
最新研究揭示大语言模型推理能力的局限性:enigmaeval 基准测试结果
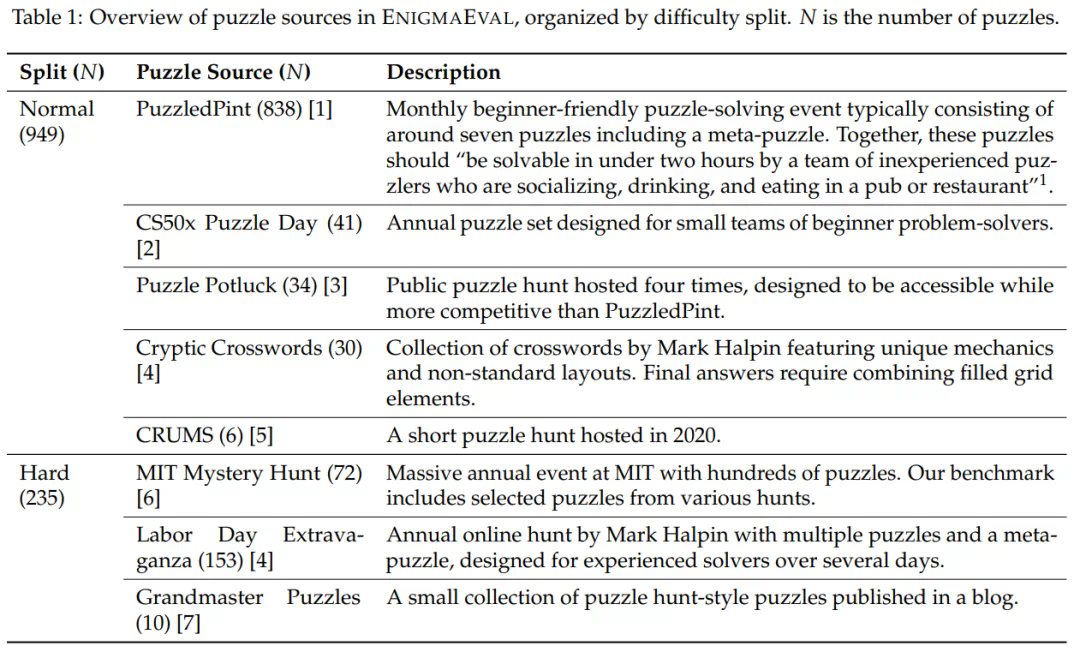
Scale AI、Center for AI Safety 和 MIT 的研究人员联合发布了新的多模态推理基准测试 ENIGMAEVAL,再次挑战了大语言模型的推理能力。该基准包含 1184 个难题,涵盖解谜寻宝竞赛中的各种类型,测试模型的逻辑推理、创造性思维和跨学科知识运用能力。难题分为普通难度 (Normal) 和困难难度 (Hard) 两类,分别包含 949 道和 235 道题目。 难题以原始 PDF 图片和结构化文本-图像两种格式提供,以评估模型的端到端能力和独立推理能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

