
deepseek r1 今年一月横空出世,其创新方法和极低的算力需求,给英伟达等巨头带来了巨大冲击,也引发了业界对agi发展路径的深刻反思。通往agi之路并非只有扩大算力规模一条路,更高效的方法才能带来更多创新。
近期,全球众多科技公司和研究团队都在尝试复现DeepSeek。而就在此时,一项名为s1的新方法宣告问世,它大幅提升了AI的推理效率。你或许会感到难以置信!  s1论文作者,斯坦福大学在读博士Niklas Muennighoff指出,DeepSeek R1令人兴奋,但其缺乏OpenAI的测试时间扩展图,且需要海量数据。而s1仅需1000个样本和简单的测试时间干预,即可复现o1的预览扩展和性能。
s1论文作者,斯坦福大学在读博士Niklas Muennighoff指出,DeepSeek R1令人兴奋,但其缺乏OpenAI的测试时间扩展图,且需要海量数据。而s1仅需1000个样本和简单的测试时间干预,即可复现o1的预览扩展和性能。
这项由斯坦福大学、华盛顿大学等机构主导的研究,探索了一种极简的测试时间扩展(test-time scaling)方法。令人惊叹的是,该方法仅用1000个问题训练模型,就实现了超越o1的强推理性能。
测试时间扩展是一种极具潜力的语言建模新方法,它利用额外的测试时间计算来提升模型性能。OpenAI的o1模型曾展示了这种能力,但其方法并未公开。许多研究都致力于复现o1,尝试了蒙特卡洛树搜索、多智能体等多种方法。而今年一月开源的DeepSeek R1,则通过数百万样本的多阶段强化学习,成功实现了o1级别的性能。
s1研究人员则另辟蹊径,寻求最简化的测试时间扩展方法。他们构建了一个包含1000个问题的s1K数据集,并根据难度、多样性和质量三个标准,与推理轨迹进行匹配。
