
dify 支持集成 ollama 部署的大型语言模型 (llm) 推理和嵌入能力。
下载并运行 Ollama: 请参考 Ollama 官方文档进行本地部署和配置。运行 Ollama 并启动 Llama 模型,例如:ollama run llama3.1。成功启动后,Ollama 会在本地 11434 端口启动 API 服务,访问地址为 http://localhost:11434。更多模型信息请访问 https://www.php.cn/link/5aa99ed4dc2312e348d37fc9da80eb5b。
在 Dify 中配置 Ollama: 在 Dify 的“设置 > 模型供应商 > Ollama”页面填写以下信息:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
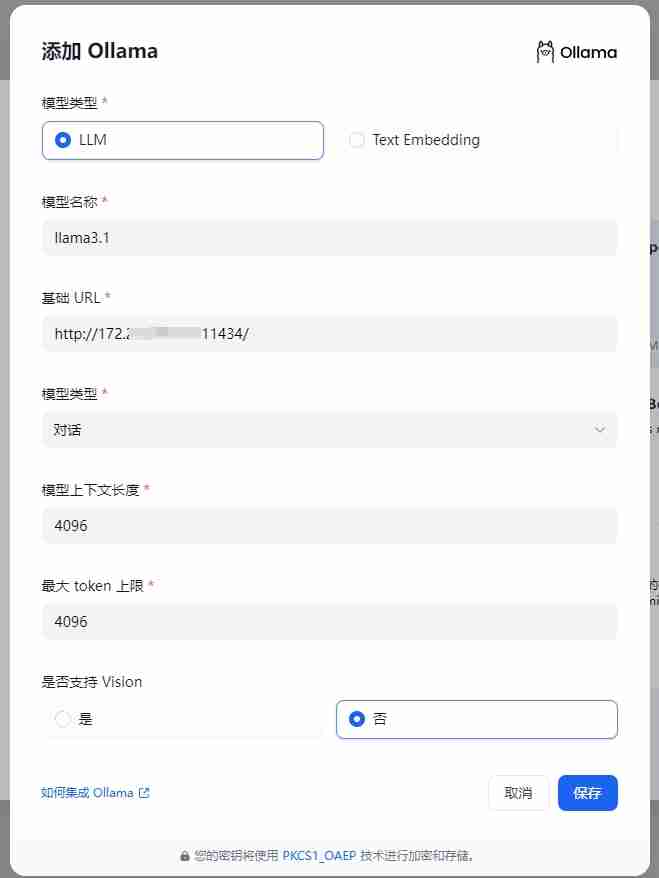
llama3.1 (或您选择的模型名称)http://192.168.1.100:11434) 或 Docker 宿主机 IP 地址 (例如 http://172.17.0.1:11434)。 您可以使用 ip addr show (Linux/macOS) 或 ipconfig (Windows) 命令查找您的 IP 地址。http://localhost:11434。对话 (或 文本嵌入,取决于您使用的模型)4096 (或模型支持的最大上下文长度)4096 (或模型支持的最大 token 数量)是 (如果模型支持图像理解)保存配置后,Dify 将验证连接。
使用 Ollama 模型: 在 Dify 应用的提示词编排页面选择 Ollama 供应商下的 llama3.1 模型,设置参数后即可使用。
⚠️ Docker 部署下的连接错误:
如果您使用 Docker 部署 Dify 和 Ollama,可能会遇到连接错误,例如 Connection refused。这是因为 Docker 容器无法访问 Ollama 服务。 解决方法是将 Ollama 服务暴露给网络,并使用正确的 Ollama 服务地址 (例如 Docker 宿主机 IP 地址) 在 Dify 中进行配置。
不同操作系统下的环境变量设置:
launchctl setenv OLLAMA_HOST "0.0.0.0" 设置环境变量,重启 Ollama 应用。 如果无效,尝试使用 host.docker.internal 替换 localhost。systemctl edit ollama.service 编辑 systemd 服务文件,添加 Environment="OLLAMA_HOST=0.0.0.0",然后 systemctl daemon-reload 和 systemctl restart ollama。OLLAMA_HOST,然后重新启动 Ollama。如何暴露 Ollama 服务:
Ollama 默认绑定到 127.0.0.1:11434。 您可以通过设置 OLLAMA_HOST 环境变量将其绑定到 0.0.0.0,使其在网络上可见。 请注意网络安全,并仅在受信任的网络环境中这样做。
以上就是Ollama 本地部署模型接入 Dify的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 964
964





