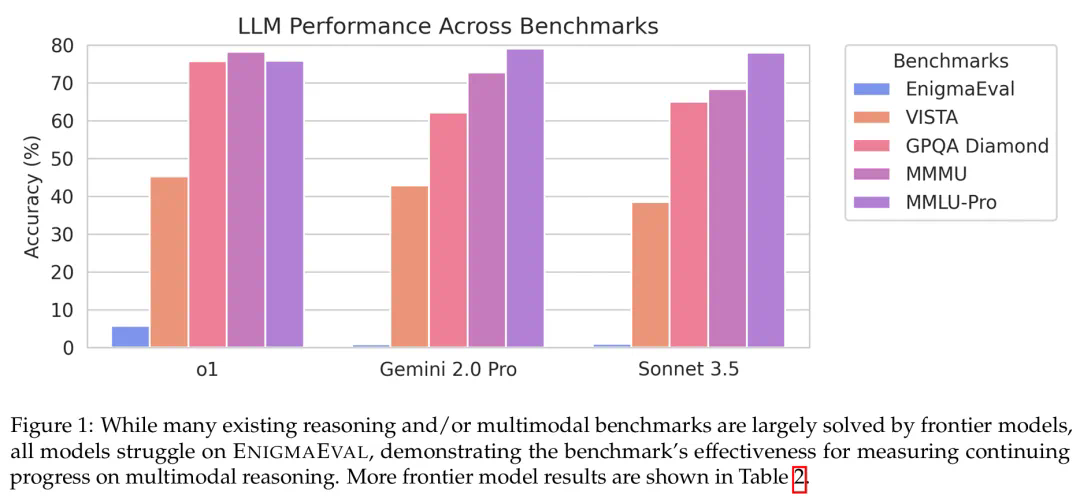
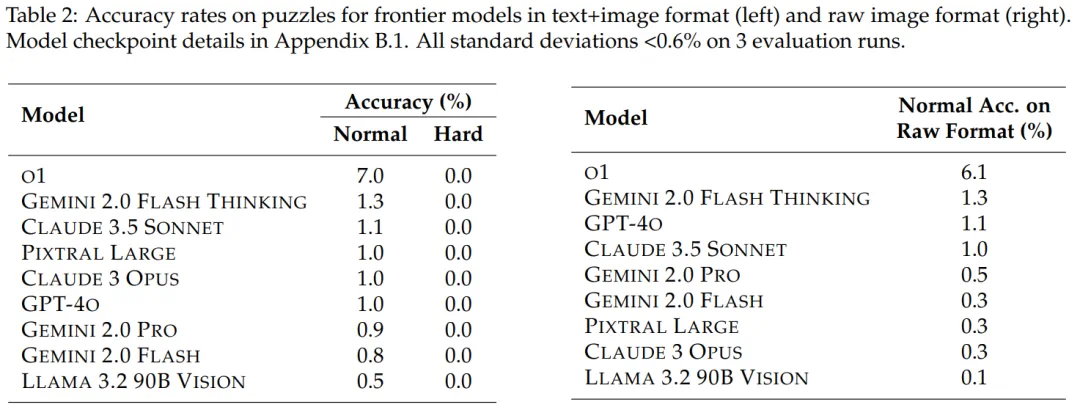
测试结果显示,即使是像 OpenAI 的 o1 这样的顶尖模型,在普通难度谜题上的准确率也仅为 7.0% 左右,在困难难度谜题上的准确率则为 0%。这与经验丰富的人类解谜者的表现形成鲜明对比。 研究发现,模型在处理原始 PDF 格式的谜题时,性能会显著下降,这表明一些前沿模型的 OCR 和文档解析能力仍然存在限制。
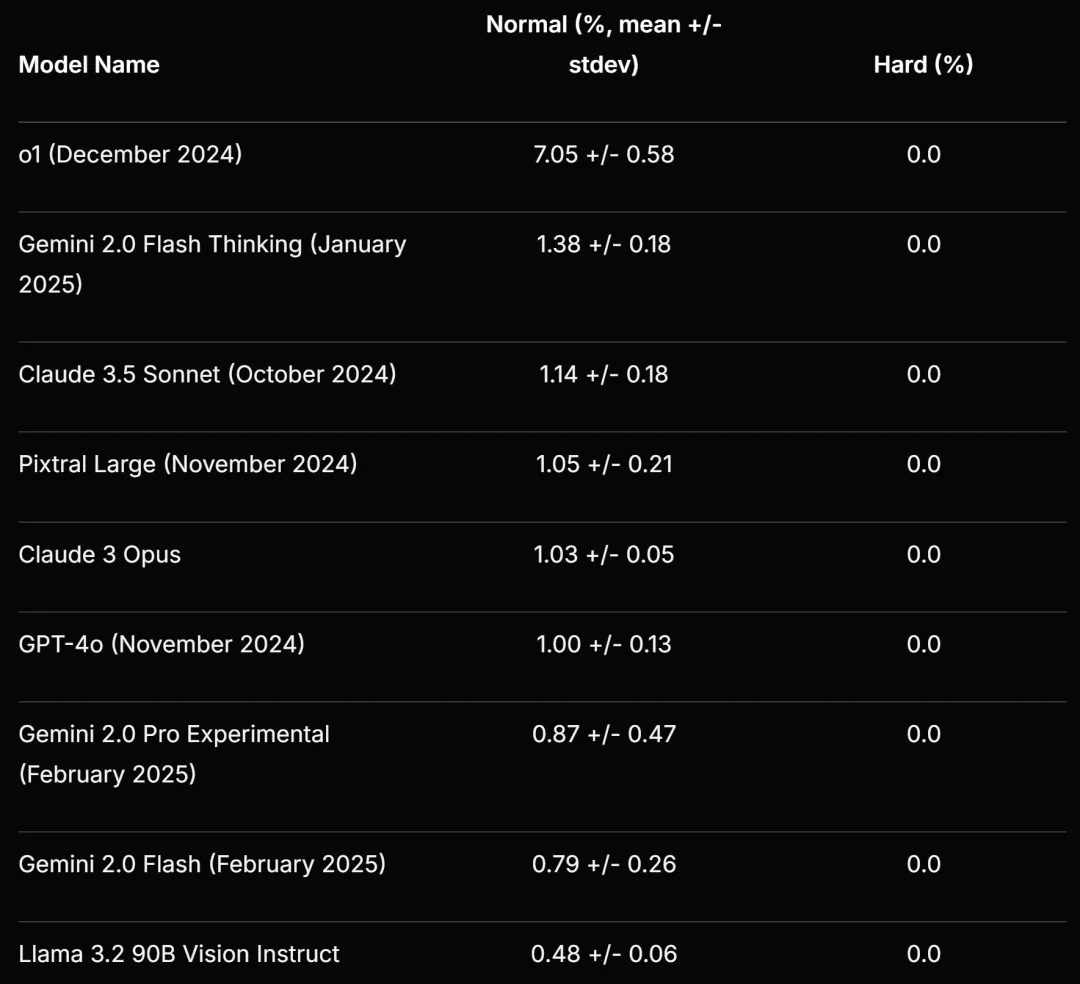
ENIGMAEVAL 基准与此前发布的“人类的最后考试”(HLE)基准一起,为评估大语言模型提供了更全面的视角,并突显了当前模型在复杂推理任务上的不足。 研究人员指出,AI 距离真正理解世界还有很长的路要走。 值得注意的是,DeepSeek R1 未参与本次测试,其表现值得关注。


ENIGMAEVAL 基准的谜题来源及难度分布如下表所示:
普通难度谜题示例:

困难难度谜题示例:

实验结果表明,所有测试的顶尖 LLM 在 ENIGMAEVAL 上的表现都不理想,尤其是在困难难度谜题上完全失败。 这进一步强调了当前大语言模型在复杂推理方面的挑战。
以上就是AI无法攻克的235道谜题!让o1、Gemini 2.0 Flash Thinking集体挂零的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 773
773
























