
2024年cvpr:视觉foundation model引领ai新浪潮
2024年6月17日至21日,IEEE国际计算机视觉与模式识别会议(CVPR)在美国西雅图举行。今年的CVPR,视觉Foundation Model成为除自动驾驶、3D视觉等传统研究领域外的核心主题,备受瞩目。 受快手“可灵”图生视频功能爆火和Runway Gen-3 Alpha模型发布的影响,“文生视频”也成为一大热点。
CVPR 2024两篇最佳论文均授予AIGC相关研究。论文接收数量方面,图像和视频合成与生成领域以329篇论文位居榜首,而文生视频也属于视觉Foundation Model的研究范畴。事实上,Foundation Model在人工智能领域的早期突破正是在计算机视觉领域。
2021年,斯坦福大学学者发布的Foundation Model综述就涵盖了众多计算机视觉领域专家,但OpenAI在自然语言处理领域的Foundation Model上率先取得领先地位。然而,Sora和“可灵”等技术的惊艳效果,再次将视觉Foundation Model推至研究前沿。
AI科技评论对多位视觉Foundation Model研究者进行了采访,总结出以下关键发现:
除了Foundation Model,采访还涉及自动驾驶和3D视觉领域。 受访者指出,像CVPR这样的学术会议,其论文接收和会议召开时间跨度过长,可能已无法及时反映快速发展的研究成果。 AI研究中,工业界和学术界的界限日益模糊,学术会议也需要适应时代变化。
Foundation Model的瓶颈与突破方向
基于Transformer的通用视觉基础模型并非新兴概念。 微软Swin Transformer、谷歌ViT以及上海人工智能实验室的“书生”(Intern)系列都进行了早期探索,但都被Sora的光芒所掩盖。 Sora的技术路径也为后续研究提供了新的借鉴方向。
