
作者 | casey muratori、译者 | 弯月
责编 | 苏宓、出品 | CSDN(ID:CSDNnews)
编写“整洁”的代码,这是一条反复被人提及的编程建议,尤其是初学者,听得太多耳朵都长茧了。“整洁”的代码背后是一长串规则,告诉你应该怎么书写,代码才能保持“整洁”。
实际上,这些规则中很大的一部分并不会影响代码的运行时间。我们无法客观评估这些类型的规则,而且也没必要进行这样的评估。然而,一些所谓的“整洁”代码规则(其中有一部分甚至被反复强调)是可以客观衡量的,因为它们确实会影响代码的运行时行为。
整理和归纳“整洁”的代码规则,并提取实际影响代码结构的规则,我们将得到:
使用多态代替“if/else”和“switch”;代码不应该知道使用对象的内部结构;严格控制函数的规模;函数应该只做一件事;“DRY”(Don’t Repeat Yourself):不要重复自己。这些规则非常具体地说明了为了保持代码“整洁”,我们应该如何书写特定的代码片段。然而,我的疑问在于,如果创建一段遵循这些规则的代码,它的性能如何?
为了构建我认为严格遵守“整洁之道”的代码,我使用了“整洁”代码相关文章中包含的现有示例。也就是说,这些代码不是我编写的,我只是利用他们提供的示例代码来评估“整洁”代码倡导的规则。
那些年我们见过的“整洁”代码
提起“整洁”代码的示例,你经常会看到下面这样的代码:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 22 ======================================================================== */class shape_base{public: shape_base() {} virtual f32 Area() = 0;};class square : public shape_base{public: square(f32 SideInit) : Side(SideInit) {} virtual f32 Area() {return Side*Side;}private: f32 Side;};class rectangle : public shape_base{public: rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {} virtual f32 Area() {return Width*Height;}private: f32 Width, Height;};class triangle : public shape_base{public: triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {} virtual f32 Area() {return 0.5f*Base*Height;}private: f32 Base, Height;};class circle : public shape_base{public: circle(f32 RadiusInit) : Radius(RadiusInit) {} virtual f32 Area() {return Pi32*Radius*Radius;}private: f32 Radius;};</code>这段代码是一个形状的基类,从中派生出了一些特定的形状:圆形、三角形、矩形、正方形。此外,还有一个计算面积的虚函数。
就像规则要求的一样,我们倾向于多态性,函数只做一件事,而且很小。最终,我们得到了一个“整洁”的类层次结构,每个派生类都知道如何计算自己的面积,并存储了计算面积所需的数据。
