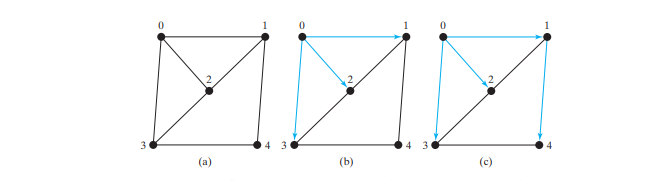
图的广度优先搜索会逐级访问顶点。第一层由起始顶点组成。每个下一个级别都由与前一个级别中的顶点相邻的顶点组成。图的广度优先遍历类似于树遍历中讨论的树的广度优先遍历。通过广度优先遍历树,逐级访问节点。首先访问根,然后访问根的所有子代,然后访问根的孙子,依此类推。类似地,图的广度优先搜索首先访问一个顶点,然后访问它的所有相邻顶点,然后访问与这些顶点相邻的所有顶点,依此类推。为了确保每个顶点仅被访问一次,如果已经访问过该顶点,则会跳过该顶点。
广度优先搜索算法
下面的代码描述了从图中的顶点 v 开始广度优先搜索的算法。
输入:g = (v, e) 和起始顶点 v
输出:一棵以 v 为根的 bfs 树
1 棵树 bfs(顶点 v){
2 创建一个空队列,用于存储要访问的顶点;
3 将v添加到队列中;
4 马克 v 访问过;
5
6 while (队列不为空) {
7 将一个顶点(例如 u)从队列中出队;
8 将u添加到遍历顶点列表中;
u 的每个邻居 w 为 9 个
10 如果 w 尚未被访问过 {
11 将w添加到队列中;
12 将 u 设置为树中 w 的父级;
13 马克访问过;
14}
15}
16}
bfs方法的时间复杂度为o(|e| + |v|),其中|e|表示边数,|v | 顶点数量。
广度优先搜索的实现bfs(int v) 方法在 graph 接口中定义,并在 abstractgraph.java 类中实现(第 197-222 行)。它返回以顶点 v 作为根的 tree 类的实例。该方法将搜索到的顶点存储在列表searchorder(第198行)中,将每个顶点的父节点存储在数组parent(第199行)中,使用链表作为队列(第203-204行),并使用isvisited 数组,指示顶点是否已被访问(第 207 行)。搜索从顶点v开始。 v 在第 206 行被添加到队列中,并被标记为已访问(第 207 行)。该方法现在检查队列中的每个顶点u(第210行)并将其添加到searchorder(第211行)。该方法将u的每个未访问的邻居e.v添加到队列(第214行),将其父级设置为u(第215行),并将其标记为已访问(第216行)。


2088shop商城购物系统是商城系统中功能最全的一个版本:非会员购物、商品无限级分类、不限商品数量、商品多级会员定价、上货库存、Word在线编辑器、订单详情销售报表、商品评论、留言簿、管理员多级别、VIP积分、会员注册积分奖励、智能新闻发布、滚动公告、投票调查、背景图片颜色更换、店标上传、版权联系方式修改、背景音乐(好歌不断)、广告图片支持Flash、弹出浮动广告、搜索引擎关健词优化、图文友情联
public class TestBFS {
public static void main(String[] args) {
String[] vertices = {"Seattle", "San Francisco", "Los Angeles", "Denver", "Kansas City", "Chicago", "Boston", "New York", "Atlanta", "Miami", "Dallas", "Houston"};
int[][] edges = {
{0, 1}, {0, 3}, {0, 5},
{1, 0}, {1, 2}, {1, 3},
{2, 1}, {2, 3}, {2, 4}, {2, 10},
{3, 0}, {3, 1}, {3, 2}, {3, 4}, {3, 5},
{4, 2}, {4, 3}, {4, 5}, {4, 7}, {4, 8}, {4, 10},
{5, 0}, {5, 3}, {5, 4}, {5, 6}, {5, 7},
{6, 5}, {6, 7},
{7, 4}, {7, 5}, {7, 6}, {7, 8},
{8, 4}, {8, 7}, {8, 9}, {8, 10}, {8, 11},
{9, 8}, {9, 11},
{10, 2}, {10, 4}, {10, 8}, {10, 11},
{11, 8}, {11, 9}, {11, 10}
};
Graph graph = new UnweightedGraph<>(vertices, edges);
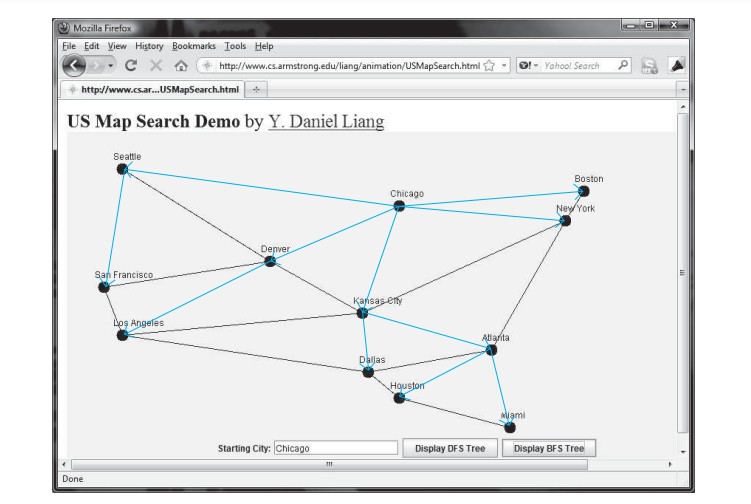
AbstractGraph.Tree bfs = graph.bfs(graph.getIndex("Chicago"));
java.util.List searchOrders = bfs.getSearchOrder();
System.out.println(bfs.getNumberOfVerticesFound() + " vertices are searched in this BFS order:");
for(int i = 0; i < searchOrders.size(); i++)
System.out.print(graph.getVertex(searchOrders.get(i)) + " ");
System.out.println();
for(int i = 0; i < searchOrders.size(); i++)
if(bfs.getParent(i) != -1)
System.out.println("parent of " + graph.getVertex(i) + " is " + graph.getVertex(bfs.getParent(i)));
}
}
按以下顺序搜索 12 个顶点:
芝加哥 西雅图 丹佛 堪萨斯城 波士顿 纽约
旧金山 洛杉矶 亚特兰大 达拉斯 迈阿密 休斯顿
西雅图的父母是芝加哥
旧金山的父母是西雅图
洛杉矶的父母是丹佛
丹佛的父母是芝加哥
堪萨斯城的母校是芝加哥
波士顿的父母是芝加哥
纽约的父母是芝加哥
亚特兰大的父母是堪萨斯城
迈阿密的父母是亚特兰大
达拉斯的父母是堪萨斯城
休斯顿的父母是亚特兰大
dfs 解决的很多问题也可以用 bfs 解决。具体来说,bfs可以用来解决以下问题:
- 检测图是否连通。如果图中任意两个顶点之间存在路径,则该图是连通的。
- 检测两个顶点之间是否存在路径。
- 寻找两个顶点之间的最短路径。可以证明bfs树中根到任意节点的路径都是根到节点的最短路径。
- 找到所有连接的组件。连通分量是最大连通子图,其中每对顶点都通过路径连接。
- 检测图中是否存在环路。
- 在图中找到一个循环。
- 测试图是否是二分图。 (如果图的顶点可以分为两个不相交的集合,使得同一集合中的顶点之间不存在边,则该图是二分图。)