上海人工智能实验室的OpenGVLab团队在CVPR 2024上展示了其最新的视觉多模态基础模型InternVL-1.5。该模型凭借强大的视觉编码器InternViT-6B、高动态分辨率和高质量双语数据集,在业内获得高度评价。
OpenGVLab团队认为,视觉基础模型的关键在于构建多模态对话系统。InternVL-26B的研究始于2023年3月,其目标是在保持模型强大性和多功能性的前提下,将其作为对话系统的骨干,支持图像检测、分割以及图文检索等多模态任务。
InternVL-1.5的技术报告指出,视觉基础模型研究的三个关键点是:强大的语言模型支持、高分辨率适配和高质量数据集。 研究人员认为,GPT-4o等模型注重不同模型间的跨模态转换,而InternVL则专注于单个模型内不同模态的输入和文本理解的输出,两者并非相互排斥的路线。
一些研究者提出,视觉基础模型应具备更强的离散化特性,将各个模态转换为离散表示,以实现更统一的多模态处理。 但研究人员也指出,这种方法可能损失关键信息,仍需进一步探索。
思谋科技研究员张岳晨和南洋理工大学副教授张含望也分别就视觉基础模型的瓶颈和突破方向提出了各自的见解,他们都强调了高质量数据的获取、原生多模态支持以及解决“理解”和“生成”任务互斥问题的重要性。 张含望教授特别指出,视觉token的改进是将视觉信息有效接入大语言模型的关键。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
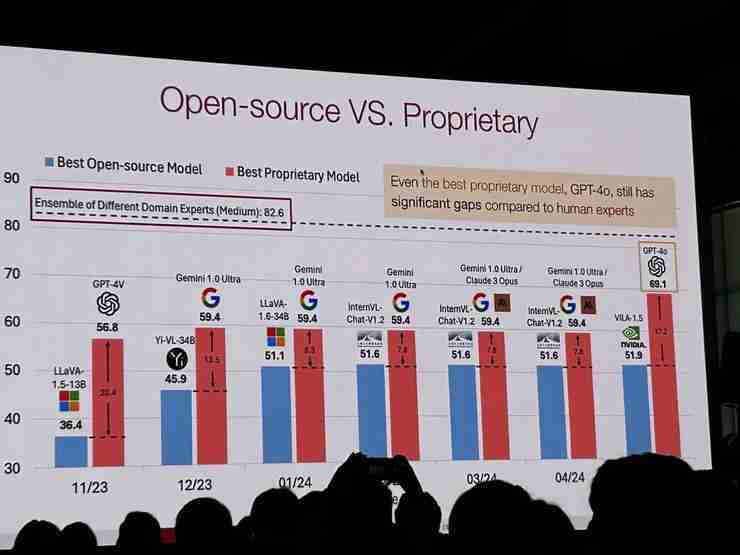
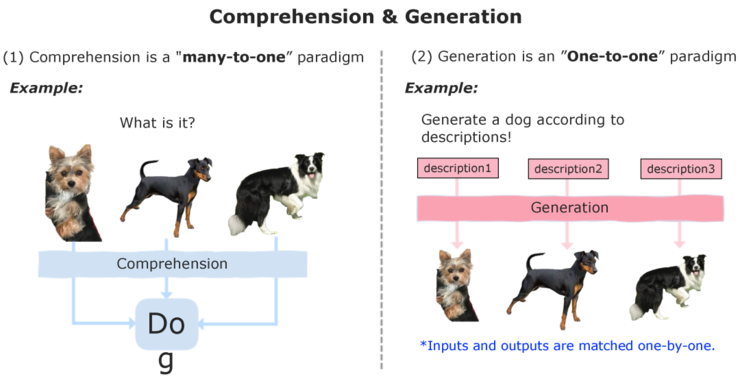