如果我们想象使用这个层次结构来做某事,比如计算一系列形状的总面积,那么我们希望看到下面这样的代码:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 23 ======================================================================== */f32 TotalAreaVTBL(u32 ShapeCount, shape_base **Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += Shapes[ShapeIndex]->Area(); } return Accum;}</code>你可能会发现,此处我没有使用任何迭代,因为“整洁代码之道”中没有建议你必须使用迭代器。因此,我想尽可能避免有损“整洁”代码的写法,我不希望添加任何有可能混淆编译器并导致性能下降的抽象迭代器。
此外,你可能还会注意到,这个循环是在一个指针数组上进行的。这是使用类层次结构的直接结果:我们不知道每种形状占用的内存有多大。所以除非我们添加另一个虚函数调用来获取每个形状的数据大小,并使用某种步长可变的跳跃过程来遍历它们,否则我们需要指针来找出每个形状的实际开始位置。
因为这个计算数一个累加和,所以循环本身引起的依赖可能会导致循环速度减慢。由于计算累加可以以任意顺序进行,为了安全起见,我还写了一个手动展开的版本:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 24 ======================================================================== */f32 TotalAreaVTBL4(u32 ShapeCount, shape_base **Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; u32 Count = ShapeCount/4; while(Count--) { Accum0 += Shapes[0]->Area(); Accum1 += Shapes[1]->Area(); Accum2 += Shapes[2]->Area(); Accum3 += Shapes[3]->Area(); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}</code>在一个简单的测试工具中运行以上这两个例程,可以粗略地计算出执行该操作每个形状所需的循环总数:
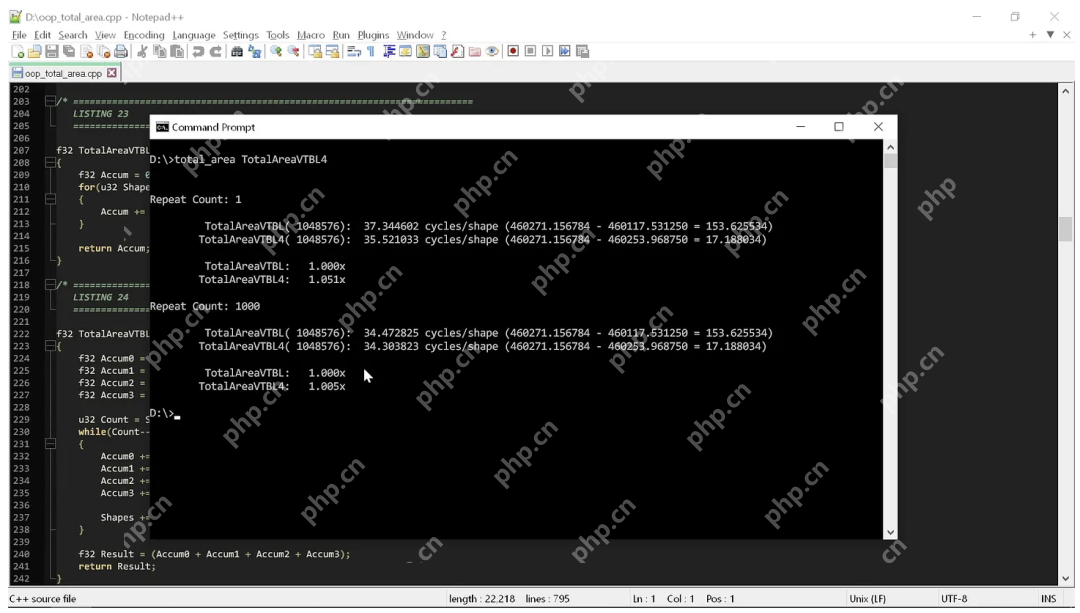
测试工具以两种不同的方式统计代码的时间。第一种方法是只运行一次代码,以显示在没有预热的状态下代码的运行时间(在此状态下,数据应该在 L3 中,但 L2 和 L1 已被刷新,而且分支预测器尚未针对循环进行预测)。
第二种方法是反复运行代码,看看当缓存和分支预测器以最适合循环的方式运行时情况会怎样。请注意,这些都不是严谨的测量,因为正如你所见,我们已经看到了巨大的差异,根本不需要任何严谨的分析工具。
从结果中我们可以看出,这两个例程之间没有太大区别。这段“整洁”的代码计算这个形状的面积大约需要循环35次,如果幸运的话,有可能减少到34次。
所以,我们严格遵守“代码整洁之道”,最后需要循环35次。
我们创建了一个高质量的技术交流群,与优秀的人在一起,自己也会优秀起来,赶紧点击加群,享受一起成长的快乐。另外,如果你最近想跳槽的话,年前我花了2周时间收集了一波大厂面经,节后准备跳槽的可以点击这里领取!
违反“代码整洁之道”的第一条规则后
那么,如果我们违反第一条规则,会怎么样?如果我们不使用多态性,使用一个 switch 语句呢?
