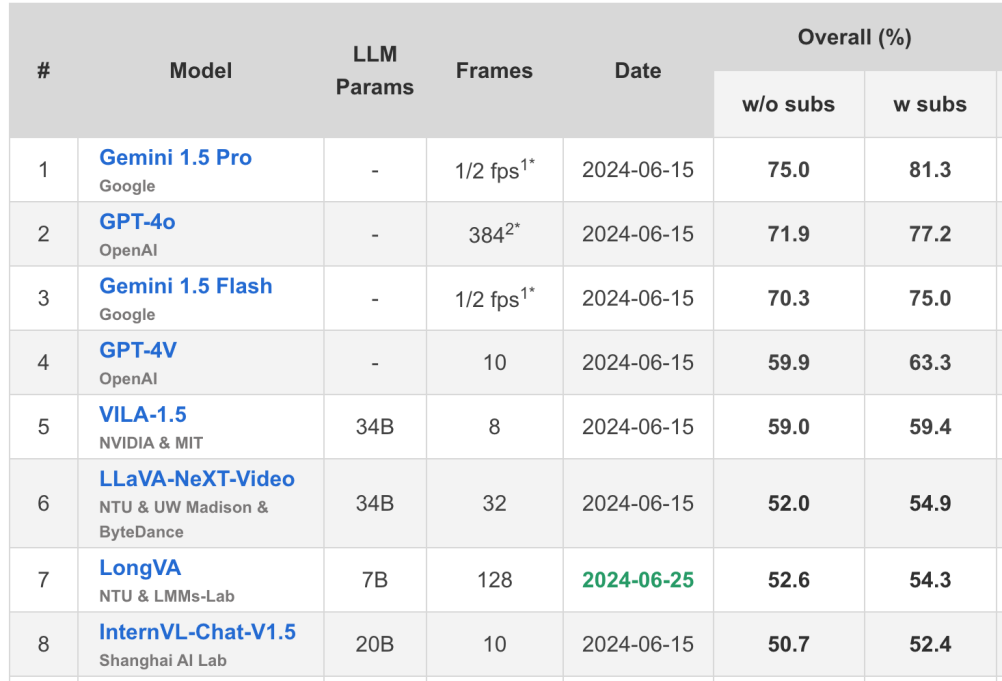
https://video-mme.github.io/home_page.html#leaderboard
在智源联合北邮、北大和浙大等多所高校推出的 MLVU 基准测试中, LongVA 更是仅次于 GPT-4o, 位列最强的开源模型。
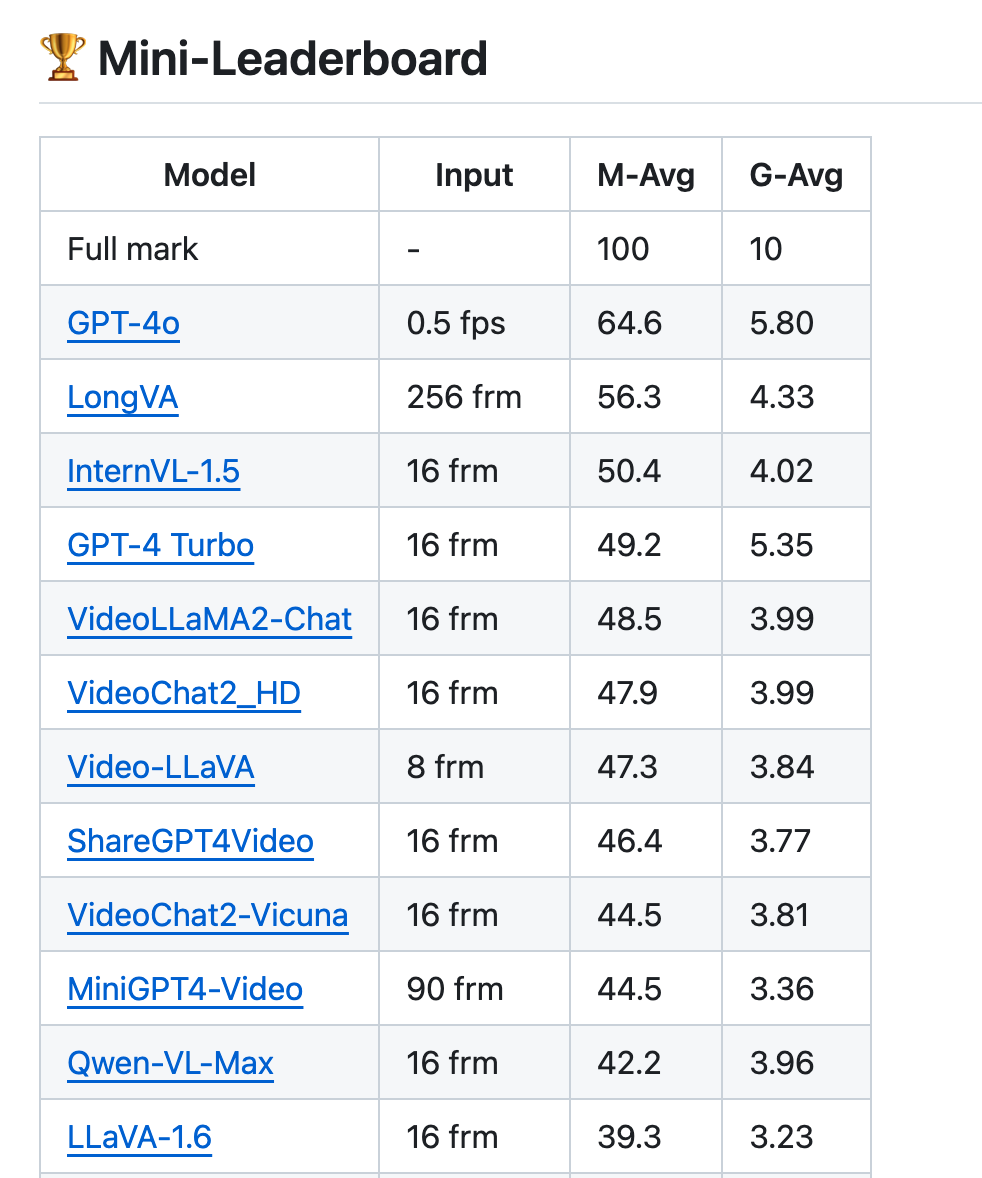
https://github.com/JUNJIE99/MLVU/
作者团队在论文中也附上了一些效果展示。
更多细节, 感兴趣的读者可以查看原论文。
以上就是7B最强长视频模型! LongVA视频理解超千帧,霸榜多个榜单的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 582
582




















