
目的:在网页 https://movie.douban.com/tv/#!type=tv&tag=%E8%8B%B1%E5%89%A7&sort=rank&page_limit=20&page_start=0上抓取评分超过x的所有英剧。
问题:在得到网页内容后,无法用find_all 方法找到
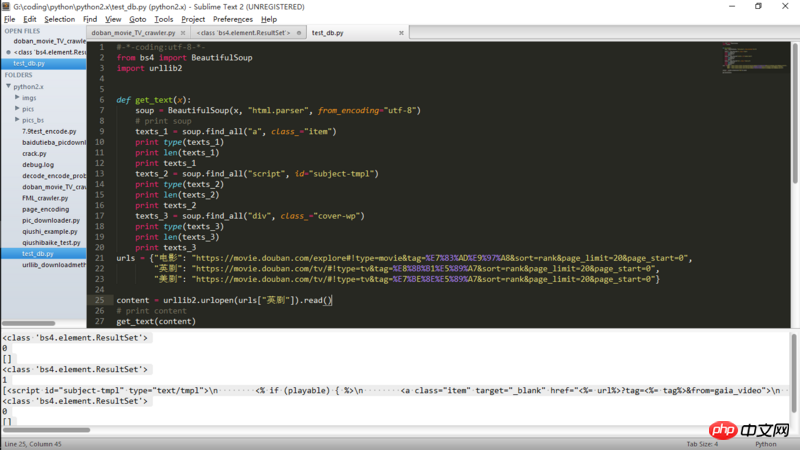
程序代码(问题部分):
#-*-coding:utf-8-*-
from bs4 import BeautifulSoup
import urllib2
def get_text(x):
soup = BeautifulSoup(x, "html.parser", from_encoding="utf-8")
# print soup
texts_1 = soup.find_all("a", class_="item")
print type(texts_1)
print len(texts_1)
print texts_1
texts_2 = soup.find_all("script", id="subject-tmpl")
print type(texts_2)
print len(texts_2)
print texts_2
texts_3 = soup.find_all("p", class_="cover-wp")
print type(texts_3)
print len(texts_3)
print texts_3
urls = {"电影": "https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=rank&page_limit=20&page_start=0",
"英剧": "https://movie.douban.com/tv/#!type=tv&tag=%E8%8B%B1%E5%89%A7&sort=rank&page_limit=20&page_start=0",
"美剧": "https://movie.douban.com/tv/#!type=tv&tag=%E7%BE%8E%E5%89%A7&sort=rank&page_limit=20&page_start=0"}
content = urllib2.urlopen(urls["英剧"]).read()
# print content
get_text(content)输出结果:
0
[]
1
[]
0
[]
[Finished in 0.9s] 截图:



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 772
772

















你看代码就知道,这个p标签在js代码块中,得运行js代码后,才能成为DOM节点的一部分。
但是你只读取HTML源码,并没有执行其中的js代码。
所以beautifulsoup用的HTML解析器并不认为
p class=”wp”是DOM树的一部分,find_all也就没有结果。解决方法的话,你直接写个正则匹配比较好,用bs4恐怕是不行。
至于正则怎么写,你可以看《正则表达式必知必会》这本书,10分钟就可以搞定了。