下面,我又编写了一段一模一样的代码,只不过这一次我没有使用类层次结构,而是使用枚举,将所有内容扁平化为一个结构的形状类型:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 25 ======================================================================== */enum shape_type : u32{ Shape_Square, Shape_Rectangle, Shape_Triangle, Shape_Circle, Shape_Count,};struct shape_union{ shape_type Type; f32 Width; f32 Height;};f32 GetAreaSwitch(shape_union Shape){ f32 Result = 0.0f; switch(Shape.Type) { case Shape_Square: {Result = Shape.Width*Shape.Width;} break; case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break; case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break; case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break; case Shape_Count: {} break; } return Result;}</code>这是代码整洁之道出现以前,很常见的“老派”写法。
请注意,由于我们没有为每个形状提供特定的数据类型,所以如果某个类型缺乏其中一个值(比如“高度”),计算就不使用了。
现在,这个结构的用户获取面积不再需要调用虚函数,而是需要使用带有 switch 语句的函数,这违反了“代码整洁之道”。即便如此,你会注意到代码更加简洁了,但功能基本相同。switch 语句的每一个 case 的都对应于类层次结构中的一个虚函数。
对于求和循环本身,你可以看到这段代码与上述“整洁”版几乎相同:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 26 ======================================================================== */f32 TotalAreaSwitch(u32 ShapeCount, shape_union *Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += GetAreaSwitch(Shapes[ShapeIndex]); } return Accum;}f32 TotalAreaSwitch4(u32 ShapeCount, shape_union *Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; ShapeCount /= 4; while(ShapeCount--) { Accum0 += GetAreaSwitch(Shapes[0]); Accum1 += GetAreaSwitch(Shapes[1]); Accum2 += GetAreaSwitch(Shapes[2]); Accum3 += GetAreaSwitch(Shapes[3]); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}</code>唯一的不同之处在于,我们调用常规函数来获取面积。
但是,我们已经看到了相较于类层次结构,使用扁平结构的直接好处:形状可以存储在数组中,不需要指针。不需要间接访问,因为所有形状占用的内存大小都一样。
另外,我们还获得了额外的好处,现在编译器可以确切地看到我们在这个循环中做了什么,因为它只需查看 GetAreaSwitch 函数。它不必假设只有等到运行时我们才能看得见某些虚拟面积函数具体在做什么。
那么,编译器能利用这些好处为我们做什么呢?下面,我们来完整地运行一遍四个形状的面积计算,得到的结果如下:
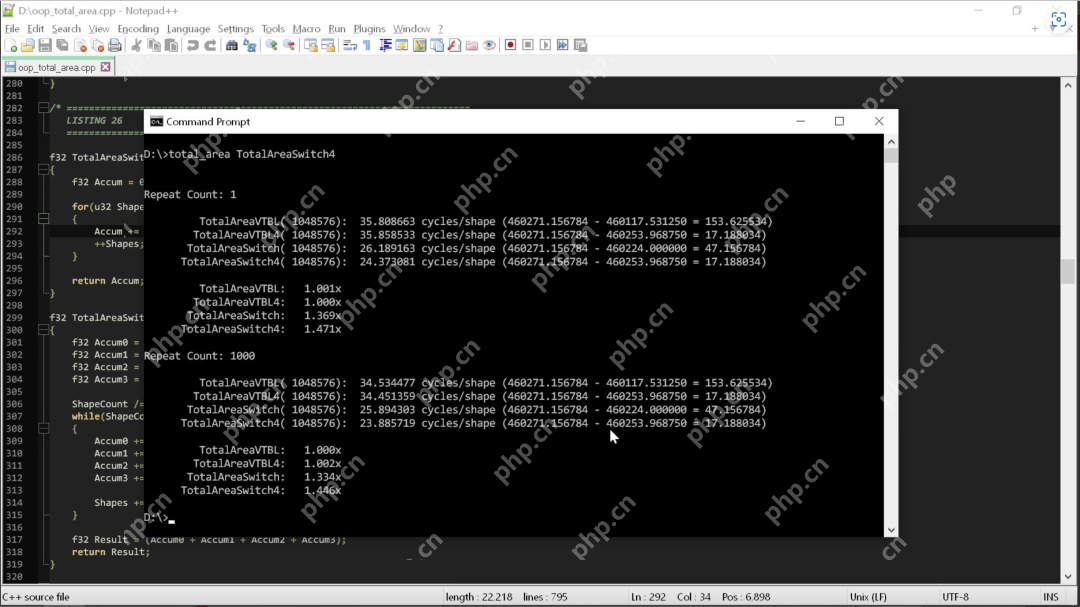
观察结果,我们可以看出,改用“老派””的写法后,代码的性能立即提高了 1.5 倍。我们什么都没干,只是删除了使用 C++ 多态性的代码,就收获了1.5倍的性能提升。
