
用python.requests爬取http://app1.sfda.gov.cn/datas...中的表格数据,但是python.requests返回的内容跟浏览器中看的不同,下面附上代码:
import requests
def testLoadRequest():
params1 = {
'tableId': '27',
'tableName': 'TABLE27',
'tableView': '%BD%F8%BF%DA%C6%F7%D0%B5',
'Id': '24583'
}
headers1 = {
'Content-Type': "text/html;encoding=gbk",
'X-Requested-With': 'XMLHttpRequest'
}
url1 = 'http://app1.sfda.gov.cn/datasearch/face3/content.jsp';
try:
r = requests.get(url1,params=params1, headers=headers1)
print(r.text)
print(r.cookies)
print(r.status_code)
print(r.url)
except Exception as e:
print(e)
testLoadRequest()
下面是浏览器看到的内容: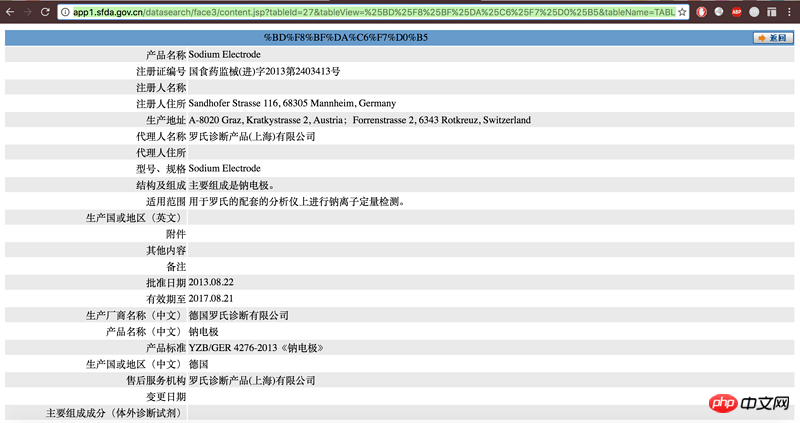
但是用python.requests爬到的html内容如下:
很明显爬出来的内容不是表格里的数据,而且有时还会爬不出来报
('Connection aborted.', ConnectionResetError(54, 'Connection reset by peer'))
这个错误,有知道原因的人吗??希望能给我点明一下,谢谢了



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 689
689
















帮测试了,请求源存在问题,
url1我更换了链接可以抓取成功。