
‘�û�δ��¼�������µ�¼’
就像类似与这样的问题,不知道是pycharm的问题,还是需要进行unicode方法进行转换~
开发环境是mac-os-x lion pycharm 是1.5.2的版本~



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 3
3 685
685

















Python 2 中文编码统一解决方案:
更新一下,来源于 http://www.newsmth.net/nForum/article...
对 @ninehills 的答案 我来补充一下:
其实如果想考虑今后迁移到 python 3 或者只是想使用 python 3 风格的默认 unicode, 可以使用
from __future__ import unicode_literals之后不需要再在所有中文字符串前加 u 了, 相反, 所有原来的"字符串"现在默认均为unicode串了. 如果需要使用utf-8串可以选择在前面加 b :)
题主所需要的答案是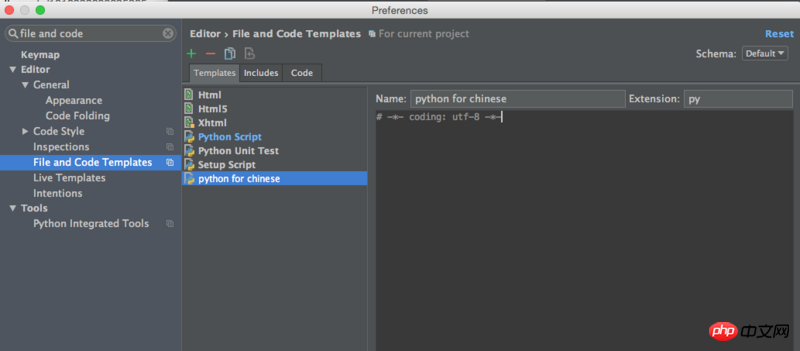
# -*- coding: utf-8 -*-这段代码加在每个文件之前,来识别中文。因为中文是默认UTF-8进行编码的,所以显示乱码。
那有种简单的方式可以长期解决问题,在Pycharm的help中找到find action,输入file and code templates.可以选择默认的模板样式,添加自定义的文件,输入这段代码,选择文件类型为python。以后每次创建新文件就创建这个就行了