基于此,研究人员提出了“预算强制”技术,通过强制终止模型的思考过程,或在模型试图结束时多次添加“等待”指令来延长思考时间,从而控制测试时间计算。 这有助于模型仔细检查答案,修正错误的推理步骤。
在s1K数据集上,研究人员对Qwen2.5-32B-Instruct语言模型进行了监督微调(使用16块H100 GPU,耗时26分钟),并应用了预算强制技术。最终得到的s1-32B模型,在竞赛数学问题上的表现,比o1-preview高出27%(MATH和AIME24)。 s1性能与其他大模型的对比。
s1性能与其他大模型的对比。
测试时间扩展
本文将测试时间扩展方法分为两类:1. 序列扩展(后续计算依赖于先前结果);2. 并行扩展(计算独立运行)。
本文重点关注序列扩展,因为它更具扩展性,后续计算可以基于中间结果进行迭代优化。
此外,本文还提出了一种新的序列扩展方法及基准测试方法:预算强制(Budget forcing)。该方法通过在测试时强制设定最大或最小思考token数量来实现解码时间干预。 具体来说,通过添加思考结束token分隔符和“Final Answer:”来强制设定最大token数量;而通过抑制思考结束token分隔符的生成,并添加“Wait”指令,来强制设定最小token数量。
具体来说,通过添加思考结束token分隔符和“Final Answer:”来强制设定最大token数量;而通过抑制思考结束token分隔符的生成,并添加“Wait”指令,来强制设定最小token数量。
基准测试方法包括:条件长度控制方法(token、步骤、类条件控制)和拒绝采样。
实验
训练阶段:使用s1K数据集对Qwen2.5-32B-Instruct进行监督微调,得到s1-32B模型(16块NVIDIA H100 GPU,26分钟)。
