
ai领域昨日捷报频传:马斯克xai发布了grok-3旗舰大模型;deepseek梁文锋团队则公开全新注意力架构nsa。openai迅速回应,推出并开源了swe-lancer基准测试,用于评估ai大模型的软件工程能力。该基准包含1400多个来自upwork平台的真实软件工程任务,总价值高达百万美元。这意味着,如果模型能完成所有任务,就能获得同等报酬。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

SWE-Lancer基准涵盖独立工程任务(例如bug修复和功能实现)和管理任务,任务难度和报酬成正比。独立工程任务经三重验证的端到端测试评级,管理任务则根据工程经理的评估结果判定。

SWE-Lancer任务模拟了现代软件工程的复杂性,平均耗时超过21天。


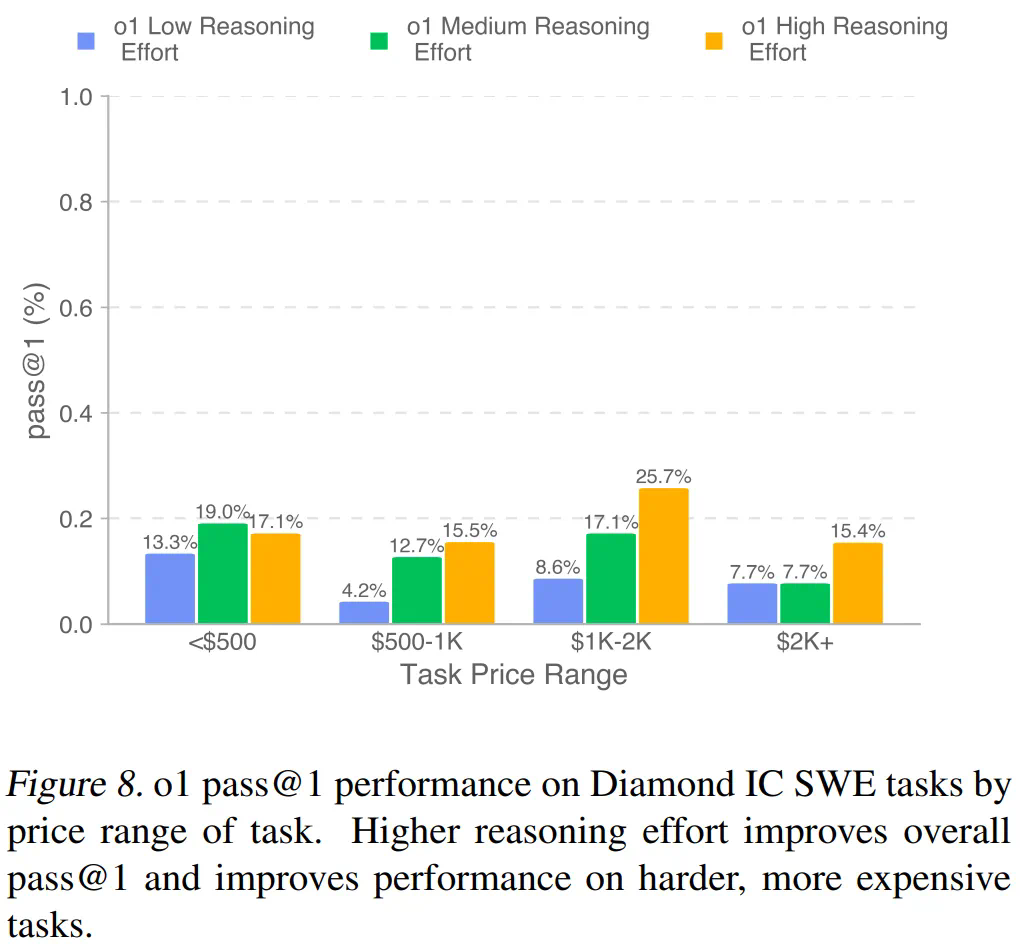
OpenAI的测试结果显示,包括GPT-4o、o1和Anthropic Claude 3.5 Sonnet在内的顶尖模型仍无法解决大部分任务。Claude 3.5 Sonnet表现最佳,完成任务价值达403,325美元。

为促进研究,OpenAI开源了统一的Docker镜像和SWE-Lancer Diamond公共评估集。通过将模型性能与实际经济价值挂钩,OpenAI旨在深入研究AI模型开发的经济效益。

SWE-Lancer数据集包含1488个来自Upwork的软件工程任务,总价值百万美元,分为个人贡献者(IC)任务和管理任务两类。IC任务侧重于bug修复和功能实现,管理任务则模拟软件工程经理的角色选择最佳解决方案。

SWE-Lancer数据集由OpenAI研究人员和100名软件工程师创建,确保任务真实性,并避免模型作弊。
测试结果显示,现有模型难以完全胜任真实软件工程任务,虽然能辅助解决一些问题,但距离完全取代人类工程师还有距离。模型在定位问题方面表现出色,但在深入理解和解决根本问题方面仍有不足。




以上就是Claude挣钱强于o1!OpenAI开源百万美元编码基准,检验大模型钞能力的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 222
222























