
soup = BeautifulSoup(urlopen(url).read()) 这样做就解析不了网页soup.findAll('') 获取什么节点都没有
而把html = urlopen(url).read(),html打印出来,在控制台复制粘贴给变量 content,然后这样做 soup = BeautifulSoup(content),就能解析成功呢?



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 376
376

















输出:
测试平台:
运行结果,供楼主参考。
有图有真相:
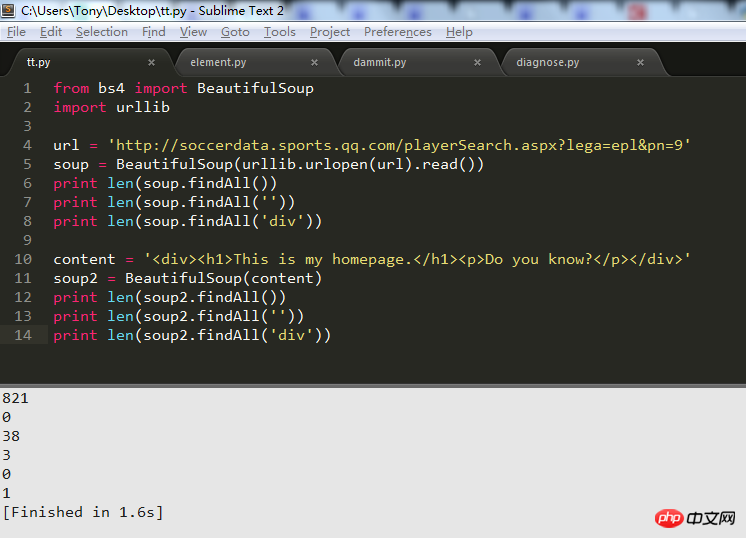
看一下你用的是哪个版本的bs吧