
ras(三)intel mca-cmci
修正的机器检查错误中断(CMCI)是MCA的一个增强特性,它提供了一种基于阈值的错误报告方式。通过这种模式,软件可以配置硬件校正MC错误的阈值,当硬件发生的CE(校正错误)次数达到设定阈值时,会产生一个中断通知软件处理。
需要注意的是,CMCI是随MCA引入的特性,最初只能通过软件轮询方式获取CE信息。CMCI中断通知方式的优势在于,每个CE都将通过IRQ处理,不会丢失任何CE;而轮询方式则可能因轮询频率低、存储空间有限等原因导致CE丢失。然而,CMCI并非总是最佳选择,其缺点在于大量的CE可能引发中断风暴,影响机器性能。在云服务器场景中,CE风暴较为常见,那么Intel服务器是如何解决这一问题的呢?下文将详细说明。
CMCI机制
CMCI默认是关闭的,软件需要通过配置IA32_MCG_CAP[10] = 1来启用。
软件通过IA32_MCi_CTL2 MSR来控制对应Bank的CMCI功能的启用或关闭。
通过IA32_MCi_CTL2 Bit 14:0设置阈值,如果设置非0,则使用配置的阈值;如果CMCI不支持,则全0;
CMCI机制如下图所示:
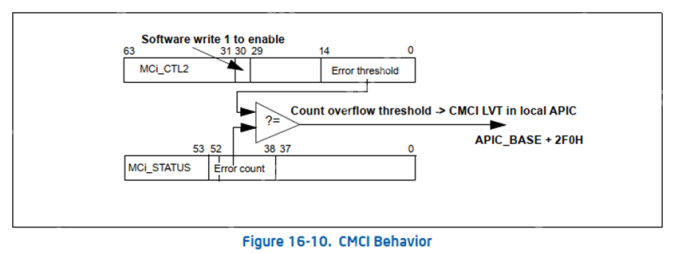 硬件通过比较IA32_MCi_CTL2 Bit 14:0和IA32_MCi_STATUS Bit 52:38,如果数值相等,则溢出事件发送到APIC的CMCI LVT条目。如果MC错误涉及多个处理器,那么CMCI中断会同时发送到这些处理器,例如两个CPU共享的缓存发生CE,这两个CPU都会收到CMCI。
硬件通过比较IA32_MCi_CTL2 Bit 14:0和IA32_MCi_STATUS Bit 52:38,如果数值相等,则溢出事件发送到APIC的CMCI LVT条目。如果MC错误涉及多个处理器,那么CMCI中断会同时发送到这些处理器,例如两个CPU共享的缓存发生CE,这两个CPU都会收到CMCI。
CMCI初始化
以Linux v6.3分支为例,内核启用CMCI的代码如下:
arch/x86/kernel/cpu/mce/intel.c
void intel_init_cmci(void)
{
int banks;
if (!cmci_supported(&banks))
return;
mce_threshold_vector = intel_threshold_interrupt;
cmci_discover(banks);
/*
* For CPU #0 this runs with still disabled APIC, but that's
* ok because only the vector is set up. We still do another
* check for the banks later for CPU #0 just to make sure
* to not miss any events.
*/
apic_write(APIC_LVTCMCI, THRESHOLD_APIC_VECTOR|APIC_DM_FIXED);
cmci_recheck();
}cmci_supported()函数的主要任务包括:
mce_threshold_vector = intel_threshold_interrupt; 声明cmci的中断处理函数为intel_threshold_interrupt();
cmci_discover()函数的主要功能是:
rdmsrl(MSR_IA32_MCx_CTL2(i), val); ... val |= MCI_CTL2_CMCI_EN; wrmsrl(MSR_IA32_MCx_CTL2(i), val); rdmsrl(MSR_IA32_MCx_CTL2(i), val);
#define CMCI_THRESHOLD 1
if (!mca_cfg.bios_cmci_threshold) {
val &= ~MCI_CTL2_CMCI_THRESHOLD_MASK;
val |= CMCI_THRESHOLD;
} else if (!(val & MCI_CTL2_CMCI_THRESHOLD_MASK)) {
/*
* If bios_cmci_threshold boot option was specified
* but the threshold is zero, we'll try to initialize
* it to 1.
