
需要用到这方面的数据,单独一页一页的复制了一段时间的数据,发现很是耗时,想从深圳市环保局下载空气质量历史数据。选择日期后,页面出现一个相应的数据表格,每天有24个时间点的。需要将每一天每一个小时的数据都爬下来。页面如下:
网址:http://www.szhec.gov.cn/pages/szepb/kqzl...
麻烦大家



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 3
3 2577
2577

















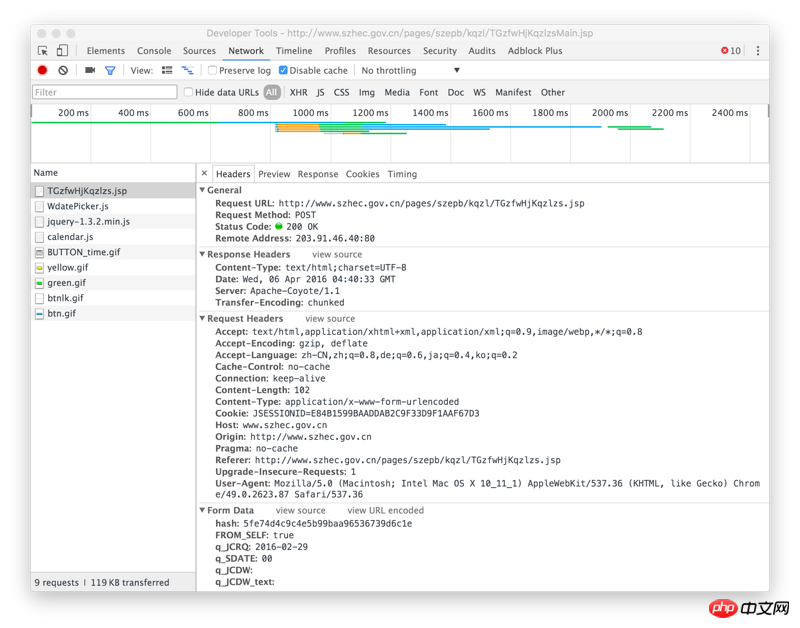
使用requests.post请求
上图的URL
hash值在上图的位置。
该图是response

#coding=utf-8
import requests
from bs4 import BeautifulSoup
get_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp?FLAG=FIRSTFW"#获取hash值
post_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp" #获取空气质量时报
html=requests.get(get_url)
#使用beautiful解析网页,获取hash值
html_soup=BeautifulSoup(html.text,"html.parser")
hash=html_soup.select("input[name=hash]")
hash=hash[0].get('value')
#构造data
data={
}
#至此已经正确获取了控制质量时报的信息
tqHtml=requests.post(post_url,data=data)
print tqHtml.text
右键检查元素,查看 network,选择一个时间搜索,查看调用的 ajax API 地址:
接上:
我大概用了这段代码试了下,程序既不报错也没有结果。请问错在哪?
import requests
import xlwt
from bs4 import BeautifulSoup
import datetime
import tqdm
def datelist(start, end):
def get_html():
def get_excel():
get_excel()