
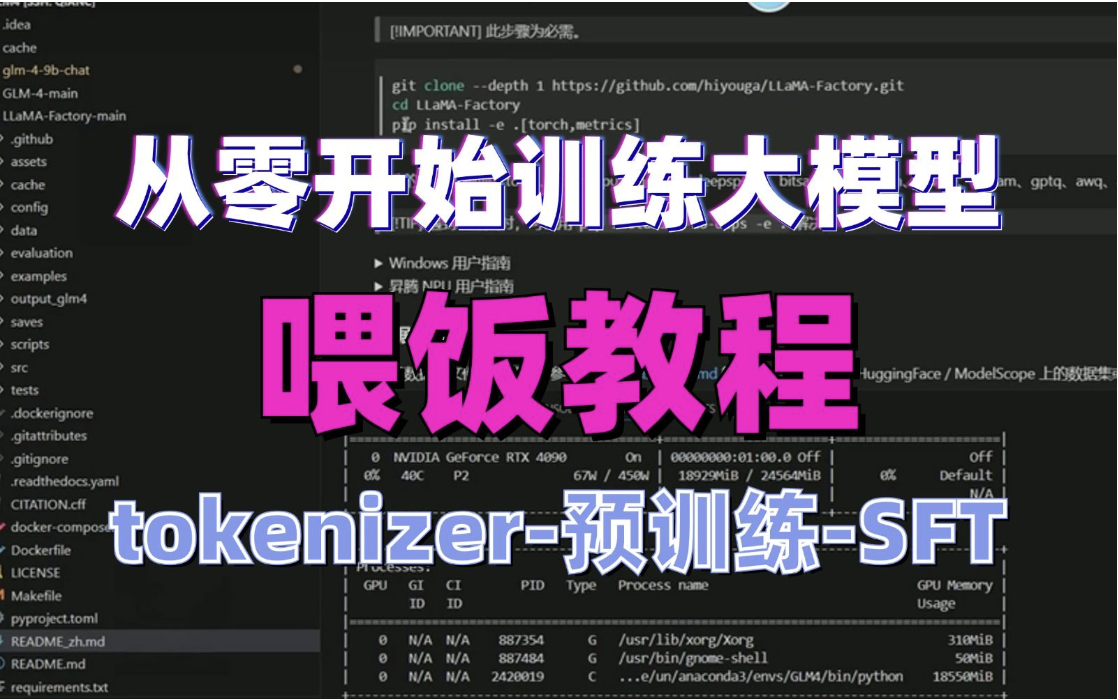
大模型的训练包括六个主要步骤:1. 数据收集与预处理:从多种来源收集数据并进行清洗、标注和分词;2. 模型架构选择:根据任务选择如Transformer等架构;3. 超参数设置:调整学习率、批次大小和模型复杂度;4. 训练过程:通过初始化、传播和优化参数进行训练;5. 模型评估与优化:使用评估指标衡量性能并进行优化;6. 模型部署与应用:将模型用于实际任务并考虑性能等问题。
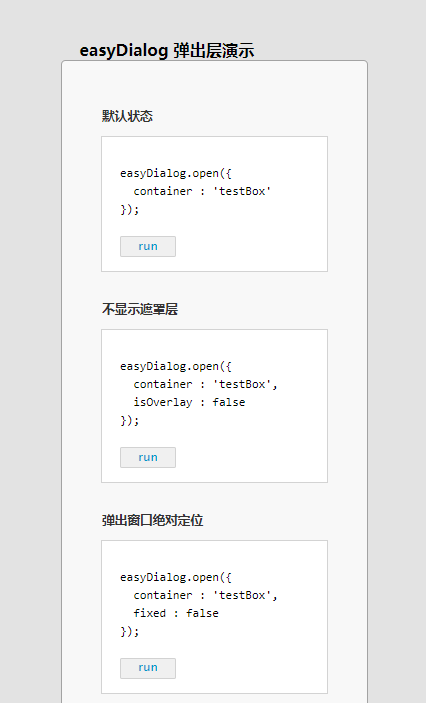
easyDialog没有模板机制,只负责逻辑层的弹出效果,至于内容(消息框、表单、图片等)该如何呈现,easyDialog都不管,内容属于业务层的东西,业务需求是千变万化的,如果逻辑和业务结合很紧密,那么可移植性和可扩展性将大大降低。
 25
25

以上就是大模型是如何训练的的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 124
124






















