







uniact:一种新型具身基础模型框架
UniAct 是一种创新的具身基础模型框架,旨在解决机器人行为的异构性问题。它通过学习通用行为,提取不同机器人共享的原子行为特征,从而克服由物理形态和控制接口差异造成的行为不一致性。UniAct 的架构主要由通用行为提取器、通用行为空间和异构解码器三部分构成。通用行为提取器基于视觉语言模型,通过观察和任务目标来提取通用行为;通用行为空间采用向量量化码本的形式,每个向量代表一种原子行为;异构解码器则负责将通用行为转化为特定机器人的控制信号。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
核心功能:
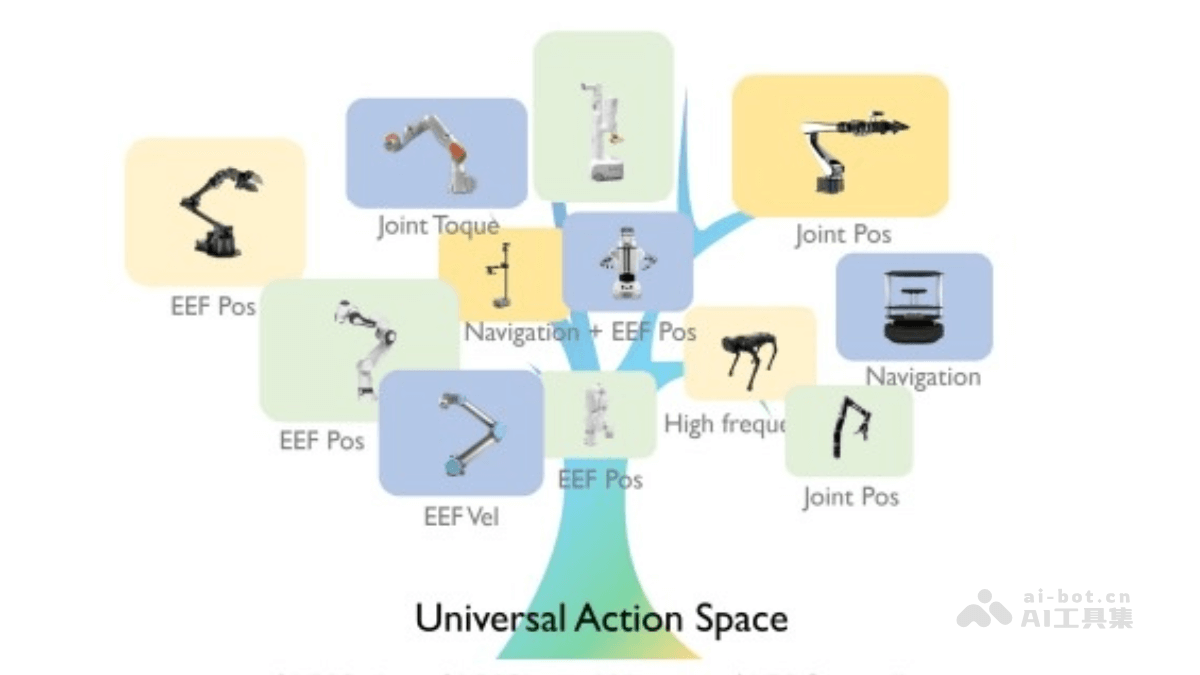
- 通用动作编码: UniAct 将不同机器人的原子行为(例如“移动到目标位置”或“避开障碍物”)转化为通用的向量化码本,每个代码代表一种可跨平台共享的通用技能。
- 轻量高效: UniAct-0.5B 模型仅需 0.5 亿参数,其真实和模拟环境下的任务表现已超越参数规模达 14 亿的 OpenVLA 模型。
- 快速适应性: UniAct 仅需 50 条专用示教数据即可在新环境中微调,并能快速适应新的机器人和控制接口。只需添加轻量级解码器,即可轻松扩展到新的机器人平台。
- 跨领域数据利用: UniAct 通过通用行为空间,更有效地利用跨领域数据进行训练,从而在不同机器人和环境中实现更强大的泛化能力。
- 行为一致性: 在不同的部署场景和机器人类型上,相同的通用动作能展现出一致的行为模式,为具身智能体的控制提供了更便捷的方式。用户只需从码本中选择相应的通用动作,即可指挥不同类型的机器人完成任务。
技术原理详解:

- 通用动作空间: UniAct 利用向量量化构建了一个离散的通用动作空间,该空间是一个向量化码本,每个向量嵌入代表一种通用的原子行为。这些原子行为是不同机器人在不同环境下共享的基本行为模式。
- 通用动作提取器: 基于视觉语言模型 (VLM),UniAct 的通用动作提取器能够识别和提取通用动作。它根据观察结果和任务目标,输出选择通用动作的概率。
- 异构解码器: UniAct 使用异构解码器将通用动作转换为特定机器人的可执行命令。这些解码器针对不同的机器人平台进行设计,能根据机器人的具体特征将通用动作转换为具体的控制信号。
- 轻量化架构与高效训练: UniAct 采用轻量化模型架构,即使参数较少也能保持优异的性能。它通过行为克隆损失进行训练,并根据动作标签的性质选择合适的损失函数。
项目信息:
- 项目官网: https://www.php.cn/link/a87823bb4525992c4faeea10b5965d6c
- Github 仓库: https://www.php.cn/link/0ce16f5baef00b294afeb0163b5d1d4b
- arXiv 技术论文: https://www.php.cn/link/384aa2c2ca5996fc30438d97a5550988
应用场景:
UniAct 的应用前景广泛,包括自动驾驶、医疗机器人、工业自动化和智能家居等领域。其通用性使其能够高效地控制各种类型的机器人,并适应不同的环境和任务需求。




