评估:使用AIME24、MATH500和GPQA Diamond三个推理基准进行评估。
对比模型:OpenAI o1、DeepSeek r1、Qwen QwQ-32B-preview等。s1-32B完全开源,包括权重、推理数据和代码。
性能
测试时间扩展: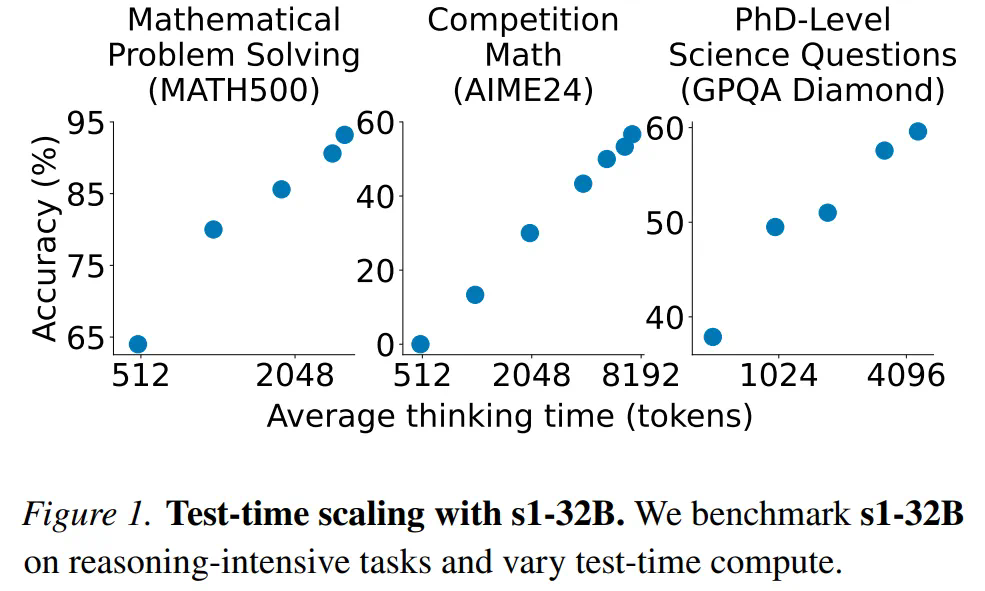
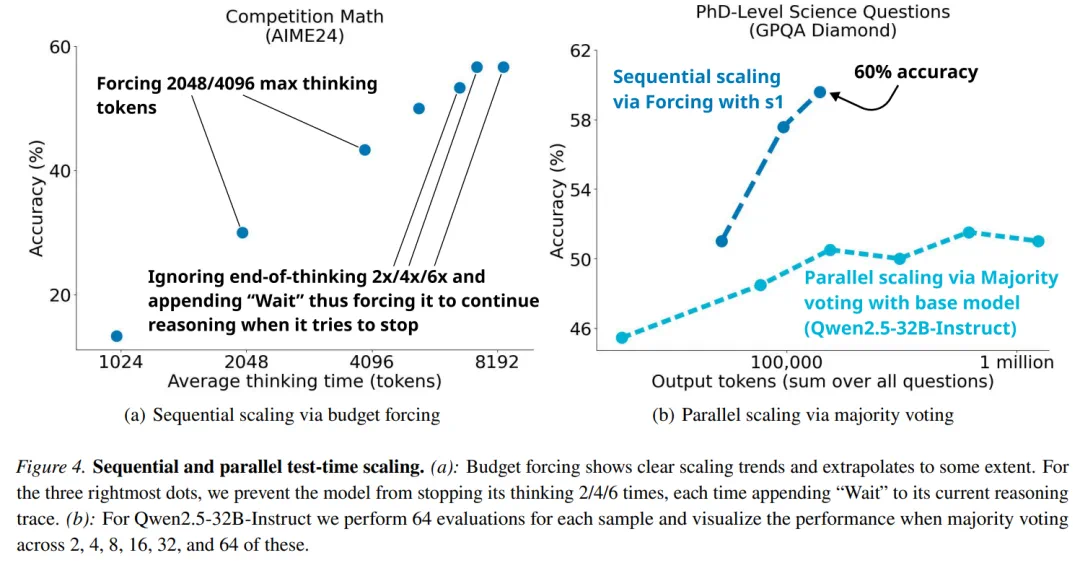 结果显示,过度抑制思考结束token可能会导致模型陷入循环。序列扩展比并行扩展更有效。
结果显示,过度抑制思考结束token可能会导致模型陷入循环。序列扩展比并行扩展更有效。
样本效率: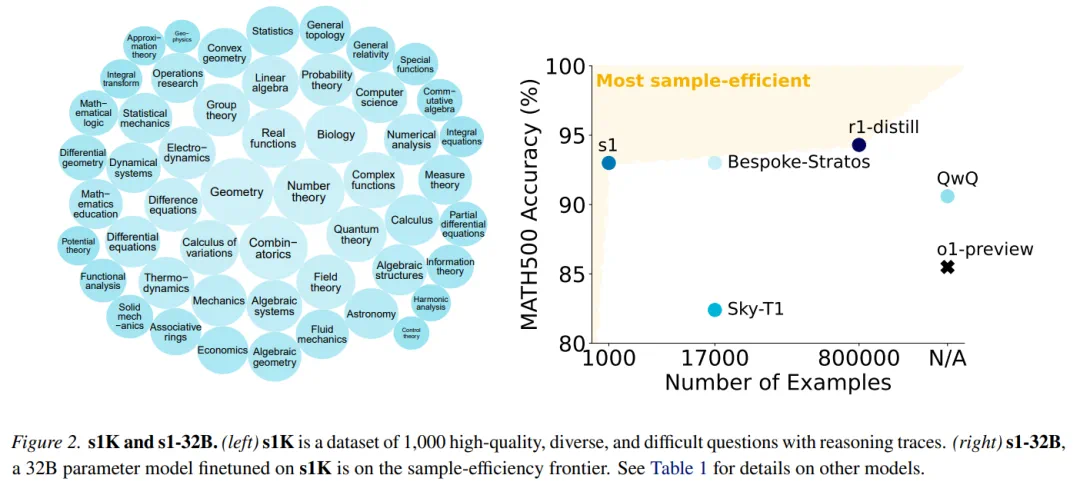
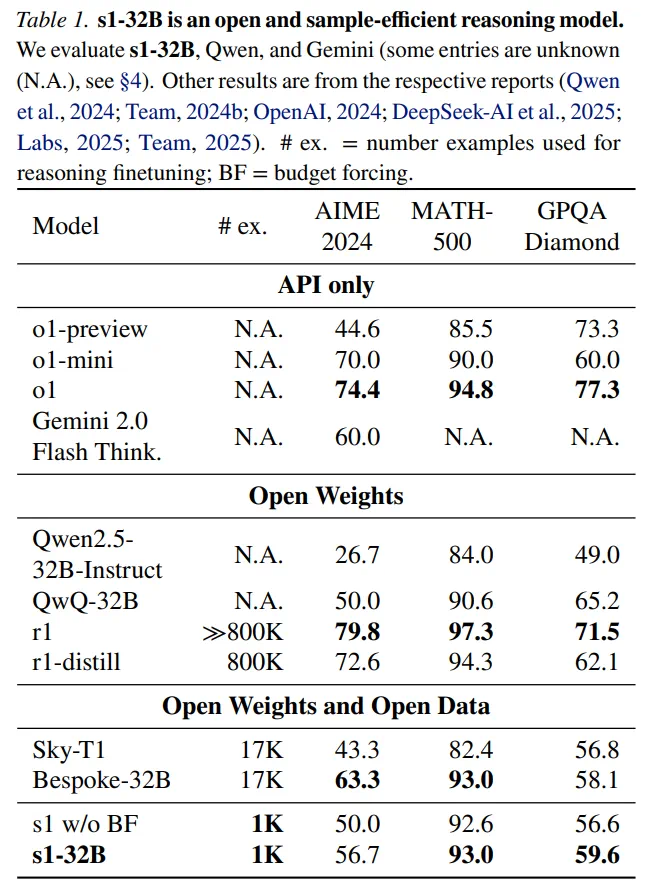 s1-32B是样本效率最高的开放数据推理模型,仅用1000个样本就取得了优异的性能。 s1-32B在AIME24上的表现与Gemini 2.0 Thinking不相上下。
s1-32B是样本效率最高的开放数据推理模型,仅用1000个样本就取得了优异的性能。 s1-32B在AIME24上的表现与Gemini 2.0 Thinking不相上下。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 文中还包含了详细的消融实验结果,感兴趣的读者可以参考原文论文。
文中还包含了详细的消融实验结果,感兴趣的读者可以参考原文论文。
以上就是训练1000样本就能超越o1,李飞飞等人画出AI扩展新曲线的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 409
409


















