扫码关注官方订阅号
欢迎选择我的课程,让我们一起见证您的进步~~
>>> import re >>> pattern = re.compile(r'^\u539f\u6587\u94fe\u63a5\uff1a<a href=\"(http:\/\/.*)\">$') >>> match = pattern.match('原文链接:<a href="http://www.darkreading.com">') >>> match.group(1) 'http://www.darkreading.com'
小提示,py2的话,可以用字符串前缀 u''如: ur'原文链接:<a href="(.*?)">'
ur'原文链接:<a href="(.*?)">'
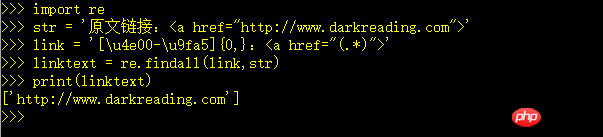
我写 js 的,正则的话,可以匹配 u... 这种汉字码,有个范围,u4e00-u9fa5 是简体好像。。。
要考虑你抓下的网页是用什么编码实现的
希望这是你想要的答案:
import re s='原文链接:<a href="http://www.darkreading.com">' ptn = re.compile('原文链接[^<]*?<a[^>]*?href="([^"]*)') print(ptn.findall(s))
微信扫码关注PHP中文网服务号
QQ扫码加入技术交流群
Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号
PHP学习
技术支持
返回顶部



 0
0  6
6 479
479



















小提示,py2的话,可以用字符串前缀 u''
如:
ur'原文链接:<a href="(.*?)">'我写 js 的,正则的话,可以匹配 u... 这种汉字码,有个范围,u4e00-u9fa5 是简体好像。。。
要考虑你抓下的网页是用什么编码实现的
希望这是你想要的答案: