
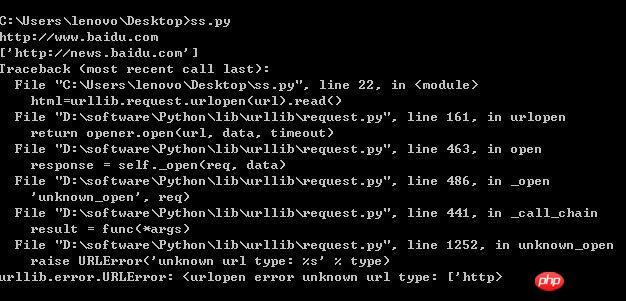
最近在学习python编程,在用beautifulsoup解析网页的时候,想用在程序中用解析出来的url继续访问,却被提示错误。百思不得其解,请各位大神帮助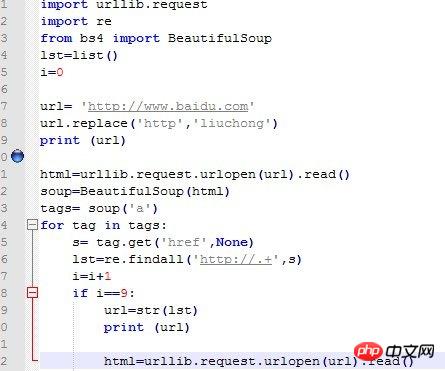



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 2
2 491
491

















你要把 url 從 list 裡面拿出來...
另外給兩個小小建議:
你可以試試看用改用
request庫,我覺得更加簡單一些。還有問問題代碼跟錯誤訊息盡量用文字貼,因為圖片不好複製代碼測試之類的。
我回答過的問題: Python-QA
推荐使用下面这种写法