违反代码整洁之道的第一条规则(也是核心原则之一),计算每个面积的循环数量就从35次减少到了24次,这意味着,遵循代码整洁之道会导致代码的速度降低1.5倍。拿手机打个比方,就相当于把 iPhone 14 Pro Max 换成了 iPhone 11 Pro Max。过去三四年间硬件的发展瞬间化无,仅仅是因为有人说要使用多态性,不要使用 switch 语句。
然而,这只是一个开头。
违反“代码整洁之道”的更多条规则后
如果我们违反更多规则,结果会怎么样?如果我们打破第二条规则,“没有内部知识”,结果会如何?如果我们的函数可以利用自身实际操作的知识来提高效率呢?
回顾一下计算面积的 switch 语句,你会发现所有面积的计算方式都很相似:
代码语言:javascript代码运行次数:0运行复制<code class="javascript"> case Shape_Square: {Result = Shape.Width*Shape.Width;} break; case Shape_Rectangle: {Result = Shape.Width*Shape.Height;} break; case Shape_Triangle: {Result = 0.5f*Shape.Width*Shape.Height;} break; case Shape_Circle: {Result = Pi32*Shape.Width*Shape.Width;} break;</code>所有形状的面积计算都是做乘法,长乘以宽、宽乘以高,或者乘以 π 的系数等等。只不过,三角形的面积需要乘以1/2,而圆的面积需要乘以 π。
这是我认为此处使用 switch 语句非常合适的原因之一,尽管这与代码整洁之道背道而驰。透过 switch 语句,我们可以很清楚地看到这种模式。当你按照操作而不是类型组织代码时,观察和提取通用模式就很简单。相比之下,观察类版本,你可能永远也发现不了这种模式,因为类版本不仅有很多样板代码,而且你需要将每个类放在一个单独的文件中,无法并排比较。
所以,从架构的角度来看,我一般都不赞成类层次结构,但这不是重点。我想说的是,我们可以通过上述发现的模式大大简化 switch 语句。
请记住:这不是我选择的示例,这可是整洁代码倡导者用于说明的示例。所以,我并没有刻意选择一个恰巧能够抽出一个模式的例子,因此这种现象应该比较普遍,因为大多数相似类型都有类似的算法结构,就像这个例子一样。
为了利用这种模式,首先我们可以引入一个简单的表,说明每种类型的面积计算需要使用哪个系数。其次,对于圆和正方形之类只需要一个参数(圆的参数为半径,正方形的参数为边长)的形状,我们可以认为它们的长和宽恰巧相同,这样我们就可以创建一个非常简单的计算面积的函数:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 27 ======================================================================== */f32 const CTable[Shape_Count] = {1.0f, 1.0f, 0.5f, Pi32};f32 GetAreaUnion(shape_union Shape){ f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height; return Result;}</code>这个版本的两个求和循环完全相同,无需修改,我们只需要将 GetAreaSwitch 换成 GetAreaUnion,其他代码保持不变。
下面,我们来看看使用这个新版本的效果:

我们可以看到,从基于类型的思维模式切换到基于函数的思维模式,我们获得了巨大的速度提升。从 switch 语句(相较于整洁代码版本性能已经提升了 1.5 倍)换成表驱动的版本,速度全面提升了 10 倍。
我们只是添加了一个表查找和一行代码,仅此而已!现在不仅代码的运行速度大幅提升,而且语义的复杂性也显著降低。标记更少、操作更少、代码更少。
将数据模型与所需的操作融合到一起后,计算每个面积的循环数量减少到了 3.0~3.5 次。与遵循代码整洁之道前两条规则的代码相比,这个版本的速度提高了 10 倍。
10 倍的性能提升非常巨大,我甚至无法拿 iPhone 做类比,即便是 iPhone 6(现代基准测试中最古老的手机)也只比最新的iPhone 14 Pro Max 慢 3 倍左右。
如果是线程桌面性能,10 倍的速度提升就相当于如今的 CPU 退回到2010年。代码整洁之道的前两条规则抹杀了 12 年的硬件发展。
然而,这个测试只是一个非常简单的操作。我们还没有探讨“函数应该只做一件事”以及“尽可能保持小”。如果我们调整一下问题,全面遵循这些规则,结果会怎么样?
