
在前面的文章中,我们已经探讨了从单机到集群,从windows到linux的各种环境设置,但还没有涉及到单机多卡的问题。本文将详细介绍在单机多卡环境中遇到的问题和解决方法。
本次使用的环境是配备4张Tesla V100显卡的系统。
1.只能使用1张卡
我们使用官方脚本安装了ollama,并通过systemctl方式启动,使用的是deepseek-r1:32b模型。启动后发现只使用了22G的显存,实际上只使用了一张卡,其他卡未被利用。
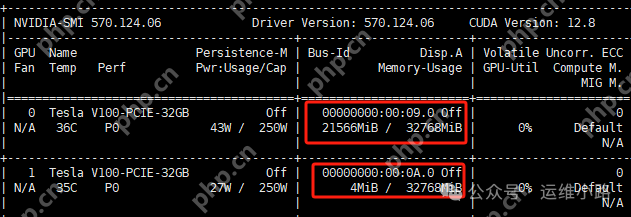 要使用4张卡,需要调整配置,或者运行更大的模型。如果模型大小超过了单张卡的GPU显存限制,系统会自动将任务分配到所有显卡上,无需进行特殊配置。
要使用4张卡,需要调整配置,或者运行更大的模型。如果模型大小超过了单张卡的GPU显存限制,系统会自动将任务分配到所有显卡上,无需进行特殊配置。
vi /etc/systemd/system/ollama.service #增加下面2个参数 Environment="CUDA_VISIBLE_DEVICES=0,1,2,3" Environment="OLLAMA_SCHED_SPREAD=1" #重新加载ollama systemctl daemon-reload systemctl restart ollama #然后重启模型 ollama run deepseek-r1:32b
 2.模型自动退出
2.模型自动退出
模型启动后,如果自动退出(默认时间为5分钟),但当你提问时,模型会自动重新启动(这会导致响应速度降低)。

系统开发由二当家的编写,代码完全开源,可自行修改源码,欢迎使用! 1、网站采用php语言开发,更安全、稳定、无漏洞、防注入、防丢单。 2、记录订单来路,客户IP记录及分析,订单数据统计 3、订单邮件提醒、手机短信提醒,让您第一时间追踪订单,大大提升了发货效率,提高订单成交率。 4、多种支付方式,包含:货到付款、支付宝接口、网银支付,可设置在线支付的折扣比率。 5、模板样式多样化,一个订单放到多个网
 0
0

#日志中可能会出现类似以下的记录 "new model will fit in available VRAM, loading" model=/usr/share/ollama/.ollama/models/blobs/sha256-4cd576d9aa16961244012223abf01445567b061f1814b57dfef699e4cf8df339 library=cuda parallel=4 required="49.9 GiB"
#设置为-1则永不退出,也可以设置其他具体时间,比如1小时 #参考刚才的步骤,重启服务即可常驻 Environment="OLLAMA_KEEP_ALIVE=-1"
3.单机运行多模型
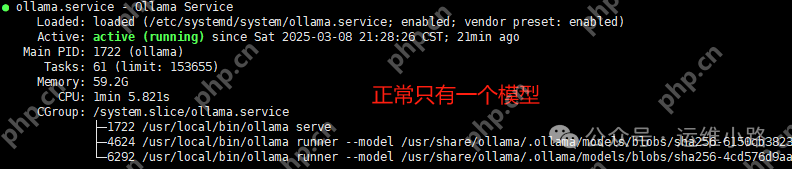
在机器上下载了多个模型后,运行其中一个模型后,再启动另一个模型。
root@localhost:~# ollama ls NAME ID SIZE MODIFIED deepseek-r1:32b 38056bbcbb2d 19 GB 3 hours ago deepseek-r1:32b-qwen-distill-fp16 141ef25faf00 65 GB 19 hours ago deepseek-r1:70b 0c1615a8ca32 42 GB 20 hours ago
 4.Open WebUI 提问拉起模型
4.Open WebUI 提问拉起模型
在部署ollama后,它会自动开机启动;随后部署了容器化的Open WebUI(也配置了开机自启动)。重启机器(模型未启动)后,通过Open WebUI访问模型并提问,模型会自动启动,并在启动完成后自动回答问题(需要等待模型启动的时间)。
以上就是DeepSeek-单机多卡折腾记的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号






 153
153





