*/
bios_zero_thresh = 1;
val |= CMCI_THRESHOLD;
}如果用户未通过启动参数"mce=bios_cmci_threshold"配置值,则val = CMCI_THRESHOLD,为1;
如果启动参数"mce=bios_cmci_threshold"配置,那么表示bios已配置阈值,即val & MCI_CTL2_CMCI_THRESHOLD_MASK不为0,跳过else if判断,采用bios配置值;如果bios未配置值,val & MCI_CTL2_CMCI_THRESHOLD_MASK为0,那么驱动将阈值初始化为1。
cmci_recheck()
cmci_recheck函数通过调用machine_check_poll(),检查CPU #0是否有遗漏的CE&UCE事件。
CMCI处理
cmci中断处理函数为intel_threshold_interrupt(),定义在arch/x86/kernel/cpu/mce/intel.c:
/*
* The interrupt handler. This is called on every event.
* Just call the poller directly to log any events.
* This could in theory increase the threshold under high load,
* but doesn't for now.
*/
static void intel_threshold_interrupt(void)
{
if (cmci_storm_detect())
return;
machine_check_poll(MCP_TIMESTAMP, this_cpu_ptr(&mce_banks_owned));
}static bool cmci_storm_detect(void)
{
unsigned int cnt = __this_cpu_read(cmci_storm_cnt);
unsigned long ts = __this_cpu_read(cmci_time_stamp);
unsigned long now = jiffies;
int r;
if (__this_cpu_read(cmci_storm_state) != CMCI_STORM_NONE)
return true;
if (time_before_eq(now, ts + CMCI_STORM_INTERVAL)) {
cnt++;
} else {
cnt = 1;
__this_cpu_write(cmci_time_stamp, now);
}
__this_cpu_write(cmci_storm_cnt, cnt);
if (cnt >= CMCI_STORM_THRESHOLD) {
cmci_toggle_interrupt_mode();
return true;
}
return false;
}该函数通过jiffies,判断固定时间内发生的cmci次数是否大于CMCI_STORM_THRESHOLD(15),如果不是则返回,否则说明发生了cmci风暴,则执行cmci_toggle_interrupt_mode()关闭cmci功能,切换为轮询模式,通过轮询方式获取事件;
在非cmci风暴情况下,通过machine_check_poll(MCP_TIMESTAMP, this_cpu_ptr(&mce_banks_owned))函数获取并记录故障信息。
参数1定义如下,MCP_TIMESTAMP表示会记录当前TSC:
enum mcp_flags {
MCP_TIMESTAMP = BIT(0), /* log time stamp */
MCP_UC = BIT(1), /* log uncorrected errors */
MCP_DONTLOG = BIT(2), /* only clear, don't log */
};machine_check_poll函数的主要功能是通过读取IA32_MCG_STATUS、IA32_MCi_STATUS寄存器信息和CPU的ip、cs等相关信息,然后对故障进行分类,将CE事件或其他类型的故障事件记录到/dev/mcelog。用户可以通过读取/dev/mcelog获取错误记录。
执行流程如下,过程说明在代码注释中:
bool machine_check_poll(enum mcp_flags flags, mce_banks_t *b)
{
if (flags & MCP_TIMESTAMP)
m.tsc = rdtsc(); // 记录当前TSC
/* CE Error记录 */
/* If this entry is not valid, ignore it */
if (!(m.status & MCI_STATUS_VAL))
continue;
/*
* If we are logging everything (at CPU online) or this
* is a corrected error, then we must log it.
*/
if ((flags & MCP_UC) || !(m.status & MCI_STATUS_UC))
goto log_it;
/* UCNA Error记录 */
/*
* Log UCNA (SDM: 15.6.3 "UCR Error Classification")
* UC == 1 && PCC == 0 && S == 0
*/
if (!(m.status & MCI_STATUS_PCC) && !(m.status & MCI_STATUS_S))
goto log_it;
/* 通过mce_log记录故障信息 */
log_it:
/*
* Don't get the IP here because it's unlikely to
* have anything to do with the actual error location.
*/
if (!(flags & MCP_DONTLOG) && !mca_cfg.dont_log_ce)
mce_log(&m);
else if (mce_usable_address(&m)) {
/*
* Although we skipped logging this, we still want
* to take action. Add to the pool so the registered
* notifiers will see it.
*/
if (!mce_gen_pool_add(&m))
mce_schedule_work();
}
}总结一下,CMCI是MCA的一个增强特性,主要用于将硬件CE、UCNA等类型故障通过中断方式报告给软件,软件收到中断后,执行中断处理函数intel_threshold_interrupt(),采取IRQ模式或轮询模式记录错误信息到/dev/mcelog,用户态可以通过/dev/mcelog获取硬件故障信息。
参考文档:《Intel® 64 and IA-32 Architectures Software Developer’s Manual》
以上就是RAS(三)Intel MCA-CMCI的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 575
575