下面这段代码的层次结构完全相同,但这次我添加了一个虚函数,用于获取每个形状的角的个数:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 32 ======================================================================== */class shape_base{public: shape_base() {} virtual f32 Area() = 0; virtual u32 CornerCount() = 0;};class square : public shape_base{public: square(f32 SideInit) : Side(SideInit) {} virtual f32 Area() {return Side*Side;} virtual u32 CornerCount() {return 4;}private: f32 Side;};class rectangle : public shape_base{public: rectangle(f32 WidthInit, f32 HeightInit) : Width(WidthInit), Height(HeightInit) {} virtual f32 Area() {return Width*Height;} virtual u32 CornerCount() {return 4;}private: f32 Width, Height;};class triangle : public shape_base{public: triangle(f32 BaseInit, f32 HeightInit) : Base(BaseInit), Height(HeightInit) {} virtual f32 Area() {return 0.5f*Base*Height;} virtual u32 CornerCount() {return 3;}private: f32 Base, Height;};class circle : public shape_base{public: circle(f32 RadiusInit) : Radius(RadiusInit) {} virtual f32 Area() {return Pi32*Radius*Radius;} virtual u32 CornerCount() {return 0;}private: f32 Radius;};</code>长方形有4个角,三角形有3个,圆为0。接下来,我们来修改问题的定义,原来的问题是计算一系列形状的面积之和,我们改为计算角加权的面积总和:总面积之和乘以角的数量。当然,这只是一个例子,实际工作中不会遇到。
下面,我们来更新“整洁”的求和循环,我们需要添加必要的数学运算,还需要多调用一次虚函数:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">f32 CornerAreaVTBL(u32 ShapeCount, shape_base **Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += (1.0f / (1.0f + (f32)Shapes[ShapeIndex]->CornerCount())) * Shapes[ShapeIndex]->Area(); } return Accum;}f32 CornerAreaVTBL4(u32 ShapeCount, shape_base **Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; u32 Count = ShapeCount/4; while(Count--) { Accum0 += (1.0f / (1.0f + (f32)Shapes[0]->CornerCount())) * Shapes[0]->Area(); Accum1 += (1.0f / (1.0f + (f32)Shapes[1]->CornerCount())) * Shapes[1]->Area(); Accum2 += (1.0f / (1.0f + (f32)Shapes[2]->CornerCount())) * Shapes[2]->Area(); Accum3 += (1.0f / (1.0f + (f32)Shapes[3]->CornerCount())) * Shapes[3]->Area(); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}</code>其实,我应该单独写一个函数,添加另一层间接。为了保证对“整洁”代码采取疑罪从无的原则,我明确保留了这些代码。
switch 语句的版本也需要相同的修改。首先,我们再添加一个 switch 语句来处理角的数量,case 语句与层次结构版本完全相同:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 34 ======================================================================== */u32 GetCornerCountSwitch(shape_type Type){ u32 Result = 0; switch(Type) { case Shape_Square: {Result = 4;} break; case Shape_Rectangle: {Result = 4;} break; case Shape_Triangle: {Result = 3;} break; case Shape_Circle: {Result = 0;} break; case Shape_Count: {} break; } return Result;}</code>接下来,我们按照相同的方式计算面积:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 35 ======================================================================== */f32 CornerAreaSwitch(u32 ShapeCount, shape_union *Shapes){ f32 Accum = 0.0f; for(u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) { Accum += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[ShapeIndex].Type))) * GetAreaSwitch(Shapes[ShapeIndex]); } return Accum;}f32 CornerAreaSwitch4(u32 ShapeCount, shape_union *Shapes){ f32 Accum0 = 0.0f; f32 Accum1 = 0.0f; f32 Accum2 = 0.0f; f32 Accum3 = 0.0f; ShapeCount /= 4; while(ShapeCount--) { Accum0 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[0].Type))) * GetAreaSwitch(Shapes[0]); Accum1 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[1].Type))) * GetAreaSwitch(Shapes[1]); Accum2 