自动驾驶和端侧AI
自动驾驶在CVPR 2024上也占据重要地位,尤其关注将大语言模型应用于自动驾驶场景。 核心挑战在于如何在保证安全性的前提下,让大模型理解环境并预测车辆行驶轨迹。
今年的一个趋势是利用大语言模型为自动驾驶端到端技术提供新的解决方案,例如使用生成式AI构建仿真平台。 CVPR 2024自动驾驶国际挑战赛吸引了众多团队参赛,英伟达联合复旦大学的团队获得了冠军。
英伟达的研究人员介绍了其在端到端自动驾驶中的创新,即在数据量不足的情况下,使用基于规则的专家系统作为教师,将规则知识蒸馏给神经网络规划器。


苹果的多模态LLM模型
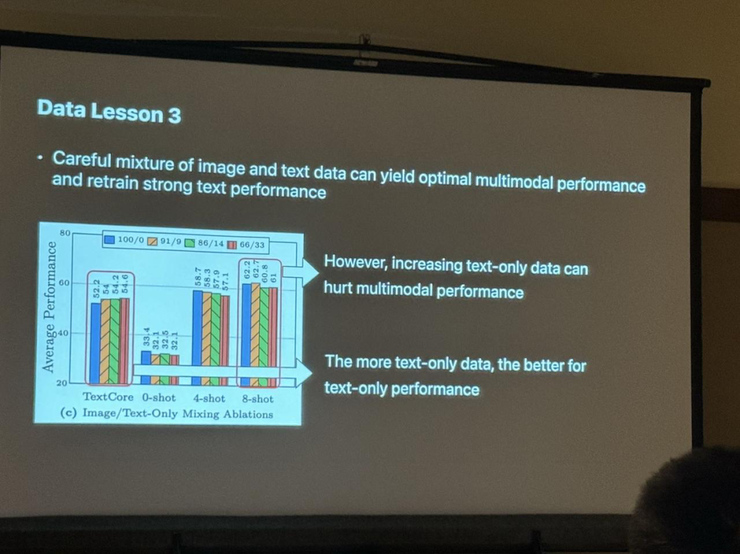
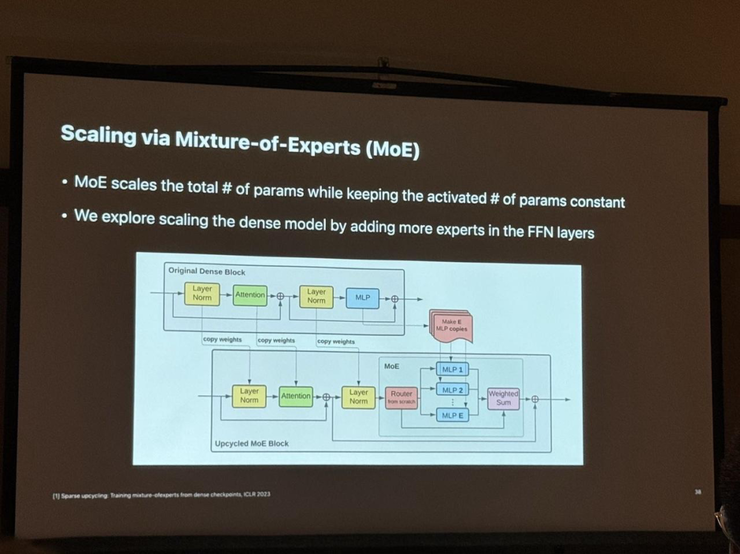
苹果公司也在CVPR 2024上展示了其在多模态LLM模型方面的最新研究进展。 苹果的研究人员介绍了如何通过高质量的数据混合和改进的MoE架构来提升多模态大模型的性能。


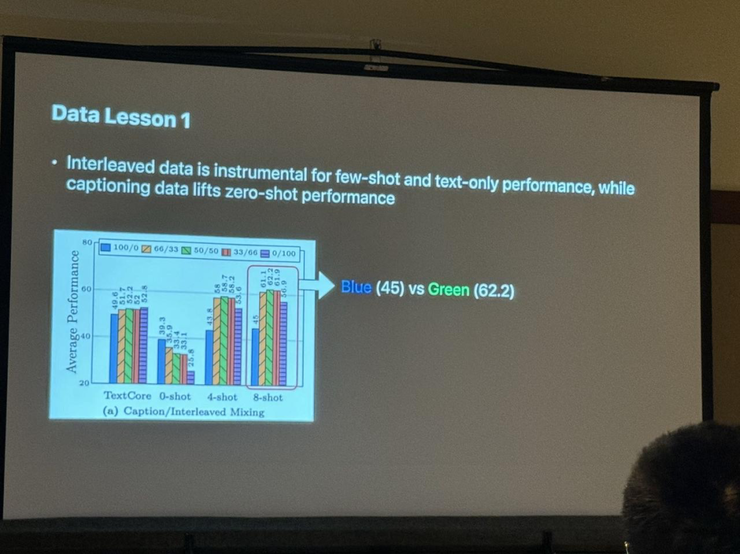
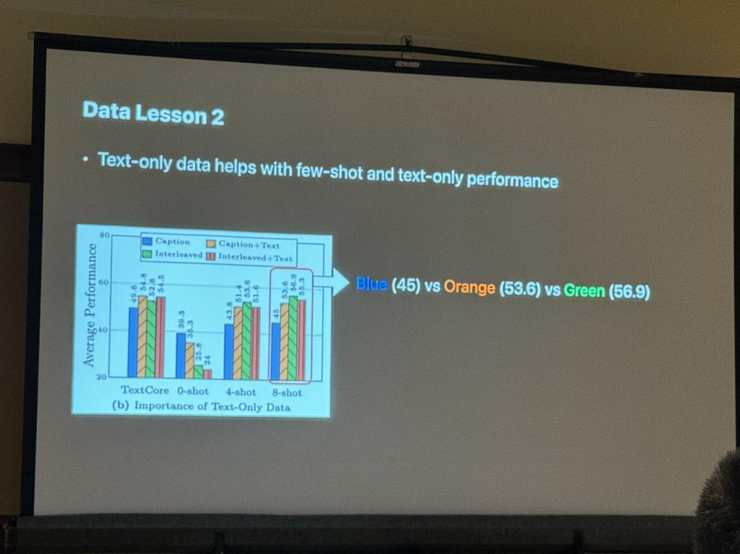
总结
CVPR 2024展现了AIGC技术在计算机视觉领域的蓬勃发展,但也引发了对学术会议适应性以及未来研究方向的思考。 未来,计算机视觉研究可能从虚拟世界转向物理世界,并以多种形式呈现。
以上就是视觉 AI 的「Foundation Model」,已经发展到哪一步?丨CVPR 2024 现场直击的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 692
692



















