
月之暗面发布moba注意力机制,高效处理超长文本!近日,月之暗面团队公开了一种名为moba(mixture of block attention,块注意力混合)的全新注意力机制,该机制巧妙地将混合专家(moe)原理应用于注意力机制,并在长文本处理方面展现出显著优势。这与deepseek同期发布的nsa注意力机制论文异曲同工,都致力于解决传统注意力机制计算复杂度高的问题。然而,moba更进一步,不仅发布了论文,还公开了经过一年实际部署验证的代码,确保了其有效性和稳健性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

MoBA论文指出,随着大语言模型(LLM)规模的不断扩大,处理长序列的能力成为实现通用人工智能(AGI)的关键。传统注意力机制的计算复杂度呈二次方增长,限制了LLM处理长序列的能力。现有方法通常通过预定义结构(如基于sink的注意力或滑动窗口注意力)或动态稀疏注意力来解决这个问题,但这些方法往往依赖特定任务,泛化能力有限,或无法显著降低训练成本。线性注意力模型虽然降低了计算开销,但适配现有Transformer模型成本高昂,且有效性证据有限。
MoBA的创新之处在于,它遵循“更少结构”原则,允许模型自主决定关注哪些位置。它将上下文划分为块,并利用门控机制选择性地将查询token路由到最相关的块,从而实现块稀疏注意力,显著降低计算成本。模型能够动态选择信息量最大的关键块,提升性能和效率。

MoBA主要包括以下部分:可训练的块稀疏注意力、无参数门控机制以及完全注意力与稀疏注意力的无缝切换能力。它通过整合FlashAttention和MoE的优化技术,实现了高性能版本。MoBA的实现过程包含五个步骤:确定查询token对KV块的分配、安排查询token顺序、计算注意力输出、重新排列输出以及合并注意力输出。

月之暗面团队进行了大量的实验,包括Scaling Law和消融实验,验证了MoBA的有效性。实验结果表明,MoBA在保持与Full Attention相当性能的同时,显著提升了效率,在处理百万级token时速度提升了6.5倍。 MoBA的块粒度对其性能有显著影响,细粒度分割能提升模型性能。 此外,研究团队还探索了MoBA与Full Attention的混合训练策略,以平衡训练效率和模型性能。 他们还提出了分层混合策略,以解决SFT期间可能出现的性能下降问题。





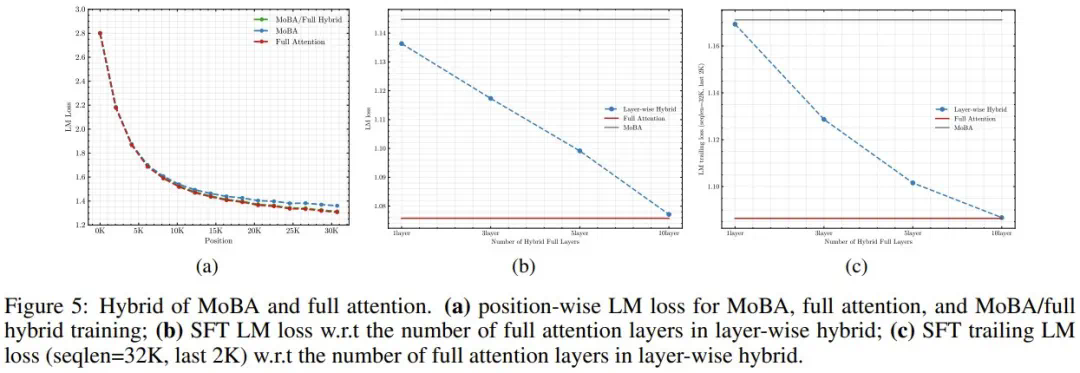


基于Llama 3.1 8B模型,月之暗面团队开发了Llama-8B1M-MoBA模型,并将其上下文长度扩展到百万级token。 实验结果表明,MoBA模型在性能上与Full Attention模型相当,并在效率上取得了显著提升,尤其在处理超长文本场景下优势明显。 MoBA为高效处理超长文本提供了新的解决方案,具有重要的研究价值和应用前景。 更多细节请参考原文论文:https://www.php.cn/link/802ff97a1290381d236bd78ab83b84bb
以上就是撞车DeepSeek NSA,Kimi杨植麟署名的新注意力架构MoBA发布,代码也公开的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 267
267



