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[2].Type))) * GetAreaSwitch(Shapes[2]); Accum3 += (1.0f / (1.0f + (f32)GetCornerCountSwitch(Shapes[3].Type))) * GetAreaSwitch(Shapes[3]); Shapes += 4; } f32 Result = (Accum0 + Accum1 + Accum2 + Accum3); return Result;}</code>与直接求面积总和的版本相同,类层次结构与 switch 语句的实现代码几乎相同。唯一的区别是,调用虚函数还是使用 switch 语句。
下面再来看看表驱动的写法,你可以看到将操作和数据融合在一起的效果有多棒。与所有其他版本不同,在这个版本中,唯一需要修改的只有表中的值。我们并不需要获取形状的次要信息,我们可以将角的个数和面积系数直接放入表中,而代码保持不变:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">/* ======================================================================== LISTING 36 ======================================================================== */f32 const CTable[Shape_Count] = {1.0f / (1.0f + 4.0f), 1.0f / (1.0f + 4.0f), 0.5f / (1.0f + 3.0f), Pi32};f32 GetCornerAreaUnion(shape_union Shape){ f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height; return Result;}</code>运行上述所有“角加权面积”函数,我们可以看到它们的性能受第二个形状属性的影响程度:
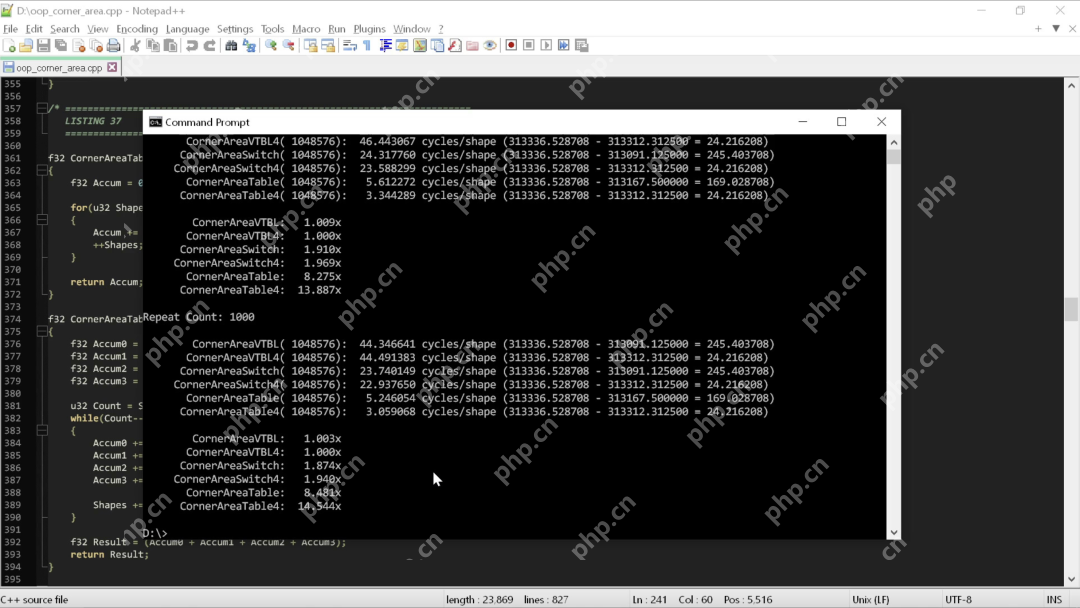
如你所见,“整洁”代码的性能更糟糕。在直接计算面积时,switch 语句版本的速度快了 1.5 倍,而如今快了将近2倍,而查找表版本快了近 15 倍。
这说明“整洁”的代码存在更深层次的问题:问题越复杂,代码整洁之道对性能的损害就越大。当你尝试将代码整洁之道扩展到具有许多属性的对象时,代码的性能普遍会遭受损失。
使用代码整洁之道的次数越多,编译器就越不清楚你在干什么。一切都在单独的翻译单元中,在虚函数调用的后面。无论编译器多么聪明,都无法优化这种代码。
更糟糕的是,你无法使用此类代码处理复杂的逻辑。如上所述,如果你的代码库围绕函数而建,那么一些简单的功能(例如将值提取到表中和删除 switch 语句)很容易实现。但是,如果围绕类型而建,那么实际就会困难得多,若非大量重写,甚至可能无法实现。
我们只是添加了一个属性,速度差异就从 10 倍增至 15 倍。这就像 2023 年的硬件退步到了 2008 年。
然而,也许你已经注意到了,我甚至没有提到优化。除了保证不产生循环带来的依赖之外,出于测试的目的,我没有做任何优化!
如果我使用一个略微优化过的 AVX 版本运行这些例程,得到的结果如下:
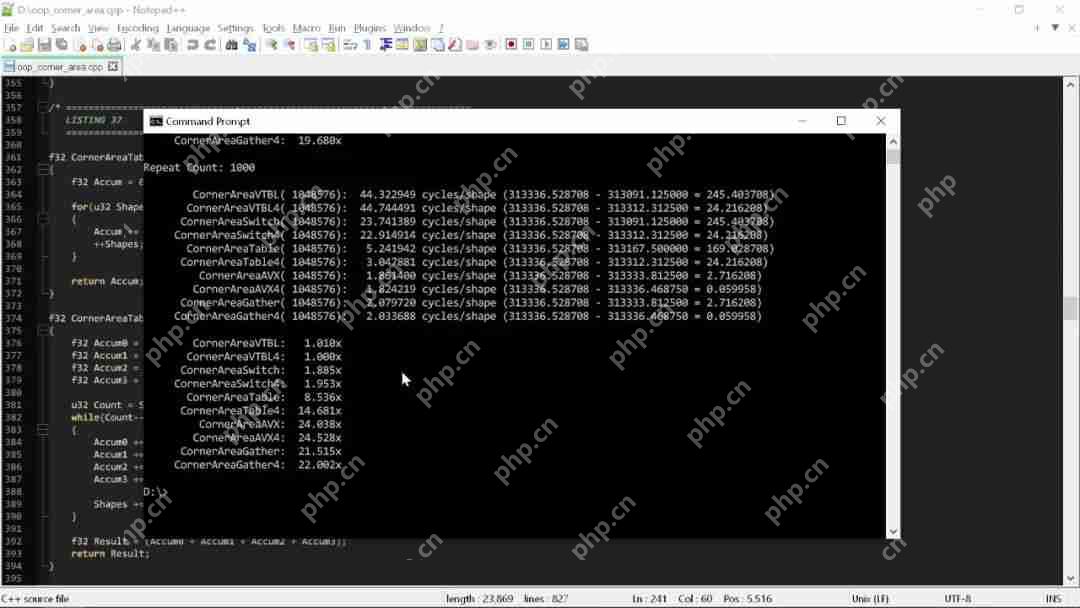
速度差异在 20~25 倍之间,当然,没有任何 AVX 优化的代码使用了类似于代码整洁之道的原则。
以上就是代码越“整洁”,性能越“拉胯”?的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 873
873























